By: Aaron Bertrand | Updated: 2019-07-11 | Comments | Related: > TSQL
Problem
I've written many tips and blog posts about SQL Server syntax, but most of those have revolved around performance. Many syntax conventions serve other purposes, though, including better readability and more predictable behavior.
Solution
In this tip, I wanted to share some of the more common faux pas I come across when helping people on twitter or forums, and why I always recommend style improvements.
Schema-qualify all object references in SQL Server
It is more the exception than the rule that when a query is posted by someone
looking for help, there is no mention of schema anywhere. The core problem here
is predictability, but there is also an issue with plan cache bloat. Let's
take a simple example where we have a schema called test,
and two users, one whose default schema is test, and
the other dbo:
CREATE SCHEMA test;
GO
CREATE USER bob WITHOUT LOGIN WITH DEFAULT_SCHEMA = test;
GO
CREATE USER frank WITHOUT LOGIN WITH DEFAULT_SCHEMA = dbo;
GO
For simplicity, let's grant all potential permissions for the remainder of the demos in one shot:
GRANT SELECT, EXEC ON SCHEMA::test TO bob, frank;
GRANT SELECT, EXEC ON SCHEMA::dbo TO bob, frank;
GRANT SHOWPLAN TO bob, frank;
Create two versions of a stored procedure, one in each schema, which potentially does different things:
CREATE PROCEDURE test.LogActivity
AS
BEGIN
SELECT 'Testing procedure';
END
GO
CREATE PROCEDURE dbo.LogActivity
AS
BEGIN
SELECT 'Production procedure';
END
GO
Then call the procedure LogActivity from the context
of each user:
EXECUTE AS USER = N'bob';
GO EXEC LogActivity;
GO REVERT; EXECUTE AS USER = N'frank';
GO EXEC LogActivity;
GO REVERT;
Results:
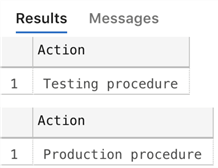
The fact that the exact same code can produce different results has the potential
to create a whole lot of confusion, especially if the output of the procedure doesn't
make it obvious. The default schema for bob may not
be well known, or may have been missed during a migration or promotion of objects
to production, and the unit and integration tests may simply be validating that
the procedure has succeeded or that some specific thing that both procedures
perform has happened.
We can demonstrate a further problem even when we don't have same-named
objects in different schemas. Let's take a simple logging table that exists
only in the dbo schema:
CREATE TABLE dbo.ActivityLog
(
SomeColumn int
); INSERT dbo.ActivityLog(SomeColumn) VALUES(1);
Next, have each user run the exact same query against that table:
DBCC FREEPROCCACHE;
GO EXECUTE AS USER = N'bob';
GO SELECT SomeColumn FROM ActivityLog; GO
REVERT; EXECUTE AS USER = N'frank';
GO SELECT SomeColumn FROM ActivityLog; GO
REVERT;
Both executions yield the same plan and return the same data. But if you look in the plan cache, you'll find a surprise; the exact same statement leads to two independent copies of the same plan residing in cache, each with its own unique plan handle:
SELECT t.[text], p.usecounts, p.plan_handle, p.size_in_bytes
FROM sys.dm_exec_cached_plans AS p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t
WHERE t.[text] LIKE N'%ActivityLog%'
AND t.[text] NOT LIKE N'%sys.%';

I won't make you guess why. If you dig a little deeper, it involves the
plan attribute user_id (though it is named poorly,
since it obviously means default schema in this context):
SELECT t.[text],
p.usecounts, p.plan_handle,
pa.attribute, pa.value,
s.[schema_id], s.name
FROM sys.dm_exec_cached_plans AS p
CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t
CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS pa
INNER JOIN sys.schemas AS s
ON s.[schema_id] = pa.[value]
WHERE t.[text] LIKE N'%ActivityLog%'
AND t.[text] NOT LIKE N'%sys.%'
AND pa.attribute = N'user_id';

