By: Rick Dobson | Updated: 2019-06-21 | Comments (7) | Related: > TSQL
Problem
The hierarchyid data type seems to have a distinct set of features and use cases that are unlike other SQL Server data types. Because I do not often work with hierarchical data, I am not sure how to take advantage of the data type. Please provide some code, data, and commentary to help me ramp up to speed on the hierarchyid data type.
Solution
SQL Server database administrators and developers are less likely to encounter hierarchical data than relational data. Nevertheless, there are several types of data that lend themselves to a hierarchical representation.
You can think of a hierarchy as a collection of nodes in which nodes relate to one another through links in a tree-like structure. A node is an item in a tree, and it can be represented by a row with a hierarchyid value in a SQL Server table. Any child node can have just one parent node, but each parent can have one or more child nodes. Within a hierarchy there are levels of parents from the top-level parent that has the first set of child nodes through the children of those child nodes down through to the last generation of children that do no serve as parents to a new generation of child nodes. The child nodes from any parent in the hierarchy can have a left-to-right order in which some nodes belong before other nodes. A hierarchical data model specifically targets use cases with layers of one-to-many relationships among its nodes as well as left-to-right orders for the nodes of a parent.
The hierarchyid data type is especially architected to facilitate representing and querying hierarchical data, such as geographical data like those referenced in this tip. The hierarchyid data type has a special way of representing the relationships between the nodes in a hierarchy from top to bottom levels and from left to right among the children nodes of a parent node. The hierarchyid data type is different than other SQL Server data types in that it has properties and methods.
This tip is an initial installment to a multi-part set of tips on hierarchical data and the hierarchyid data type in SQL Server. In this tip, you will learn a couple of different ways to populate a hierarchy with the hierarchyid data type. You will also gain some exposure to a subset of methods of the hierarchical data type.
A geographical names hierarchical dataset
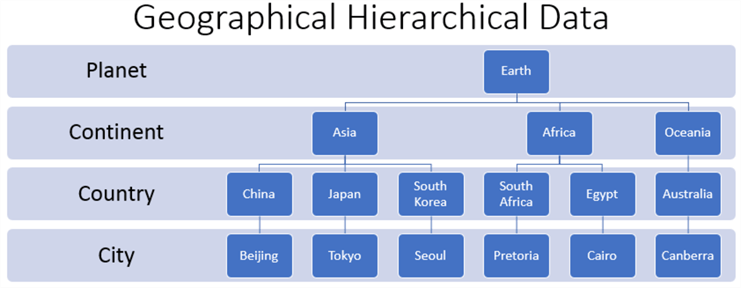
The following chart displays the hierarchical relationship of the Earth to some of its continents. These continents show some of the countries within them, and each country shows the capital city within the country. While the names in the diagram present only a subset of the continents, countries, and cities on Earth, the names are enough to illustrate the basics of a hierarchical dataset.
- The node for Earth at the top of the diagram is the root or top-level parent of the hierarchical dataset.
- Three successive collections of nodes appear below the Earth node.
You can think of these successive collections as hierarchical levels.
- The first hierarchical level is for a collection of continents. Three continents appear in the diagram below.
- Below the continent collection is another hierarchical level for countries within a continent.
- Below the country collection is the final hierarchical level for cities within a country. The cities listed in the diagram are just national capital cities.
Hierarchyid nodes and levels
There are two ways of representing nodes with the hierarchyid data type. The first way is with strings representing the position of the node on each level of a hierarchy. The second way is with bit strings that loosely correspond to hexadecimal values; see this blog for an extensive discussion of bit strings, hex values, and hierarchyid values. This tip gives you exposure to both ways of representing nodes. The hex value sequences and string characters are two equivalent ways of assigning identifier values to nodes.
The string for representing the root node in a hierarchy is /. This string corresponds to the hex value of 0x in SQL Server. Within the context of the diagram above, the root node denotes Earth at the top of the diagram. The level number of the root node is 0.
The string for representing the first collection of nodes below the root is / position_within_first_level /. From left to right, the nodes immediately below the root node can be represented by /1/, /2/, /3/. The level for the collection of nodes below the root level is 1.
- /1/ points at Asia.
- /2/ points at Africa.
- /3/ points at Oceania.
The string for representing the second collection of nodes below the root is /position_within_first_level/ position_within_second_level/. Therefore, the nodes for geographical names from China through Australia can be represented by these strings: /1/1/, /1/2/, /1/3/, /2/1/, /2/2/, /3/1/. The character node identifiers are /1/1/ for China, /1/2/ for Japan, and so forth through /3/1/ for Australia, the largest land mass in the Oceanic continent. The level for this collection of nodes is 2.
The string for representing the third collection of nodes below the root is /position_within_first_level/ position_within_second_level/ position_within_third_level/. This collection of nodes points at the capital city within each country. The level for this collection of nodes is 3.
