By: Ben Richardson | Updated: 2019-03-12 | Comments (5) | Related: > SQL Server 2017
Problem
In 2017, SQL Server introduced support for Python language which opened the door for creating machine learning models using SQL Server. The SQL Server machine learning services along with Python support can be used to create a model that is capable of prediction.
In this tip, we will examine a dataset that contains information about variance, skewness, curtosis, and entropy of 1372 bank currency notes. The bank currency notes have been divided into two categories: fake or real. The task is to create a machine learning model using SQL Server which is trained on the banknote dataset and is able to predict if an unknown bank currency note is real or fake.
Solution
In this article, we will see how to develop a machine learning model that is capable of detecting a fake currency note. To do so, we need to follow the steps below.
Installing SQL Server With Machine Learning Services
Before you can execute Python scripts and perform machine learning tasks on SQL Server, you need to download a SQL Server instance with machine learning services enabled. The article explains the process of installing SQL Server with machine learning services enabled.
Enabling SQL Server Machine Learning Services
To enable the machine learning services, go to SQL Server Management Studio. If you have not already installed SQL Server Management Studio, you can download it from this link.
In the SQL Server Management Studio, open a new query window and type the following script:
EXEC sp_configure 'external scripts enabled', 1 RECONFIGURE WITH OVERRIDE
The script above enables execution of any external scripts in SQL Server. If the above script executes successfully, you should see the following message.
Configuration option 'external scripts enabled' changed from 0 to 1. Run the RECONFIGURE statement to install.
Before the Python scripts can be executed, we need to restart the SQL Server. To do so, open the SQL Server Configuration Manager from the windows start menu. From the options on the left, select "SQL Server Services". You will see list of all the SQL Server Instances, running on your system as shown below. Right click the SQL Server instance that you installed along with machine learning services and click "Restart".

Testing Python Scripts
Execute the following script:
EXEC sp_execute_external_script @language = N'Python', @script = N'print("Welcome to Python in SQL Server")' GO
You should see the following in the output
STDOUT message(s) from external script: Welcome to Python in SQL Server
Now you have everything that you need to execute machine learning services in SQL Server 2017.
Getting the Machine Learning Dataset
The dataset for the current problem can be downloaded from the UCI Machine Learning Repository. The dataset is originally in text format and you can download a CSV version from this GitHub Link. This dataset contains data that were extracted from images taken from genuine and forged banknote-like specimens. The dataset includes the following columns: variance, skewness, curtosis, entropy and class.
Next, create database and a table inside your SQL Server 2017 instance by executing the following command.
CREATE DATABASE BANK GO USE BANK GO CREATE TABLE [dbo].[banknote]( [variance] [real] NULL, [skewness] [real] NULL, [curtosis] [real] NULL, [entropy] [real] NULL, [class] [real] NULL ) ON [PRIMARY] GO
Next, import the CSV file that you downloaded into the table named "banknote" in the BANK database.
Once the CSV file has been loaded into the "banknote" table, let’s execute a simple SELECT statement to see how the dataset looks:
SELECT * FROM banknote
Screenshot of the output looks like the image below. Our task is to predict the class of the currency note, depending upon the variance, skewness, curtosis, and entropy of the banknote.

