By: Daniel Farina | Updated: 2019-06-06 | Comments (5) | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Triggers
Problem
Using SQL Server triggers can be tricky, so in this tip I will tell you about best practices to adopt when working with SQL Server triggers.
Solution
When writing Transact-SQL code, developers must follow internal coding rules that have been established by the company. Most of the time those rules are focused on how the code is written leaving aside what the code is doing (or trying to do). In other words, the internal coding guidelines of most enterprises covers aspects like naming conventions, capitalization of statements and variables, and tabulations just to mention a few.
But even the nicest and easiest to read piece of code can become a nightmare if you have to find a bug. This is specially the case when triggers are involved. So, I decided to write this as a reference guide to cover what is usually not covered in a company’s internal coding rules.
SQL Server Trigger Best Practices
We know that a SQL Server trigger is a piece of procedural code, like a stored procedure which is only executed when a given event happens. This implies that triggers cannot be executed manually. This fact makes them very hard to debug. The reason for this is that the debugging difficulties are not limited to the trigger itself, like what happens when debugging a stored procedure. Instead a trigger can affect the function of stored procedures, functions and even ad-hoc queries.
Check out these best practices.
1 - Limit the number of SQL Server triggers per table or view
SQL Server has no limitation on the number of triggers that you can define on a table or view, but as a best practice it’s recommended to limit the number to one trigger or at most two associated with the same firing event on an object. For example, there is no problem if you have a table (or view) with three triggers and each of those triggers fires separately for INSERT, UPDATE and DELETE statements. Having more triggers per object adds unnecessary complexity at the time of debugging and establishing trigger execution order. If you have many triggers per object, I suggest you to review your business rules. Take some time to move the code of those triggers to stored procedures and then add the call of the stored procedure to one single trigger.
2 - SQL Server Triggers Should Work with Multiple Rows
This is a very common mistake, especially when an inexperienced developer tries to enforce some kind of user defined data integrity constraint.
In order to explain this, let's take as an example the code from the tip SQL Server Referential Integrity Across Databases Using Triggers where I use triggers to enforce referential integrity across databases. If we take a look at the script below you can see that I am checking for the existence of matching rows between the DELETED pseudo table and the HR.dbo.Employees table and doing this as a set instead of row by row.
USE SecDB;
GO
CREATE TRIGGER TR_Users_Employees_Delete ON dbo.Users
INSTEAD OF DELETE
AS
SET NOCOUNT ON
IF EXISTS ( SELECT 0
FROM Deleted D
INNER JOIN HR.dbo.Employees E ON D.UserID = E.UserID )
BEGIN
;
THROW 51000, 'You Need to delete the Employee First', 1;
END
ELSE
BEGIN
DELETE Users FROM Users U INNER JOIN Deleted D ON D.UserID = U.UserID
END
GO
RBAR In a SQL Server Trigger - Worst Practice
In the example code below, I will show you how the same trigger could be written using a RBAR (Row by Agonizing Row) instead of a set-based logic. Where each row is processed one by one and will be much slower. This is bogus code and a worst practice.
USE SecDB;
GO
CREATE TRIGGER TR_Users_Employees_Delete ON dbo.Users
INSTEAD OF DELETE
AS
DECLARE @UserID INT
SELECT @UserID = UserID
FROM deleted
SET NOCOUNT ON
IF EXISTS ( SELECT 0
FROM Employees
WHERE UserID = @UserID )
BEGIN
;
THROW 51000, 'You Need to delete the Employee First', 1;
END
ELSE
BEGIN
DELETE FROM Users WHERE UserID = @UserID
END
GO
3 - Avoid Complex Logic in SQL Server Triggers
You should try to avoid creating triggers that contain calls to stored procedures or user defined functions. When working with triggers we must aim for fast execution, and including calls to other objects may end up resulting in excessive recompilations and non-efficient plans being cached. You can also suffer from parameter sniffing if you are unlucky enough when executing stored procedures or functions from inside a trigger.
In the case when you cannot avoid calling other objects because your business rules are complex, then make sure you focus on optimizing the code of the stored procedures or user defined functions you are using inside the trigger.
Another thing that you must watch out for is nested triggers. Nested triggers are triggers whose execution fires another trigger, either on the same table or a different table. A particular case of a nested trigger happens when a trigger fires the execution of another instance of itself, this is known as a recursive trigger.