- The symbols values for the capital cities in Asia are: /1/1/1/, /1/2/1/, /1/3/1. These symbols are, respectively, for Beijing, Tokyo, and Seoul.
- The symbols for the capital cities in Africa are: /2/1/1/ and /2/2/1. These symbols are, respectively, for Pretoria and Cairo.
- The symbol for the capital city of Australia in Oceania is /3/1/1/. This symbol is for Canberra.
Inserting hierarchical data into a SQL table and displaying the data
The following script creates a fresh version of a table named SimpleDemo that has three columns named Node, Geographical Name, and Geographical Type. Node is for the hierarchical node identifier with a hierarchyid data type, Geographical Name is for the name of a geographical unit, such as Asia or China, and Geographical Type is for the geographical type to which a name belongs, such as continent for Asia. None of the columns have any indexes, but not null constraints exist for Node and Geographical Name columns; in other words, all rows must have Node and Geographical Name values, but Geographical Type values are optional. A good rule of thumb is that columns with hierarchyid values should never allow nulls because nodes with a null value are not connected in a known way to other nodes in the hierarchical dataset.
The insert statement populates the SimpleDemo table with row values. The code specifies three input values for each row. You can study the input values for the Node column to confirm the order for specifying rows in a hierarchical format. The input format for Node depends on a slash format denoting levels in the hierarchy. Although values can be input with a slash format for a node identifier, they are saved within SQL Server as bit strings and shown as hex values when they are displayed.
Notice that the values for rows do not appear in hierarchical level order within the insert statement. For example, the rows for the second level geographical names appear before the first level names. Also, the root level name appears last instead of first. The inputting of row values out of hierarchical sequence facilitates highlighting the impact of selecting rows for display with and without an order by clause based on Node values.
The select statement at the end of the script displays the rows in the SimpleDemo table without an order by clause. The rows appear in the default order in which SQL Server saves the rows during data entry. The select list contains items for input columns as well as two other items derived from hierarchyid data type method calls (Node Text and Node Level). Within the script below, the method calls allow the output of five columns although only three columns are input per row.
begin try
drop table SimpleDemo
end try
begin catch
print 'something went wrong with drop table for SimpleDemo'
end catch
go
-- create a table with hierarchyid data type column
-- and two other columns
create table SimpleDemo
(Node hierarchyid not null,
[Geographical Name] nvarchar(30) not null,
[Geographical Type] nvarchar(9) NULL);
insert SimpleDemo
values
-- second level data
('/1/1/','China','Country')
,('/1/2/','Japan','Country')
,('/1/3/','South Korea','Country')
,('/2/1/','South Africa','Country')
,('/2/2/','Egypt','Country')
,('/3/1/','Australia','Country')
-- first level data
,('/1/','Asia','Continent')
,('/2/','Africa','Continent')
,('/3/','Oceania','Continent')
-- third level data
,('/1/1/1/','Beijing','City')
,('/1/2/1/','Tokyo','City')
,('/1/3/1/','Seoul','City')
,('/2/1/1/','Pretoria','City')
,('/2/2/1/','Cairo','City')
,('/3/1/1/','Canberra','City')
-- root level data
,('/', 'Earth', 'Planet')
-- display without sort order returns
-- rows in input order
select
Node
,Node.ToString() AS [Node Text]
,Node.GetLevel() [Node Level]
,[Geographical Name]
,[Geographical Type]
from SimpleDemo
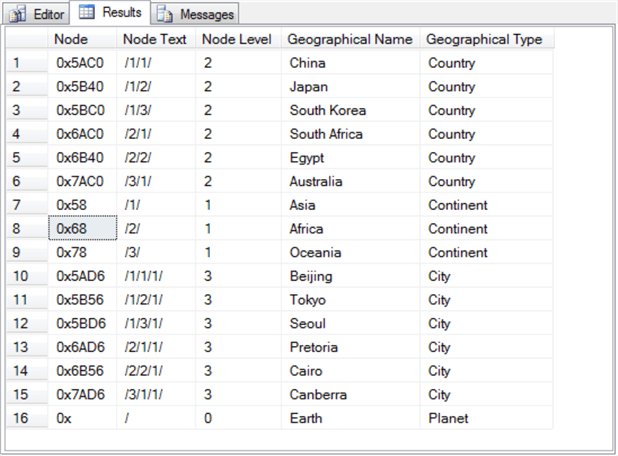
The following screen shot displays the Results pane populated by the preceding script.
- The Node column values appear as hex values although it was originally input with slash format denoting node identifiers. SQL Server automatically converts the slash format values for nodes to hierarchyid values that are displayed as hex values. SQL Server displays hex values with a leading 0x prefix. After the 0x prefix, each hex digit is denoted by a character in the range of 0 through F for integer values from 0 through 15.
- The Node Text column corresponds to the ToString method output for the Node column. The ToString method converts the underlying bit string value to a slash format identifier in the hierarchy.
