By: Tim Smith | Updated: 2019-05-21 | Comments (1) | Related: > PowerShell
Problem
File encoding can cause problems if applications expect or read files encoded in one format and receive a different format and break on an unrecognized character. This can be especially challenging to track in some situations, especially if we are unaware of how our program encodes files when it writes or reads from them. Because this topic can become complex quickly, as many teams work together around the world and software in other parts of the world may encode differently, we'll look at the basics of encoding, both reading and writing with PowerShell, using the most spoken language in the world - Mandarin Chinese. From writing the proper characters to a file to reading the correct characters to the database, we'll look at examples that we can build on if we come across other encoding formats.
Solution
We'll start by creating three files with five Mandarin characters (this will not include the Pinyin for these examples, but they can be conveniently found with Yandex Translate's option of "Show transliteration" for testing encoding Pinyin) with the built-in PowerShell function of Add-Content.
Before calling these three functions that encode files differently, we ensure the path is created, which is C:\files\encoding\ that we'll be using for these examples. According to Microsoft, PowerShell lets us specify encoding for Add-Content with values such as ASCII, BigEndianUnicode, Byte, OEM, String, Unicode, UTF7, UTF8, UTF8BOM, UTF8NoBOM, UTF32, and Unknown. For this example, we're looking at the three of UTF7, UTF8, ASCII and Unicode but I encourage readers to test with other formats.
As we see when we call these functions and review these files, the UTF8 and Unicode return what we expect and want to see and this is important because the other encoding formats may suffice with some data, but not for what we want to see in this example. One of the challenges we may experience (relative to the language or mixed software use) becomes ensuring that we're able to read the data properly encoded, pass the values to the database that can retain these correctly encoded values, and read these values in our application. This tip will not address the latter challenge since this occurs on the application level, though it will follow a similar pattern to how we read and write with PowerShell when passing values into the database or reading them from the database to a file.
### Create our file path
if (!(Test-Path "C:\files\encoding\")) { New-Item -Path "C:\files\encoding\" -ItemType Directory }
### This will create these files
Add-Content "C:\files\encoding\m7.txt" "我是德州人" -Encoding UTF7
Add-Content "C:\files\encoding\m8.txt" "我是德州人" -Encoding UTF8
Add-Content "C:\files\encoding\ma.txt" "我是德州人" -Encoding ASCII
Add-Content "C:\files\encoding\mu.txt" "我是德州人" -Encoding Unicode
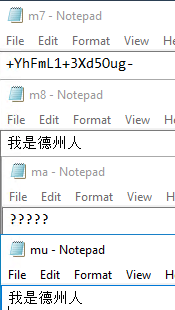
Related to the problem we're solving in this tip with these encoding formats, consider the following with each of these that we're using and the context as it relates to this tip involving cross country work and coordination:
- UTF7: Unicode transformation format using 7 bit which is rarely used, but will be useful for comparison in this tip. This format does come up in parsing files with ETL processes in rare cases and it can be a cause for concern with security due to multiple string interpretations.
- UTF8: The commonly used Unicode transformation format using 8 bit. While we will use Unicode in this tip, UTF8 is a popular encoding format with Mandarin.
- ASCII: As we see in the above image, ASCII does not return Mandarin characters because it represents the American Standard Code for Information Interchange. This is not without its use (strict security contexts may use ASCII only), but it is uncommon in cross country or regional work where languages outside of American English are used.
- Unicode: Unicode involves representing and encoding digital characters for most of the world's text. The first 128 Unicode characters are all ASCII, in contexts where we may need to use more than ASCII, Unicode (or a strict derivative) may be appropriate.
For this context, we see that UTF8 and Unicode are appropriate to use and UTF8 is one of the most common encodings found on the web. We'll use Unicode encoding for our exercises, but we could also use UTF8.
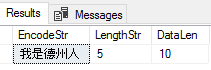
Since NVARCHAR can store Unicode data, in the below T-SQL, we create a table with a NVARCHAR field of 100 characters allowed, declare a NVARCHAR variable that matches the character length and insert it into our table. We query the table and see our Mandarin statement inserted successfully along with obtaining the length of the string and the data length details for confirming what we expect. According to Microsoft, we could use either NCHAR or NVARCHAR data types here - and we use the NVARCHAR. It should be of note that collation can matter with the full range of Unicode characters - for instance, the full range of Unicode character data requires a supplementary character collation (see link). While our focus will mainly involve reading and writing from PowerShell, keep these considerations in mind, as the database development part of this is just as important.
CREATE TABLE Encode( EncodeStr NVARCHAR(100) ) DECLARE @mandarin NVARCHAR(100) = N'我是德州人' INSERT INTO Encode VALUES (@mandarin) SELECT EncodeStr , LEN(EncodeStr) LengthStr , DATALENGTH(EncodeStr) DataLen FROM Encode
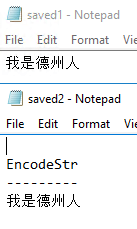
Now that we have our saved value in the database, we want to read this value in PowerShell and create a file with this stored value. As we saw in the initial exercise, we know that we can save these data as UTF8 or Unicode - we'll use Unicode going forward.