4 - Maintain Documentation for your SQL Server Triggers
Triggers possess a quality that stored procedures don’t have: They are invisible to the user. In other words, if you are not aware that there is a trigger associated with a given table that your code is using, your code may not work as expected. This can take you a lot of time to figure out, especially if your code is large and complex. Let’s take a look at an example. Suppose you are creating a query that inserts data into a table, let’s call it Customers, and this table has a trigger associated with it. If the trigger on the Customers table is not documented you will for sure spend a lot of time figuring out why the query you are coding keeps failing.
In the next code section, the code for the table and trigger creation is set up in the test environment. As you can see, the INSTEAD OF INSERT trigger replaces the value of the CustomerSince column with the current date (i.e. the value of the GETDATE function).
CREATE TABLE Customers (
CustomerID INT IDENTITY (1,1) PRIMARY KEY CLUSTERED,
CustomerName VARCHAR(50),
CustomerSince DATETIME
)
GO
CREATE TRIGGER TR_Customers ON dbo.Customers
INSTEAD OF INSERT
AS
SET NOCOUNT ON
INSERT INTO dbo.Customers ( CustomerName ,
CustomerSince )
SELECT CustomerName ,
GETDATE()
FROM Inserted;
GO
Now let’s see what happens when we try to insert a row with a specific value for the CustomerSince column.
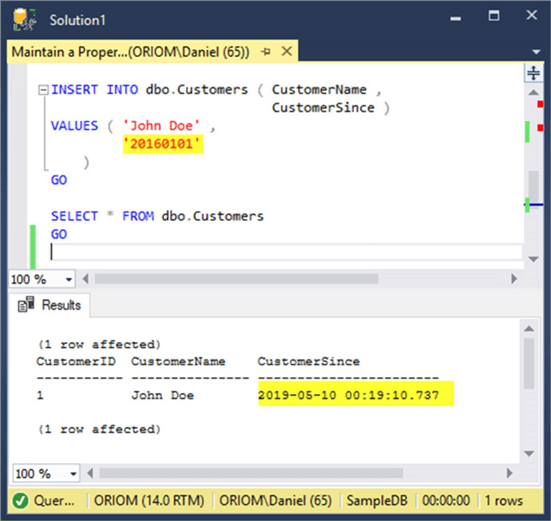
INSERT INTO dbo.Customers ( CustomerName, CustomerSince ) VALUES ( 'John Doe', '20160101' ) GO SELECT * FROM dbo.Customers GO
As you can see in the screen capture below, when we try to insert a specific value into the Customers table for the CustomerSince column, the value saved is different than the value passed to the T-SQL statement. We didn't receive an error message or any warning to make us aware of why the inserted row doesn’t have the value we tried to insert in the CustomerSince column.
5 - Stay on the Same Server when working with SQL Server Triggers
Using remote queries in triggers is a bad practice. Distributed queries have detrimental effects on performance and you should avoid this practice if possible. In the case you have to implement referential integrity between databases residing on different servers try to keep the usage of remote queries to a minimum.
6 - Perform Validations First for SQL Server Triggers
This is best practice we often forget. Let me be clear, from a logical point of view you can make your validations wherever you want, but from a performance point of view it would be great if we check the conditions at the start of the trigger’s code. For example, you can check if there was a row affected before starting to run any code by using the following lines.
IF (@@ROWCOUNT = 0) RETURN;
By using the @@ROWCOUNT statement you can check for the rows affected, and if there were no rows affected, return execution to the caller and don't bother executing the rest of the trigger code.
Additionally you can check for changed column values (either inserted or updated) by using the UPDATE (Transact-SQL) or the COLUMNS_UPDATED functions.
Next Steps
- In case you can’t avoid having many triggers associated with the same table or view, in this tip you will find the way of Forcing Trigger Firing Order in SQL Server.
- If you are dealing with nested triggers this tip will help Maximum stored procedure, function, trigger or view nesting level exceeded limit 32.
- Need to implement referential integrity with triggers? Take a look at my previous tip SQL Server Referential Integrity across Databases Using Triggers for an example on how to do it.
- Also take a look at this tip Foreign Key vs. Trigger Referential Integrity in SQL Server if you need a comparison between implementing referential integrity using the normal approach with foreign keys versus using triggers.
- In case you decide to use triggers between linked servers, take a look at this tip that covers performance issues with linked servers: Performance Issues when Updating Data with a SQL Server Linked Server.
- Stay tuned to SQL Server Triggers Tips Category for more tips and tricks.
- If you want to leverage your career by increasing your knowledge take a look at SQL Server DBA Best Practices Tips Category.






About the author
 Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.
Daniel Farina was born in Buenos Aires, Argentina. Self-educated, since childhood he showed a passion for learning.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-06-06