- The Node Level column shows output from the GetLevel method for the Node hierarchyid data value. Within the context of this tip, these column values are 0 for the root node, 1 for first-level nodes (continents), 2 for second-level nodes (countries), and 3 for third-level nodes (cities).
- The Geographical Name and Geographical Type column values match the entries in the insert statement for each row.
Controlling the display order of hierarchyid values with an order by clause
There are two common ways of displaying hierarchical data. The first is called a depth-first display of nodes, and the second way is called a breadth-first display of nodes. Within SQL Server, the nodes are represented by rows within a table.
- The depth-first display mode shows rows from a start node, which is sometimes but not necessarily the root node, through to the bottom-most node level in a path on the hierarchy. This process repeats for as many distinct start nodes as exist in the hierarchy.
- The breadth-first node displays all the nodes at one level before showing any nodes from the next level. Again, this process repeats iteratively for as many distinct node levels as exist in the result set.
One approach to obtaining a depth-first listing of the rows in a hierarchical result set is to append an order by clause for Node Text or Node to the select statement at the end of the preceding script. The following script shows an example of the syntax.
-- sort by Node Text or Node to get depth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Text] -- order by Node Text or Node to get depth-first list
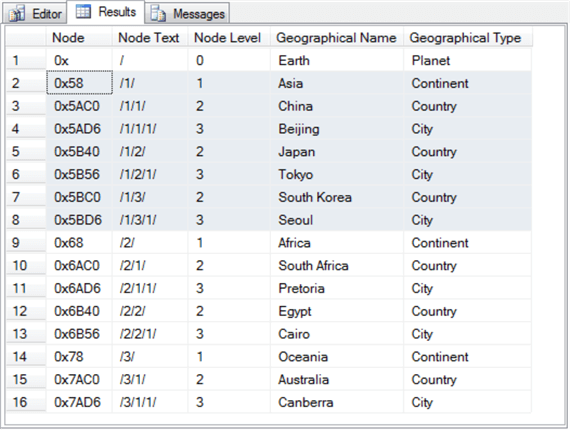
Here's the result set from a depth-first listing of result set rows ordered by Node Text.
- Rows 2 through 8 are highlighted. All these rows are for geographical names pertaining to Asia. The first row in the set has a Node Text identifier of /1/ that is for the continent of Asia. Each successive row in the set starts with /1/. Some of the successive rows are for countries, such as China (/1/1/), Japan (/1/2/), and South Korea (/1/3/). The remaining rows in the highlighted set are for cities, such as Beijing(/1/1/1/), Tokyo(/1/2/1/), and Seoul (/1/3/1/).
- Rows 9 through 13 are for geographical names associated with the African continent. All these rows start with a continent identifier of /2/. Rows 10 through 13 are different in the country and city identifiers.
- Rows 14 through 16 are for geographical names associated with Oceania.
Here's an approach to generating a breadth-first listing of the rows. In this case, the sort is by Node Level. As a result of this sort order rows, the listing is organized by Node Level instead of Node Text (or Node).
-- sort by Node Level to get breadth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level] -- order by Node Level gets breadth-first list
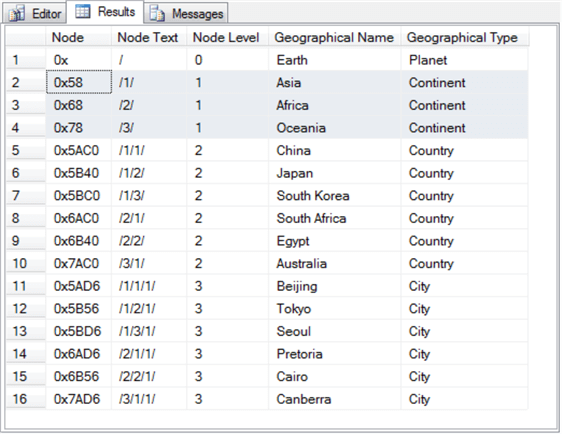
Here's the result set from a breadth-first listing of the rows. Both the preceding depth-first row list and the following breadth-first row list begin with the root row for Earth. However, after the first row, the rows appear in different orders.
- Rows 2 through 4 are for the three continents in the result set: Asia (/1/), Africa (/2/), and Oceania (/3/).
- Rows 5 through 10 are for all the countries. The country names start with China (/1/1/) in row 5 and run through Australia (/3/1/) in rows 10.
- The remaining rows are all for cities.
The rows are input in left-to-right order within levels. However, if this is not the case in a dataset you are using and you need your output in left-to-right order within level, then use order rows by [Node Level] first and Node second.
Controlling the display order of hierarchyid values with primary keys and non-clustered indexes
Instead of using order by clauses without indexes to control the result set row positioning, you can specify either the Node column as a primary key for a depth-first result set listing or you can add a non-clustered index for the Node Level column for a breadth-first result set listing. By controlling the display order with a primary key or a non-clustered index, you display code can run faster. The query cost for displays is clearly more expensive when you use an order by clause without indexes instead of an index to control the result set row order.
