By: Sergey Gigoyan | Updated: 2019-07-05 | Comments | Related: > TSQL
Problem
There are some concepts in SQL Server which have different names, but functionally they are equivalent. However, the difference between their names can sometimes be confusing and therefore these questions can be classified as a frequently asked questions in the SQL Server sphere. In this article, we will investigate some of these concepts and reveal their similarities and differences.
Solution
What we are going to do in this article is formulate these frequently asked questions and give explanations. So, let's start with similar data types and define the first question.
What is the difference between Decimal and Numeric data types in SQL Server?
The answer is short: There is no difference between them, they are absolutely the same. Both are fixed precision and scale numbers. For both, the minimum precision is 1 and the maximum is 38 (18 - by default). Both data types cover the range from -10^38+1 to 10^38-1. Only their names are different and nothing more. Thus, these types can be used interchangeably. The following example illustrates the declaration and usage of variables of decimal and numeric types:
DECLARE @numVar NUMERIC (4,2)=16.25 DECLARE @decVar NUMERIC (4,2)=15 SELECT @numVar AS NumericVar, @decVar AS DecimalVar SET @numVar=@decVar SELECT @numVar AS NumericVar, @decVar AS DecimalVar
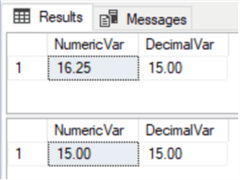
As they are the same types, there were no problems in assigning decimal and numeric variables (with the same scale and precision) to each other. In the next example, we can see that if we are assigning a value with a higher scale, it is rounded:
DECLARE @numVar NUMERIC (4,2)=35.98645 DECLARE @decVar NUMERIC (4,2)=35.98645 SELECT @numVar AS NumericVar, @decVar AS DecimalVar
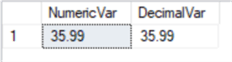
However, if the precision is higher, an error will be generated:
DECLARE @numVar NUMERIC (4,2)=355.98645 DECLARE @decVar NUMERIC (4,2)=335.98645 SELECT @numVar AS NumericVar, @decVar AS DecimalVar
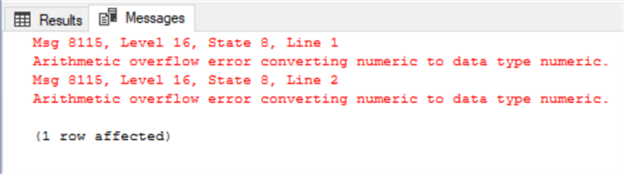
To sum up, decimal and numeric data types are identical and developers can feel free to use whichever they prefer.
What are the differences between Timestamp and Rowversion SQL Server data types?
Actually, these data types are synonyms. Objects of these data types hold automatically generated binary numbers which are unique within the database. The storage size for these data types is 8 bytes. While a nullable column of rowversion (timestamp) data type is semantically equivalent to a varbinary(8) column, nonnullable column of rowversion(timestamp) type is semantically equivalent to a binary(8) column.
In spite of its name, timestamp(rowversion) data type has nothing in common with date and time data types. Rowversion(timestamp) data type is an incrementing number. Each time a row in a table containing a rowversion(timestamp) column is inserted or updated, the incremented value of database rowversion(timestamp) is inserted into that table's rowversion(timestamp) column. This makes rowversion(timestamp) column very useful for detecting, comparing, synchronizing data changes in tables. Each table can have no more than one column with rowversion(timestamp) data type.