When we read our data from the database, we first will check the output in PowerShell to validate that it's correct - we don't want to see non-Mandarin characters like question marks - then we'll save our value to a file. In the below code, we have four steps, which shows the step-by-step process that we can use with the latter two steps showing alternate routes to saving data to a file using the same encoding. Our first step involves querying the data in PowerShell ISE and seeing the output, which we see is correct. Our next step involves getting the EncodeStr value of the output from our query - this is drilling into the actual values of our output. Our third step shows one alternative to saving a file - we create the object $saveContent to store our EncodeStr value, then save it to a file using Add-Content encoded with Unicode. The alternate route is to pipe the output of our query to produce the saved2.txt file and encode it with Unicode (this saves the entire output including the column name).
$server = "OurServer" $db = "OurDatabase" $encQuery = "SELECT EncodeStr FROM Encode" ### 1 - Query (see output) Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $encQuery ### 2 - Get the EncodeStr values (see 2nd output) (Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $encQuery).EncodeStr ### 3 - Save content, one method with using and object $saveContent = (Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $encQuery).EncodeStr Add-Content "C:\files\encoding\saved1.txt" $saveContent -Encoding Unicode ### 4 - Alternate Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $encQuery | Out-File "C:\files\encoding\saved2.txt" -Encoding Unicode

What we should highlight here is that we never want to assume that our database values will be read correctly if encoding specifically matters. When working with cross country ETL teams and data, this assumption can create major data challenges - "we thought the default encoding would work because our database values were correct" is an example of a common response after an incident occurs where the default encoding was different than we expected. To provide an example of this, suppose that our application's default encoding is ASCII, but we don't realize this and our database has stored the right information with Mandarin symbols - this is the equivalent to the below PowerShell script running - and we see the result.
$server = "OurServer" $db = "OurDatabase" $encQuery = "SELECT EncodeStr FROM Encode" $saveContent = (Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $encQuery).EncodeStr Add-Content "C:\files\encoding\savederror.txt" $saveContent -Encoding ASCII
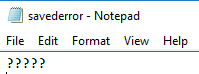
As we see, we get the question marks because ASCII does not support Mandarin characters. This type of error does arise with cross country development teams, though it may involve other encoding formats.
Now, we'll take data from the Unicode file we created earlier and we'll save the data to our table - we'll expect to see two of the same values when we run our query again (the second code block below this). As with reading from the database, we look at this in three steps. First, we read the file and see the output is in the correct format that matches the file's encoding (Unicode). Second, we save the file's data to a variable and write this using Write-Host. Finally, we follow the insert syntax with NVARCHAR specifying N before the string and the object we saved between the ''s.
$server = "OurServer"
$db = "OurDatabase"
### 1 - Get data
Get-Content "C:\files\encoding\mu.txt"
### 2 Save content to object
$saveMandarin = Get-Content "C:\files\encoding\mu.txt"
Write-Host ("Content: " + $saveMandarin)
### 3 Save content to table
$insert = "INSERT INTO Encode VALUES (N'$saveMandarin')"
Invoke-Sqlcmd -ServerInstance $server -Database $db -Query $insert
SELECT EncodeStr , LEN(EncodeStr) LengthStr , DATALENGTH(EncodeStr) DataLen FROM Encode

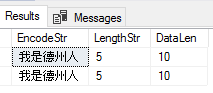
We should consider two important points from adding data appropriately: assuming the format source is correct, like we see with this file:
- We want to ensure that our data type for our column is compatible with the data we want to save. As we've seen, NVARCHAR and NCHAR are appropriate for this.
- We must use the appropriate insert syntax with the N character before the string specified to be explicit in our declaration of the NVARCHAR insert.
Along with identifying the encoding that will support the characters that we use, we also want to consider which derivative may offer more security. For this combination of concerns, encoding is a deep topic where we want to consider what we're trying to accomplish. As we see with PowerShell, we can read and write non-English characters, like Mandarin, with the appropriate encoding.
Next Steps
- With third-party applications, be aware that you may run into encoding issues if files are being read by the third party application that you provide - it may expect one format. In these situations, if you can't determine the encoding, you can reach out to the company to confirm what's allowed. If you are able to determine, update the output of your files to match with what the application expects. In some situations, the recipient must update their system to account for the data provided.
- With cross country teams, files may be read or values may be added that software in one country does not recognize from another country. This may present a challenge, but the errors will generally be identifiable by issues related to a character (like "invalid character at"). As long as you know this, you'll be able to solve any issues that may arise much faster.
- While we may see fewer encoding types that are listed, we may see some in strict security contexts because they don't support many characters. There is a time and place to use these strict encoding formats, but be aware that we may have situations where we receive legitimate data from other encoded sources.
- This tip involves using PowerShell version 5.1; to determine your version, type $PSVersionTable and review the PSVersion property. For the SQL Server version, this tip used SQL Server 2016 with a collation specification of SQL_Latin1_General_CP1_CI_AS.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-05-21