The following script has two parts separated by a line of comment markers (dashes).
- The top part is for generating a depth-first row listing with the aid of an order by clause with a table scan (no index).
- The second part has two statements.
- The first statement is an alter table statement to add a primary key to the SimpleDemo table based on the Node column; the primary creates a clustered index based on Node for the SimpleDemo table.
- Then, the second statement is a select statement that implicitly uses the primary key to generate a depth-first order of rows.
-- sort by Node Text or Node to get depth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Text] -- order by Node Text or Node to get depth-first list ---------------------------------------------------------------------------------- alter table SimpleDemo add constraint pk primary key (Node); -- display without sort order -- but with primary key for Node -- returns rows in depth-first order select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo
Before reviewing the results from the parts, let's examine the query plans for each part as well as the associated batch query costs.
The image below shows the query plan for the first part. Observe that there are four operations in the query plan, and the one with the most expensive cost is for Sort operation that corresponds to the execution of the order by clause. Additionally, the query plan starts with a Table Scan, which is also not known for being fast.

The next image is for the query plan associated with the select statement in the second part. The select statement does not include an order by clause. The result set rows from the select statement are ordered implicitly according to a clustered index associated with the pk primary key setting for the Node column. SQL Server assigns Node column values based on a hierarchy in a depth-first way. Therefore, the query returns rows in a depth-first order without the need for an order by clause. As a result, this query cost for this second select statement is dramatically less than for the first one. The batch query cost for the second select statement is more than seventy-five percent less than the batch query cost for the first select statement!

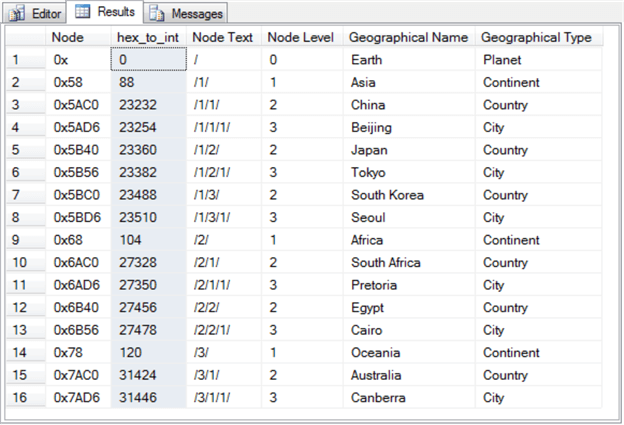
The following query converts the hexadecimal Node value to an int value in its hex_to_int column. The order by clause arranges rows in a depth-first fashion without depending on an appropriately specified primary key. For example, the initial Node Level value is always 1 for each group of rows associated with a continent. Furthermore, the converted Node values increase for geographical names associated within a continent. This progression of integer values confirms that nodes are listed on a depth-first basis within continents.
-- hex_to_int conversion of Node values -- for order by Node select Node ,convert(INT, convert(varbinary, Node, 1)) hex_to_int ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node]
In order to take advantage of a non-clustered index on a table, the column on which the index is defined must be in the table definition. For example, to use a non-clustered index for Node Level values in the SimpleDemo table, a column for Node Level values must be in the table. This is an issue because up until this point, this tip's code defined Node Level in a select statement – not in the SimpleDemo table. Therefore, the next code block re-specifies the create table statement for the SimpleDemo table to include a column for Node Level, and the code below also populates the Node Level column from values in successive rows used within its insert statement. Here's the code to accomplish these two tasks.
-- assign a primary key to hierarchyid column
-- in table to get a depth first display by default
begin try
drop table SimpleDemo
end try
begin catch
print 'something may have gone wrong with drop table for SimpleDemo'
end catch
go
-- create a table with Node hierarchyid data type column
-- (primary key)l also add a Node Level column
create table SimpleDemo
(Node hierarchyid primary key clustered not null,
[Node Level] int not null,
[Geographical Name] nvarchar(30) not null,
[Geographical Type] nvarchar(9) null);
-- insert data out of order by Node Level, but in
-- order by Node
insert SimpleDemo
values
-- second level data
('/1/1/',2,'China','Country')
,('/1/2/',2,'Japan','Country')
,('/1/3/',2,'South Korea','Country')
,('/2/1/',2,'South Africa','Country')
,('/2/2/',2,'Egypt','Country')
,('/3/1/',2,'Australia','Country')
-- first level data
,('/1/',1,'Asia','Continent')
,('/2/',1,'Africa','Continent')
,('/3/',1,'Oceania','Continent')
-- third level data
,('/1/1/1/',3,'Beijing','City')
,('/1/2/1/',3,'Tokyo','City')
,('/1/3/1/',3,'Seoul','City')
,('/2/1/1/',3,'Pretoria','City')
,('/2/2/1/',3,'Cairo','City')
,('/3/1/1/',3,'Canberra','City')
-- root level data
,('/',0,'Earth', 'Planet')
The next script block has two parts.
