By: Eduardo Pivaral | Updated: 2019-06-25 | Comments (2) | Related: 1 | 2 | 3 | > TSQL
Problem
It is very common in the IT field for a developer to switch to a Database Developer or Database Administrator, even when the programming concepts are the same, the skillset required to code T-SQL is different. If we are not careful, we can end up having poor-performing code in our SQL Server database. Even when there is a lot of information and tips about query performance, for someone who is starting with T-SQL development, is hard to know where to start, or having simple examples to understand the key concepts more clearly.
Solution
In this tip, we will show some basic concepts and tips to help you write better code, and having the basics, you can learn about any specific topic in more detail later.
Part 1 we will learn how the SQL engine works and some database design tips to improve application performance.
How the SQL Server engine works
The main difference between T-SQL and other languages like C# or JS is that T-SQL is a declarative language, we instruct what we want to do and the engine decides how to do it.
This is a very simple diagram on what happens when you run a query:
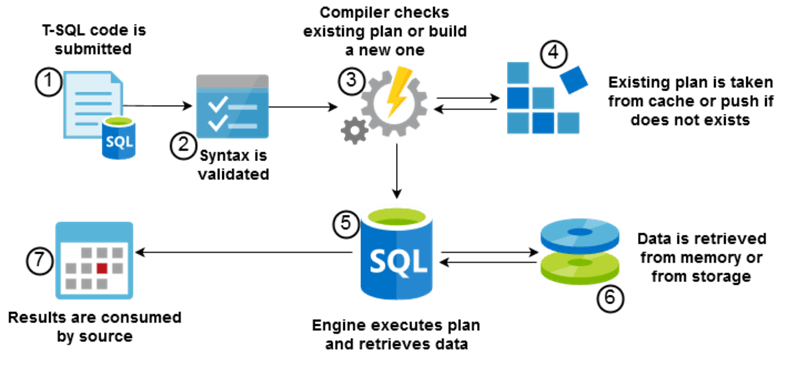
The SQL engine receives the request to execute a query, and then based on many factors (to name some: statistics, indexes, current server load, object locks, etc.), the engine calculates the most efficient way to execute this query: this is known as the execution plan.
There are 2 types of execution plans: estimated and actual.
- Estimated Plan is how a query will be executed based on existing indexes, statistics and server load at request moment.
- Actual Plan includes run time statistics (number of rows processed) to the execution plan information.
In some cases, the Estimated and Actual plan will be the same, but this is not always the case.
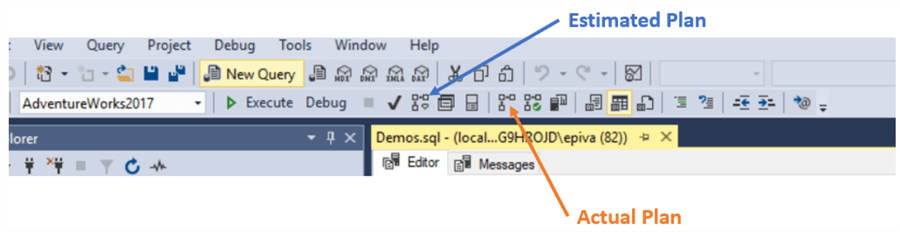
The engine does a pretty decent job calculating this plan, and most of the time, we obtain the most efficient plan. We can check the query plan performance using the Query Store. You can also override and force the plans to run the way you want using query hints, but this is something only an experienced developer or administrator must implement, since we could have undesired results.
Once the query plan is compiled, it is stored in memory so it can be re-used for future requests without needing to be recompiled.
If you want to clear the query plan cache from memory, you can execute the following T-SQL which will clear all query plans for the SQL Server instance.
DBCC FREEPROCCACHE;
NOTE: You must avoid running this in production environments, because after executing it, all query plans must be compiled again.
The SQL Engine also improves performance by putting object data in memory (RAM) when you first pull it from disk, so it can be later accessed without having to access the disks again. How much data and how long it lasts in memory depends on many factors, such as memory available for the SQL Server instance, data size, server load, complexity of queries and requests made.