To illustrate these data types in practice, let's create the following tables with rowversion and timestamp data types:
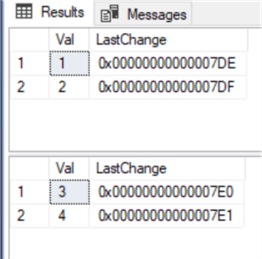
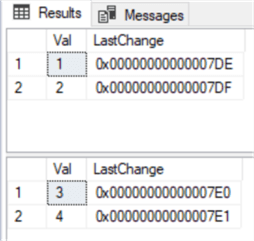
CREATE TABLE ##tmpTableA ( Val INT, LastChange ROWVERSION NOT NULL ) CREATE TABLE ##tmpTableB ( Val INT, LastChange TIMESTAMP NOT NULL ) INSERT INTO ##tmpTableA(Val) VALUES(1),(2) INSERT INTO ##tmpTableB(Val) VALUES(3),(4) SELECT * FROM ##tmpTableA SELECT * FROM ##tmpTableB
As we can see in both tables, the values for LastChange column were generated automatically:
Now, let's copy this data to tables which have columns with binary(8) data type to store rowversion(timestamp) data from the tables above:
CREATE TABLE ##tmpTableC ( Val INT, LastChange BINARY(8) NOT NULL ) CREATE TABLE ##tmpTableD ( Val INT, LastChange BINARY(8) NOT NULL ) INSERT INTO ##tmpTableC (Val, LastChange) SELECT Val, LastChange FROM ##tmpTableA INSERT INTO ##tmpTableD (Val, LastChange) SELECT Val, LastChange FROM ##tmpTableB SELECT * FROM ##tmpTableC SELECT * FROM ##tmpTableD
The result shows that the rowversion(timestamp) data is successfully copied to binary(8) columns as they are semantically equivalent:
Having said that, there are some points to be taken into account while working with these data types:
- According to Microsoft, the timestamp data type is deprecated and will be removed in future versions. Thus, it is recommended to use rowversion instead of timestamp wherever possible.
- In case of creating a table in SQL Server Management Studio and setting a column type, the only available choice is timestamp. There is no rowversion available in the dropdown. Even if the table is created using T-SQL code and a column's type is defined as rowversion, in Management Studio its type will be shown as timestamp.
- In T-SQL code, it is possible to create a column with timestamp type without mentioning a column's name. In this case, the column's name will be generated automatically which will be named TIMESTAMP. This is not possible if in the T-SQL code the column's defined as rowversion instead of timestamp.
Are there differences between a SQL Server unique index and unique constraint?
Both can be used to enforce uniqueness of values in a column(s). Creating both means that SQL Server creates a non-clustered unique index on that column(s) by default. If there is no clustered index on the table, it is possible to create a unique index as well as a unique constraint as clustered. In terms of performance, the SQL Server engine does not consider whether a unique index is created as a unique constraint or index when choosing an execution plan and, therefore, there is no difference in performance.
Now, let's create a table and then a unique index and unique constraint on its columns:
CREATE TABLE ##TestTable
(
ID INT IDENTITY(1,1),
Val1 INT,
Val2 INT
)
-- Unique index
CREATE UNIQUE INDEX UIX_TestTable_Val2 ON ##TestTable(Val1)
--Unique constraint
ALTER TABLE ##TestTable
ADD CONSTRAINT UC_TestTable_Val2
UNIQUE (Val2)
SELECT * FROM tempdb.sys.indexes WHERE OBJECT_ID = object_id('tempdb..##TestTable')
From the last query we can see that regardless of creating a unique constraint or unique index, unique nonclustered indexes were created on both columns. However, for the Val2 column, it is clearly shown that it is a unique constraint where is_unique_constraint = 1:

Nevertheless, it is important to mention some technical differences:
- Unlike unique index creation, in the case of creation of an unique constraint, setting some index options are unavailable in SSMS as well as in T-SQL code.
- It is not possible to drop the index, which created as a result of an unique constraint creation, by using the DROP INDEX command. The DROP CONSTRAINT command should be used instead, which, in turn, removes the associated index as well.
All in all, in order to ensure uniqueness of values in a column, creating unique indexes instead of unique constraints, in some terms could be considered as a more flexible solution. This is because developers have more options while creating indexes using T-SQL code and also, unlike unique constraints, there are no special preconditions to delete unique indexes. Moreover, there is no difference in terms of performance. Unique constraints could be seen as a method of making clear the meaning and purpose of the index.
What is the difference between <> and != (Not Equal To) SQL Server operators
They are the same operators and there is no difference in terms of functionality or in terms of performance. Both compare two expressions and the result is TRUE if they are not equal. If they are equal, the result is FALSE. It is assumed that both operands are not NULL. You could use SET ANSI_NULLS to define the desired outcome of comparison with NULLs.
- The only thing worth mentioning is that <> operator is ISO standard and != operator is not. Anyway, it does not make any difference in their functionality.