- The first part is for a select statement that generates a breadth-first listing of the rows in the SimpleDemo table without the benefit of a non-clustered index.
- The second part has two lines of code.
- The first T-SQL statement creates a unique non-clustered index named bfs_index for the SimpleDemo table on the Node Level and Node columns in the table. Both columns are required because Node uniquely defines the rows in the table, but this code seeks to index the rows by Node Level values.
- The second T-SQL statement is a copy of the select statement from the preceding part. However, this instance of the select statement takes advantage of the bfs_index.
-- this query before the creation of the non-clustered -- index on [Node Level] takes 25 percent of total query cost -- the order by clause overrides the primary key to control row order select Node ,Node.ToString() AS [Node Text] ,[Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level] -------------------------------------------------------------------- -- query to compute unique non-clustered index on [Node Level] and Node create unique index bfs_index on SimpleDemo ([Node Level], Node); -- this is the same query computed after the creation of the -- non-clustered index on [Node Level] and Node; -- this query takes just 15% of total query cost select Node ,Node.ToString() AS [Node Text] ,[Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level]
The syntax for the select statements in the first and second parts is identical, and their output is also the same – namely a breadth-first ordered list of rows from the SimpleDemo table. The key difference between the select statements is not the output but the query plan for each select statement.
Here's the query plan for the first part. This query plan has a sort operator that contributes seventy-eight percent of the cost for the query's batch. Additionally, a table scan contributes another twenty-two percent to the query cost for the batch. The query cost for the batch is twenty-five percent.

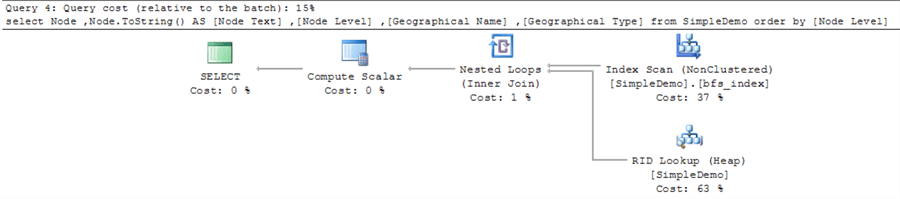
Here's the query plan for the select statement in the second part. Critically, the query plan does not have a sort operator. Instead, this query plan relies on an index scan operator for the bfs_index. A nested loops operator joins results from an index scan operator for the bfs_index and a RID lookup for the SimpleDemo table heap. Because of the batch's reliance on the bfs_index, the overall query cost for the select statement in the second part is just fifteen percent, which is forty percent less than the overall query cost for the select statement in the first part.
Specifying new row values with hierarchyid methods
Up to this point, this tip demonstrated one approach to inserting rows into a table with hierarchyid data type values. The prior approach uses an insert statement with a values clause to specify new hierarchyid data values via slashes and level identifiers. However, the prior approach does not take advantage of built-in methods for the hierarchyid data type. This section highlights the power of the GetDescendant method for adding new rows to a table of hierarchyid data values without relying on slashes and level identifiers. The GetDescendant method facilitates positioning new nodes in a hierarchy from depth, breadth, and left-to-right perspectives.
Before diving into the method's syntax and sample code, it may be helpful to point out that the GetDescendant method name, along with other hierarchyid data type methods, is case sensitive. In other words, you can generate errors by referring to the method in code with names such as GETDESCENDANT, getdescendant, or Getdescendant. The only valid name is: GetDescendant.
This section highlights how to use the GetDescendant method to add geographical names into the SimpleDemo table created and populated in the "Controlling the display order of hierarchyid values with primary keys and non-clustered indexes " section. The method will be used to create a new hierarchical branch starting at the first level below the root node. The GetDescendant method requires a parent node and up to two child nodes to specify the hierarchyid value for a new node in a hierarchical dataset. The syntax for the method from the Microsoft SQL Docs site is as follows: parent.GetDescendant ( child1 , child2 ).
- The parent node has a hierarchyid value that is less than the hierarchyid
value of the new node to be inserted into the hierarchy. The hierarchyid
values of nodes increase in a branch as you traverse a branch from its top node
to its bottom node. The GetDescendant return value is a hierarchyid value
that specifies the position of a new node given its parent node and any other
previously specified child nodes for the parent. From a depth perspective,
you can think about its operation this way.
- If the hierarchyid value of parent is null, then the GetDescendant method returns a null value.
- If the hierarchyid value of parent is non-null, then the GetDescendant method returns a non-null hierarchyid value that is one hierarchical level below the parent's level. Recall that level values are one greater in the child node than in the parent node. The root node at the top of a hierarchy has a level value of zero.
- The child1 and child2 hierarchyid values enable the specification of the
position of a new node from left to right within a hierarchical level.