Dividing Data into Training and Test Set for Machine Learning
A machine learning algorithm is trained on one portion of data, called a training set and is evaluated on another portion of data called the test set. We will train and test our algorithm on 90% training data and 10% test data. To divide the data into training and test sets, execute the following script:
SELECT TOP 10 PERCENT * INTO banknote_test FROM banknote SELECT * INTO banknote_train FROM banknote EXCEPT SELECT TOP 10 PERCENT * FROM banknote
In the script above, we split our "banknote" table into two tables: "banknote_test" which contains 10% of the data and "banknote_train" which contains 90% of the data.
Creating a Table to Store Models
Next, we need to define the table that will contain our trained model. Execute the following script:
DROP TABLE IF EXISTS banknote_models;
GO
CREATE TABLE banknote_models (
model_name VARCHAR(50) NOT NULL DEFAULT('default model') PRIMARY KEY,
model VARBINARY(MAX) NOT NULL
);
GO
The script above will create the "banknote_models" table in the "BANK" database. The script will delete any existing table with the same name. Remember, our model will be stored in the model attribute and the type of model will be varbinary(MAX).
Create Stored Procedure for Training the Model
The next step is to create a stored procedure that will train the model on training data. Execute the following script:
CREATE PROCEDURE create_banknote_model (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier() trained_model = pickle.dumps(clf.fit(banknote_train[[0,1,2,3]], banknote_train[[4]].values.ravel())) ' , @input_data_1 = N'select "variance", "skewness", "curtosis", "entropy", "class" from banknote_train' , @input_data_1_name = N'banknote_train' , @params = N'@trained_model varbinary(max) OUTPUT' , @trained_model = @trained_model OUTPUT; END; GO
Take a careful look at the script above. In the script above we create "create_bank_note" stored procedure which accepts one parameter of type varbinary (max). Inside the script, we execute Python script. We use RandomForestClassifier from the sklearn.ensemble library to train our model. To train the model we need to call the fit method of the RandomForestClassifier and pass it both the attributes and the output class. Since in our dataset column 0-3 contains features, we pass these columns in place of feature and column 4 contains the output class, we pass it as the class to predict. Finally, we specify the columns and the dataset that we are going to use to train our model.
Once, you create the above stored procedure, you need to execute the stored procedure using the following command:
DECLARE @model varbinary(max); DECLARE @new_model_name varchar(50) SET @new_model_name = 'Random Forest' EXEC create_banknote_model @model OUTPUT; DELETE banknote_models WHERE model_name = @new_model_name; INSERT INTO banknote_models (model_name, model) values(@new_model_name, @model); GO
Creating Stored Procedure for Making Predictions
To make predictions on the test set i.e. "Banknote_test" table, we will again make use of the stored procedure. Execute the following script:
CREATE PROCEDURE predict_banknote_class (@model varchar(100)) AS BEGIN DECLARE @rf_model varbinary(max) = (SELECT model FROM banknote_models WHERE model_name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle banknote_model = pickle.loads(rf_model) note_pred = banknote_model.predict(banknote_test[[1,2,3,4]]) note_actual = banknote_test[''class''].tolist() from sklearn.metrics import accuracy_score accuracy = accuracy_score(note_actual, note_pred) print(accuracy) ' , @input_data_1 = N'select "variance", "skewness", "curtosis", "entropy", "class" from banknote_test' , @input_data_1_name = N'banknote_test' , @params = N'@rf_model varbinary(max)' , @rf_model = @rf_model END; GO
In the script above, we create "predict_banknote_class" stored procedure which predicts the class of the test data in the "banknote_test" table. In the above stored procedure, we first select the trained model that we created using the "create_banknote_mode" stored procedure. This stored procedure will be used for making predictiosn on the test set. Next, we simply define the data that we want our model to make predictions on. Finally, the stored procedure prints the class percentage of correct predictions. The accuracy_score class of the sklearn.metric module is used to calculate the accuracy of the predictions.
Making Predictions with the Machine Learning Stored Procedure
To make actual predictions, we only need to execute the "predict_banknote_class" stored procedure that we created in the last section. We need to pass the name of the algorithm that we want to use for making predictions which is "Random Forest" in our case. Execute the following script:
EXEC predict_banknote_class 'Random Forest'; GO
The output looks like this:
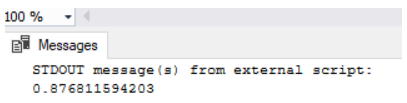
The predicted accuracy is 87.68% which is impressive given the fact that we only had around 1372 records in the dataset.
References
- Machine Learning Terms and Concepts
- Book: Machine Learning with SQL Server 2017 and R
- Statistics Basics (Free Book Download)
Next Steps
- Reduce the training size to 80% and increase the test size to 20% to see if you obtain different results
- Use algorithms other than Random Forest, such as support vector machine, logistic regression, and Naive Bayes to see if you obtain better results.
- Find a regression problem such as House Price prediction and see if SQL Server can help solve regression problems.
- Check out these resources:






About the author
 Ben Richardson is the owner of Acuity Training, a UK based IT training business offering SQL training up to advanced administration courses.
Ben Richardson is the owner of Acuity Training, a UK based IT training business offering SQL training up to advanced administration courses.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-03-12