Because of these unique attributes, SQL Server has to treat these as different plans, and store them independently. Even if these two queries are being run all the time, and the plans are small, it is still wasteful to have both copies taking up space in the plan cache, when half of that space could be used for other plans.
If you are using multiple schemas now, and your code doesn't have schema
qualifiers, this is a problem that could balloon out of control before you know
what is happening. While dbo is usually all that is
being used, and users aren't typically configured with different default schemas,
it can be very hard to predict how you or a 3rd
party may change your environment in the future.
In some rare cases, leaving the schema out is intentional, for reasons other than laziness (which is translated to “productivity” when challenged). One example is where there are objects in multiple schemas and the resolution is meant to depend on the default schema of the caller (so the same code could be tested to obey different paths simply by switching user context). This is definitely an edge case, and should be deemed an educated exception to the rule, like speeding when you know which parts of the highway are not regularly patrolled by police.
In all other cases, I schema-qualify every object I reference, regardless of the purpose or expected longevity of the code.
Alias all object references in SQL Server
While schema qualifiers can help avoid issues with both predictability and performance, many of my other syntax conventions primarily address readability. Almost daily I see queries like this posted on forums:
SELECT [master].sys.databases.database_id,
[master].sys.databases.name,
[master].sys.master_files.physical_name
FROM [master].sys.databases
INNER JOIN [master].sys.master_files
ON [master].sys.databases.database_id = [master].sys.master_files.database_id
WHERE [master].sys.databases.database_id > 4
ORDER BY [master].sys.master_files.physical_name;
This is being way too explicit and verbose, and drastically hampers readability, almost to the point of being literally painful to read. This query can be made much more readable and manageable by using logical aliases for each object:
SELECT db.database_id,
db.name,
dbfiles.physical_name
FROM [master].sys.databases AS db
INNER JOIN [master].sys.master_files AS dbfiles
ON db.database_id = dbfiles.database_id
WHERE db.database_id > 4
ORDER BY dbfiles.physical_name;
Alias all object references, even when the query only involves
one object today. This makes it so much easier to manage, parse, and understand,
especially if you really do use logical aliases. I see a lot of people use meaningless
aliases like a, b, c or t1,
t2, t3, and I
strongly recommend avoiding that kind of habit.
Table-qualify all column references in SQL Server
Continuing with the previous query, another thing I often see people do is leave
out a table qualifier when it is not absolutely necessary to do so. In this version
of the query, only database_id and
name need to be qualified, because they are ambiguous
(they exist in both tables):
SELECT db.database_id,
db.name,
physical_name
FROM [master].sys.databases AS db
INNER JOIN [master].sys.master_files AS dbfiles
ON db.database_id = dbfiles.database_id
WHERE db.database_id > 4
ORDER BY physical_name;
The column physical_name doesn't strictly
need to be qualified, since SQL Server knows exactly which table that column comes
from. But future readers (including yourself, when maintaining this code later)
may not find this immediately obvious. Troubleshooting this code becomes more complicated
when you need to manually resolve all the column references, and future changes
to the query may introduce errors or unexpected behavior. For example, I could later
add a new column and (unintentionally) give it the alias
physical_name, which then makes the ORDER BY
fail with an ambiguous column error:
SELECT db.database_id,
db.name,
physical_name,
physical_name = REVERSE(physical_name)
FROM [master].sys.databases AS db
INNER JOIN [master].sys.master_files AS dbfiles
ON db.database_id = dbfiles.database_id
WHERE db.database_id > 4
ORDER BY physical_name;
-- Msg 209, Level 16, State 1
-- Ambiguous column name 'physical_name'.
A less obvious issue would be if I were to change physical_name
from a column reference to an expression:
SELECT db.database_id,
db.name,
physical_name = REVERSE(dbfiles.physical_name)
FROM [master].sys.databases AS db
INNER JOIN [master].sys.master_files AS dbfiles
ON db.database_id = dbfiles.database_id
WHERE db.database_id > 4
ORDER BY physical_name;
This doesn't yield an error, but it sure changes the order of the output,
since the alias given to the expression is what ORDER BY
thinks you mean. A symptom that may be considered a bug by end users, but won't
necessarily be caught out by unit or integration tests.
Another case that catches people off guard is when leaving off qualifiers in
an IN() or EXISTS()
subquery. The simplest demonstration I know of is as follows:
CREATE TABLE #foo(foo int); CREATE TABLE #bar(bar int); SELECT foo
FROM #foo
WHERE foo IN (SELECT foo FROM #bar);
On visual inspection, you would think this should error, because
#bar doesn't have a column named
foo. Instead, it succeeds, and the reason is that –
according to the standard – when a reference in a derived table cannot be
resolved, it tries to find that column in an outer scope. Since it finds
foo in #foo, that's
the foo it thinks you meant. While the cause is ultimately
just a typo, it's hard to spot, and not intuitive – IntelliSense won't
help you, and you'd have to know how the results should look to get any indication
at runtime.
To avoid these issues, always provide a table or alias qualifier for all columns.
Terminate all statements with semi-colons in SQL Server
I've joked that this probably won't happen in my lifetime, but since SQL Server 2008, Microsoft has made it clear that you will need to terminate statements with semi-colons at some point:

As the docs continue to say, there is no defined timeline for this restriction to be implemented, but better safe than sorry. I have been staunchly religious about this practice for at least a decade, and with each new version, there are more syntax changes that require semi-colons. The most common one I come across is that the statement before a common table expression (CTE) must be terminated with a semi-colon. To this day, I start all CTEs with a semi-colon because of how many times I've been made the bad guy – after they copied a CTE I wrote, and pasted it into their existing code, which had no semi-colons. So, for example:
SELECT 1 WITH x AS (SELECT y=1)
SELECT y FROM x;
Result:
Msg 319, Level 15, State 1
Incorrect syntax near the keyword 'with'. If this statement is a common table expression, an xmlnamespaces clause or a change tracking context clause, the previous statement must be terminated with a semicolon.
This will depend on the previous statement – a simple variable declaration, for example, does not trigger the same error:
DECLARE @i int WITH x AS (SELECT y=1)
SELECT y FROM x;
But don't let that lull you into a sense of safety. Since there are plenty of ways this won't work, it's never too late to start terminating all statements with semi-colons.
Summary
Transact-SQL is a complex language with a lot of peculiarities and unintuitive gotchas, and it can be useful to establish a set of conventions to save you from the time and hassle of troubleshooting later. I have dozens of standards that I adhere to in every query I write, but these are the four rules that I think are most helpful. What are your favorite syntax rules, and why?
Next Steps
Read on for related tips and other resources:
- Top 5 Reasons for Wrong Results in SQL Server
- SQL Server DateTime Best Practices
- Bad habits to kick : avoiding the schema prefix
- Ladies and gentlemen, start your semi-colons!
- Bad habits: Another case for semi-colons and schema prefix
- Fun with THROW: Avoid % and use semi-colons!
- Bad habits to kick : using table aliases like (a, b, c) or (t1, t2, t3)
- My stored procedure "best practices" checklist






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-07-11