- If child1 and child2 are both null, then the new node is the sole child of the parent. The new node's hierarchyid value points to one level below the level for the parent.
- If child1 is not null and child2 is null, then the new node's hierarchyid value is greater than child1 and points to one level below the parent's level.
- If child1 is null and child2 is not null, then the new node receives a hierarchyid value less than child2 and points to one level below the parent's hierarchyid value.
- If both child1 and child2 are not null, then the new node receives a hierarchyid value between the hierarchyid values for child1 and child2 and points to one level below the parent's hierarchyid value.
- The GetDescendant method is also of value because it traps for illegitimate
parent, child1, and child2 node hierarchyid values and raises an exception.
- For example, if either child1 or child2 has a hierarchyid value pointing to a level different than one below the parent's level, then an exception is raised.
- The method also raises an exception when the hierarchyid value for child1 is greater than or equal to the hierarchyid value of child2.
GetRoot is another hierarchyid data type method that you can use when specifying hierarchyid values for new nodes that are one level below the root node in a hierarchy. The GetRoot method returns the hierarchyid value for the top-level node in a hierarchy. The top-level node typically has a hierarchyid value of 0x that the ToString method translates its value of a single forward slash (/); the level for the top-level node is 0. Within the context of the SimpleDemo table, the root node corresponds to the node with geographical name of Earth. The syntax for the GetRoot method is different than the other hierarchyid data type methods. The Microsoft SQL Doc site specifies the syntax this way: hierarchyid::GetRoot().
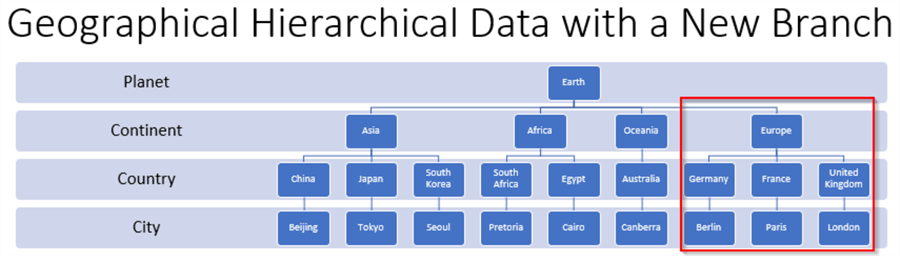
This section demonstrates the application of the GetDescendant and GetRoot methods for adding a branch from the root node for the SimpleDemo table. The following screen shot shows the new branch within a red rectangle. The title for the overall hierarchical dataset image is "Geographical Hierarchical Data with a New Branch". By contrasting this screen shot with the screen shot from the "A geographical names hierarchical dataset" section, you can confirm that the new branch is for subset of geographical names associated with the European continent.
- Therefore, the continent identifier for the top node in the new branch is Europe. Immediately above this node is the root node for the whole hierarchical dataset – Earth.
- One of three country names identify each of the three child nodes below Europe. The node identifiers from left to right are Germany, France, and United Kingdom.
- One of three capital city names identify each of the nodes below the three
country nodes.
- Berlin is the identifier for the capital city node below Germany.
- Paris is the identifier for the capital city node below France.
- London is the identifier for the capital city node below United Kingdom.
Here's the code using GetRoot and GetDescendant methods for adding the node for Europe to the hierarchy.
- The code assigns the root node's hierarchyid value to the @planet local variable.
- Next, the hierarchyid value for Oceania is assigned to the @last_continent local variable. Recall that Oceania has the maximum hierarchyid value among continents until a node for Europe is added to the dataset.
- The addition of the node for Europe is completed by the insert into statement.
- This statement in its values clause assigns the GetDescendant return value with a parent hierarchyid value for Earth and a child1 hierarchyid value for Oceania.
- The level for the Europe node is 1, which is one greater than the root node level value of 0.
- The Geographical Name is, of course, Europe, and the Geographical Type is Continent.
- The left-to-right location of the Europe node on the Continent level is to the right of Oceania.