To check what data is in memory, you can use the following T-SQL. Also, check out this tip Determine SQL Server memory use by database and object.
SELECT * FROM sys.dm_os_buffer_descriptors;
Depending on the load of your server, you can obtain something like this:
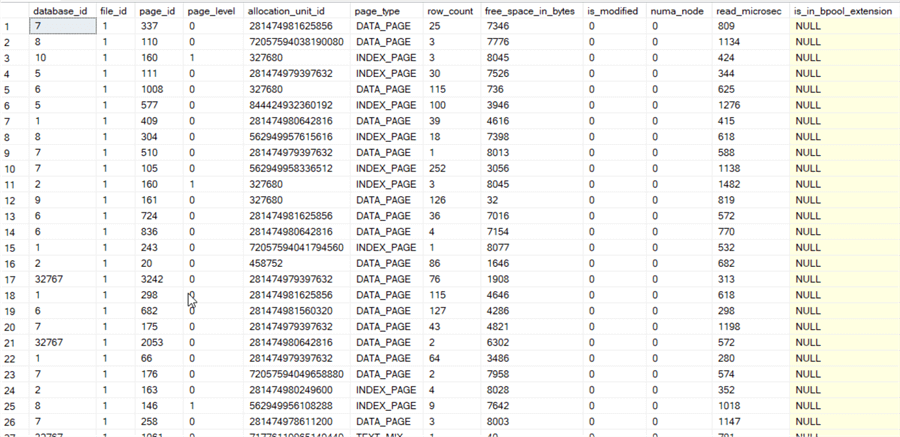
Information is at page-level (8KB), the fundamental unit of data storage for SQL Server.
If you want to clear data cache from memory, you must execute the following T-SQL:
DBCC DROPCLEANBUFFERS;
NOTE: You must avoid running this in production environments, because after executing it, all data must be pulled from storage again.
General tips for writing optimal T-SQL code
With a proper database and application design, we can fix issues even before they exist, because a lot of issues I have encountered on my job could be avoided by making different decisions, implementing some processes or enforcing some coding rules in the design/development stage.
Long development life cycles can lead to releases on old systems
With the rise of DevOps, release cycles are shorter and patches and bug fixes are implemented more frequently (for example monthly releases of Azure Data Studio or Power BI), but in the past, some production releases could take a long time to complete (years for some severe cases) and when the applications are ready to be deployed, the platforms you deploy them are already obsolete, that leads to code migrations that only creates duplicate efforts and could lead to more human errors in the code.
Another approach to avoid this, is to work via modules, so you can create different databases for different modules, so if any module requires extra time, it will not affect other databases. Another benefit of this approach is bug fixes will require less code changes and less production releases, it will reduce outages and human errors.
Design your application to support high volumes of data and concurrency
Another common mistake is to perform QA tests over a small set of data, or with just a few (or only one) users testing at a time. You can find that everything is working "fine" during your testing or QA, but once you release the code to be used on production, if the program and the code is not designed to support concurrent sessions you could end up mixing user data from concurrent sessions or bringing your application down because of duplicate key constraints or other issues.
The issue with high volumes of data is that your application could work fine with small sets of data, but once you load a lot of information, if is not coded properly, your performance could be severely degraded, or even worse, your application could become non-responsive.
Implement data purging/historical movement processes
Databases can grow uncontrollably due to message logs and historical data, take this example from an unmonitored msdb database:
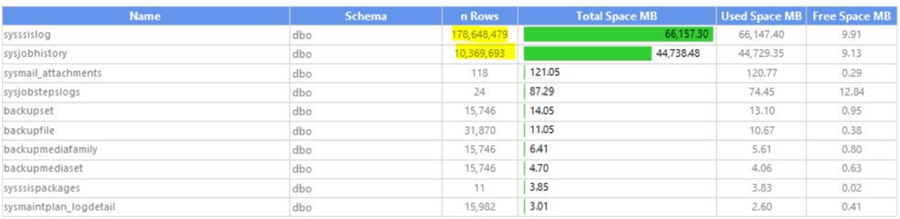
You must implement data purging and/or historical movement processes, to have your OLTP databases with the minimal required data to work, this has a lot of benefits: better resource usage, more space available on your systems (lower storage costs on-premises and cloud), faster backup/restore times, faster consistency issues fixes and a faster response time.
Comment and format your code
It is a fact: you won’t recognize your own code from a long time ago, if you cannot remember what you had for lunch a week ago, do you think you will remember what the code does for a 100+ line stored procedure you wrote two months ago? What if another developer wants to make some changes to the code you wrote? If you are on vacation, they will have to call you to fix an issue if your code is not understandable.
So please always comment and format your code to make easier to read and understand for you and your team.
Test your code trying to make it fail
When you are a junior developer or you are learning something new, you are happy when the code just executes, and forget about anything else, but now that you are senior developer or DBA, you have to test your code trying to find cases or combinations where it could fail, even when in a real life scenario the inputs are not possible, you must try them.
Want another reason? This is the way hackers work, finding ways to make code fail to find error messages or information that could give them insight on how the application works to exploit it. You must be a step ahead and make their life harder and your application more secure.
Proper datatype selection
With millions of records, choosing the correct datatype makes a lot of difference on performance and storage utilization, the same data can occupy unnecessary space if not chosen carefully.
This is a comparison between storage used for distinct datatypes with the exact same data:

This is a small test with just one column and less than a million rows, but can dramatically change in a real-life scenario with hundreds of tables, a lot of columns and a lot of records.
Also, wrong datatypes will require data conversions and additional overhead. Filtering and joining different datatypes will require implicit conversions, this will lead to sub-optimal queries and could negatively impact database performance. (we will see some examples later on this series).
Having issues? Ask for help!
No one is perfect and no one knows everything, don’t be embarrassed to ask questions. The SQL Server community is very friendly and always willing to lend you a hand, on Twitter you can ask any question using the hashtag #sqlhelp, you have this website, and most of the authors (including me) can be contacted if you have any questions about any article.
In part 2 we will see actual code examples and tips to improve your T-SQL code.
Next Steps
- In part 2 we will cover code examples and tips to improve performance.
- Check other performance tuning tips here.






About the author
 Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments.
Eduardo Pivaral is an MCSA, SQL Server Database Administrator and Developer with over 15 years experience working in large environments. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-06-25