The following example shows the simple usage of these operators:
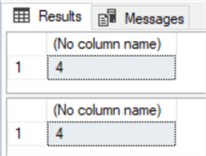
DECLARE @value INT=5 --Using <> IF(@value <> 0) SELECT 20/@value ELSE SELECT 0 --Using != IF(@value != 0) SELECT 20/@value ELSE SELECT 0
In both cases, the result is "4" because @value is not "0", it is "5":
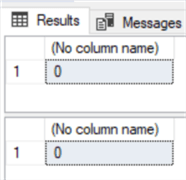
In contrast, in the next example, we will receive 0 for both cases. This is because 0=0 and, therefore, 0<>0 (0!=0) returns FALSE:
DECLARE @value INT=0 --Using <> IF(@value <> 0) SELECT 20/@value ELSE SELECT 0 --Using != IF(@value != 0) SELECT 20/@value ELSE SELECT 0
Is there a difference between INNER JOIN and JOIN in SQL Server?
They are absolutely equivalent. JOIN returns all rows from two or more tables where the join condition is met. It can be written with and without the INNER word and it depends only on the developer's preference:
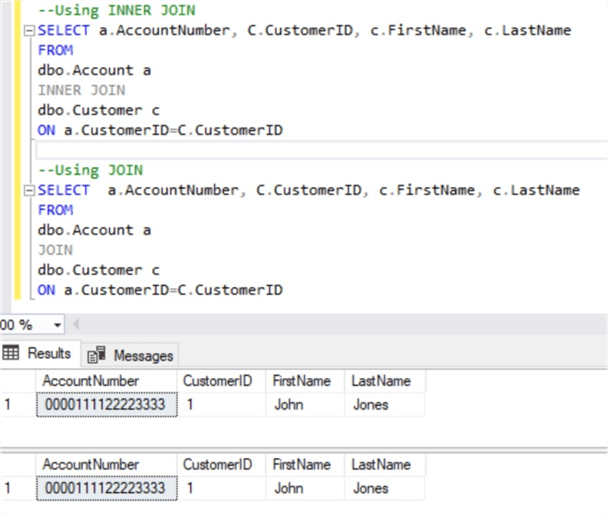
Similarly, OUTER can be left out in LEFT OUTER, RIGHT OUTER, and FULL OUTER joins:
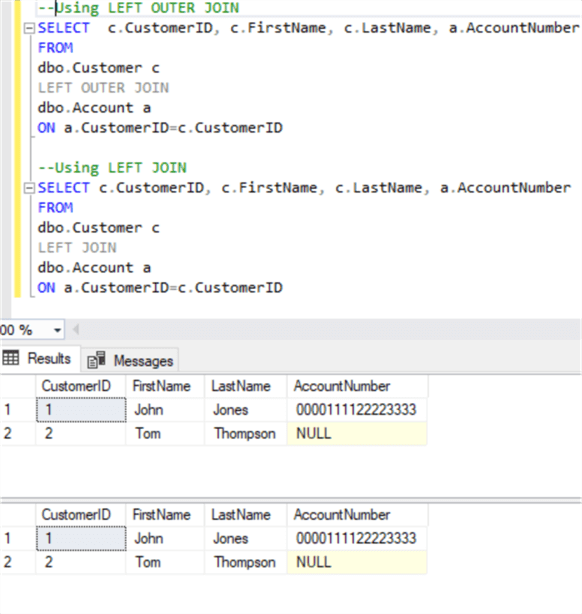
While some developers feel more comfortable using the OUTER keyword, claiming that it makes the code more readable, others who do not share this view always leave out this keyword. Anyway, the OUTER keyword changes nothing in the result, so developers can use their preferred style.
Conclusion
In conclusion, these are some concepts in SQL Server which are functionally equivalent. The differences between some of the above-described concepts are only in their names or syntax (such as decimal and numeric data types, != and <> operators, OUTER keyword in joins and so on). There are other concepts which are functionally equivalent but yet have some minor differences related to their usage (for instance, UNIQUE INDEX and UNIQUE constraint, and timestamp and rowversion data types).
Next Steps
You can find additional information about the items discussed in the topics below:
- https://msdn.microsoft.com/en-us/library/ms187746.aspx
- https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2012/ms182776(v=sql.110)
- Synchronizing SQL Server data using rowversion
- Difference between SQL Server Unique Indexes and Unique Constraints
- https://docs.microsoft.com/en-us/sql/t-sql/language-elements/comparison-operators-transact-sql?view=sql-server-2017






About the author
 Sergey Gigoyan is a database professional with more than 10 years of experience, with a focus on database design, development, performance tuning, optimization, high availability, BI and DW design.
Sergey Gigoyan is a database professional with more than 10 years of experience, with a focus on database design, development, performance tuning, optimization, high availability, BI and DW design.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-07-05