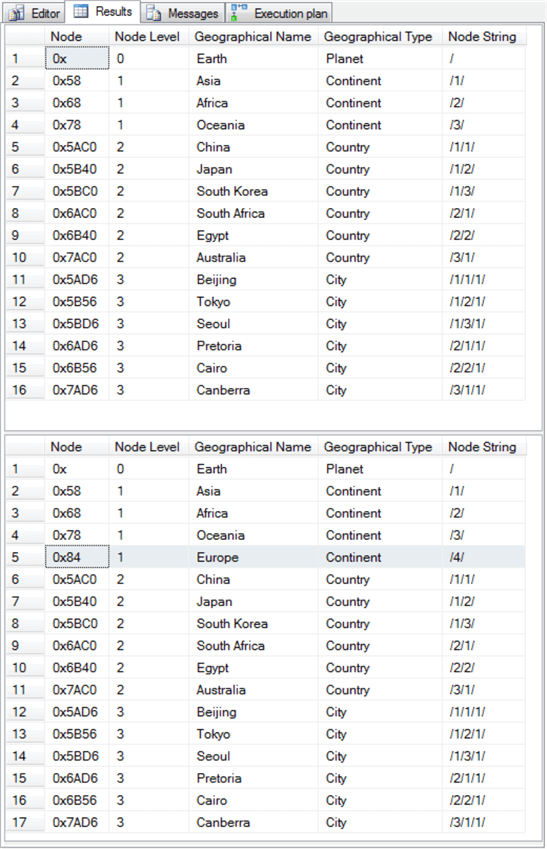
select *, Node.ToString() [Node String] from SimpleDemo order by [Node Level], Node -- add new continent (Europe) row after root level declare @planet hierarchyid = hierarchyid::GetRoot() declare @last_continent hierarchyid = (select max(Node) from SimpleDemo where [Geographical Type] = 'Continent') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@planet.GetDescendant(@last_continent,null), 1, 'Europe','Continent') select *, Node.ToString() [Node String] from SimpleDemo order by [Node Level], Node
The two declare statements and the insert into statement are preceded and followed by select statements.
- The preceding select statement displays the SimpleDemo table rows before the addition of the Europe node. See the first result set in the screen shot below.
- The following select statement displays the SimpleDemo table rows after the addition of the Europe node. See the second result set in the screen shot below. The Europe node is highlighted on row 5, and there 17 rows in the SimpleDemo table as opposed to 16 rows in the preceding result set.
The next step in completing the addition of the new branch to the hierarchy is to add nodes for the three European countries of Germany, France, and United Kingdom. The following script accomplishes that goal, and it includes a trailing select statement to reflect the state of the SimpleDemo table after the addition of the three new country nodes. This script is designed to run in one batch starting with the preceding one for adding the Europe node; it will fail if you run it in a separate batch than the one for adding the Europe node.
Here's a summary of how the script works.
- The @last_continent variable was initially declared in the preceding script, and you may recall it pointed to Oceania. When adding the nodes for each of the three countries in the new branch, the parent is the Europe node. A set statement re-assigns the @last_continent variable to Europe, which now has the maximum hierarchyid value among the nodes on the Continent level.
- Also, each of the three country nodes has a hierarchical level setting of 2. This level number points at the Country level in the hierarchy.
- When adding the node for Germany with the insert into statement, the GetDescendant method has a parent node of Europe. Both child1 and child2 are null because Europe has no child nodes when the Germany node is added as a child to the Europe node. The Geographical Name and Geographical Type field assignments reflect the node identifier and the name for the level in the hierarchy.
- When adding the node for France, the @last_country local variable is assigned the hierarchyid value for the Germany node. The @last_continent remains unchanged from when it was set for adding the Germany node. Then, the GetDescendant method in the insert into statement for adding the France node uses @last_continent as its parent parameter and @last_country as its child1 parameter. The child2 parameter is left null. These GetDescendant settings position the France node to the right of the Germany node. The Geographical Name and Geographical Type field assignments reflect the node identifier and the name for the level in the hierarchy.
- When adding the node for the United Kingdom, the @last_country local variable is re-assigned the hierarchyid value for the France node. Then, the GetDescendant method in the insert into statement for adding the United Kingdom node uses @last_continent as its parent parameter and @last_country as its child1 parameter. The child2 parameter is left null. These GetDescendant settings position the United Kingdom node to the right of the France node. The Geographical Name and Geographical Type field assignments reflect the node identifier and the name for the level in the hierarchy.
-- add first new country (Germany) row belonging to the new continent set @last_continent = (select max(Node) from SimpleDemo where [Geographical Type] = 'Continent') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(null,null), 2, 'Germany','Country') -- add second new country (France) row belonging to the new continent declare @last_country hierarchyid = (select max(Node) from SimpleDemo where [Geographical Type] = 'Country') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(@last_country,null), 2, 'France','Country') -- add third new country (United Kingdom) row belonging to the new continent set @last_country = (select max(Node) from SimpleDemo where [Geographical Type] = 'Country') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(@last_country,null), 2, 'United Kingdom','Country') select *,Node.ToString() from SimpleDemo order by [Node Level], Node
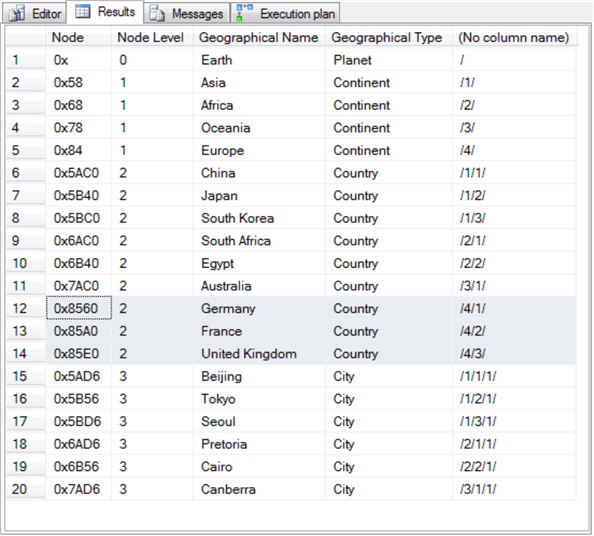
The following screen shot shows the result set from the final select statement in the preceding script segment.
- Notice there are now twenty rows in the SimpleDemo table. This includes one new row for each of the three country nodes.
- The rows for the three new country nodes are highlighted in the following screen shot.
The approach for adding capital cities for Germany, France, and the United Kingdom is slightly different than the approach for adding the country nodes to the Europe node. It is different because each country node has just one city node below it whereas the three country nodes all shared the same parent node (Europe). The following code works for adding to each country node a child node with the country's capital city. As with the preceding two script segments, this one should be run in a single batch along with the preceding two code segments. This code adds the final leaves to the new branch, and it therefore depends on the prior existence of the earlier nodes in the branch path.
- The code requires two lines for adding a city to a country.
- The first line assigns a value to the @country variable either with a declare statement or a set statement after the @country variable is initially declared.
- The second line is an insert into statement that references the @country variable as a parent parameter when invoking the GetDescendant method for specifying a hierarchyid value for the new city node. The child1 and child2 parameters are both null because each country has just one capital city.
- There are a few other points about the insert into statements that are worth
mentioning. After generating the hierarchyid value with the GetDescendant
method for each city, the insert into method makes three more assignments.
- The Node Level is assigned a value of 3, which is the final level in the new branch. This assignment is the same for all leaves in the hierarchy.
- The Geographical Name of the city level is different for each country.
The capital city is
- Berlin for Germany
- Paris for France
- London for the United Kingdom
-- add new city (Berlin) to country of Germany declare @country hierarchyid = (select node from SimpleDemo where [Geographical Name] = 'Germany') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'Berlin', 'City') -- add new city (Paris) to country of France set @country = (select node from SimpleDemo where [Geographical Name] = 'France') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'Paris', 'City') -- add new city (London) to country of United Kingdom set @country = (select node from SimpleDemo where [Geographical Name] = 'United Kingdom') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'London', 'City') select *,Node.ToString() from SimpleDemo order by [Node Level], Node
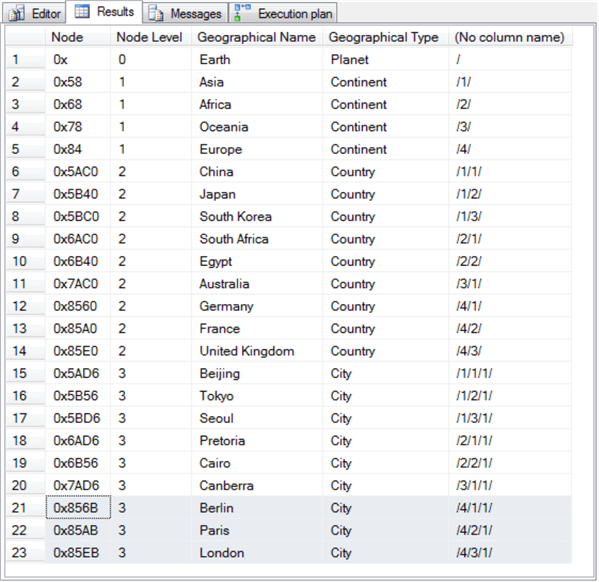
Here's the result set from the preceding script segment.
- There are 23 rows in this result set.
- The last 3 rows are highlighted; these rows are for the capital cities.
- In total there are seven rows added in this section beyond those populated
by the preceding section for the SimpleDemo table.
- One new row is for the continent of the new branch.
- Three additional child rows are for countries on the European continent.
- Finally, three additional child rows – one for each country – are for the capital cities.
Next Steps
- Start by running the code in the "Inserting hierarchical data into a SQL table and displaying the data" section. This will acquaint you with the basics of inserting hierarchical dataset rows into a SQL Server table and displaying rows in the table.
- Next, run the code in the "Controlling the display order of hierarchyid values with an order by clause" section to become familiar with listing hierarchical data content in either depth-first order breadth-first order.
- Then, run the code in the "Controlling the display order of hierarchyid values with primary keys and non-clustered indexes" section to become familiar with how to use indexes for listing hierarchical data content in both depth-first or breadth-first orders.
- Finally, run the code in the "Specifying new row values with hierarchyid methods" section to learn how to use the GetDescendant hierarchyid data method for programmatically adding new nodes to a table of hierarchical data values. Run the three script segments from the section in one batch. If you decide to run the code more than once, you may find it useful to start with a fresh copy of the table created and populated in the "Controlling the display order of hierarchyid values with primary keys and non-clustered indexes" section.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-06-21
