By: Siddharth Mehta | Updated: 2022-03-02 | Comments (6) | Related: 1 | 2 | 3 | More > Import and Export
Problem
Importing and exporting data from file-based sources is a very routine task when working with databases. Tools like SQL Server Management Studio provide out-of-box tools like the import and export wizards. But for large data sets there are other options to load data into SQL Server. In this tip, we will look at how to perform a bulk import of data into SQL Server using T-SQL.
Solution
SQL Server provides the BULK INSERT statement to perform large imports of data into SQL Server using T-SQL.
BULK INSERT Overview
Let's first understand the syntax and options of the BULK INSERT statement before we start using this command.
- The first argument for BULK INSERT should be a table name or a view name. By default, it expects that the schema of the file would be identical to the schema of the target where the data is being imported.
- The second argument is the name of the source file with the full file path from where the data is required to be imported.
- As the source file format can be of different types, the next logical format in the flow becomes, the type of file i.e. CSV / DAT / etc., though it's optional. After specifying the file format, depending upon the type of the file, you may want to specify the row delimiter and column delimiter. In case of a CSV file, the column delimiter can be a comma and the row delimiter can be a new line character.
- Once the information about the source schema is specified, the next step would be to specify options about the target. Generally, in a flat file, the only schema you would find in a format like CSV is column headers which is the first row of the file. So, one may want to skip the first row and start from the 2nd row. This can be specified by the FIRSTROW option. In a similar way, you can also specify the LASTROW parameter to signal the boundary of the load.
- Once the load starts it can take quite some time to load the data, and we may want to commit a certain number of records in one transaction, so in case of a failure everything does not get rolled back. This can be specified by the BATCHSIZE parameter. Other options like ROWS_PER_BATCH, KILOBYTES_PER_BATCH, ORDER can also be used to optimize the performance of the bulk load.
- On the target table or view where the load is being performed, one may have specified constraints and/or triggers, for example an INSERT trigger. During bulk insert of data, these triggers won't execute unless explicitly specified as this can jam the system. If you want to have the trigger execute on every transaction, you can specify the FIRETRIGGERS parameter, which will execute the trigger for every transaction and in case of a batch-wise load it will execute for every batch. You can optionally specify additional parameters like KEEPIDENTITY and KEEPNULLS.
- During the load if you want to place an exclusive lock on the table so that the load can continue without any contention and users do not see phantom rows, you can use the TABLOCK parameter.
- Finally, during load, errors can occur due to type conversion, invalid row format and many other reasons. You can specify after how many errors you want the to load to stop, by using the MAXERRORS parameter. The default value is 10.
Below is the general syntax for the command.

Having understood the syntax of BULK INSERT, now it's time to test it in practice.
Load Data into SQL Server with BULK INSERT
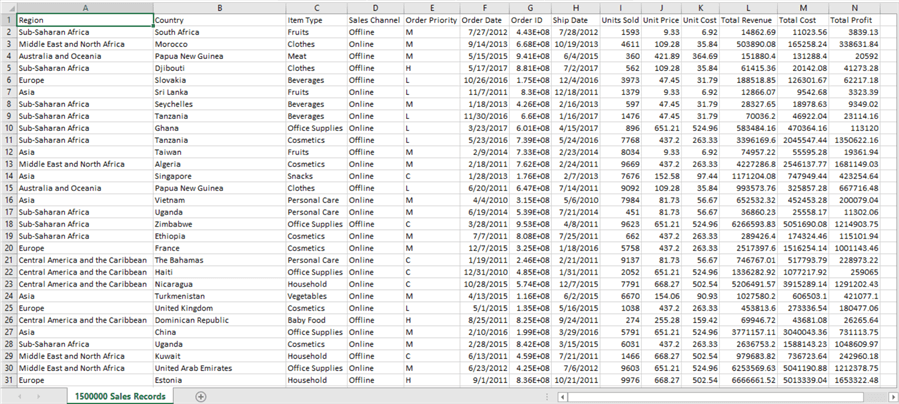
First, we need a large set of sample data in a file format that can be used to insert the data into SQL Server. You can download a large sample file from here. This is a freely available zipped CSV file that contains 1.5 million records, which is reasonable volume to import into SQL Server for testing BULK INSERT. Once you download and open this file, it should look as shown below.
Create Target Table
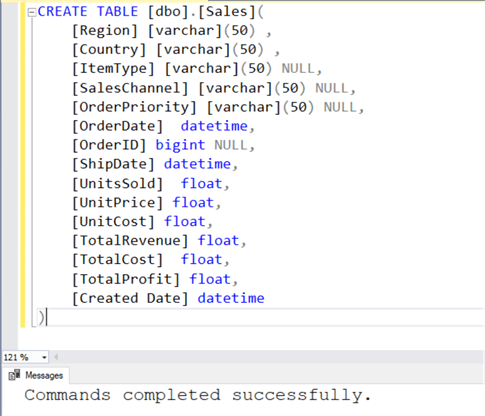
We have the source data in a ready format. We need to create a target to load this data. One way is to create a table having the identical schema as the source. But in real world scenarios, often there are more fields in the schema, at least for auditing like created date, updated date, etc. So, let's create a table having all the above fields, and at least one additional field for auditing like created data as shown in the below script.
CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float, [Created Date] datetime )
Open SSMS, modify the above script as needed and execute in the context of database where you want to create the target table as shown below.
Run BULK INSERT Command
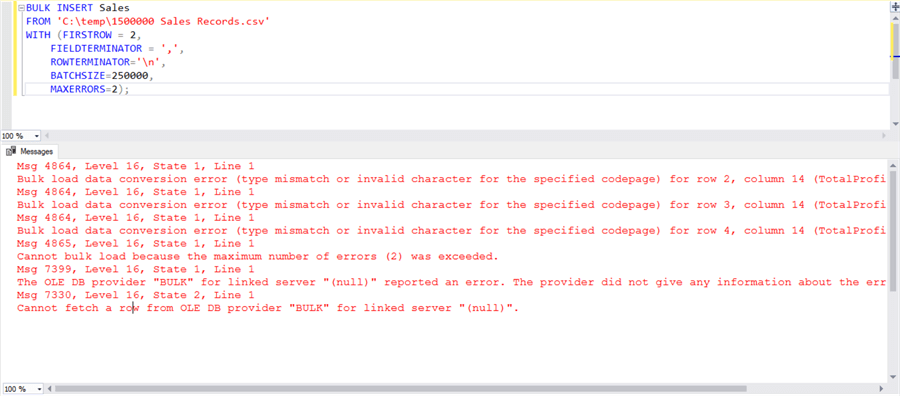
Our source and target are ready, so now we can fire the BULK INSERT command. We already learned about the syntax, so you should be able to understand what we are trying to do in the below script. Ensure that the path is correct where you have placed your CSV file. For testing purposes, I have set maximum errors to 2.
BULK INSERT Sales
FROM 'C:\temp\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
BATCHSIZE=250000,
MAXERRORS=2);
Execute this script and you would find the errors shown below. The primary reason is that we have an extra field (Created Date) in the target schema which is not in the source. Due to that, during the load we encountered multiple errors, and after two errors the load process was terminated as it crossed our threshold of the 2 error max.
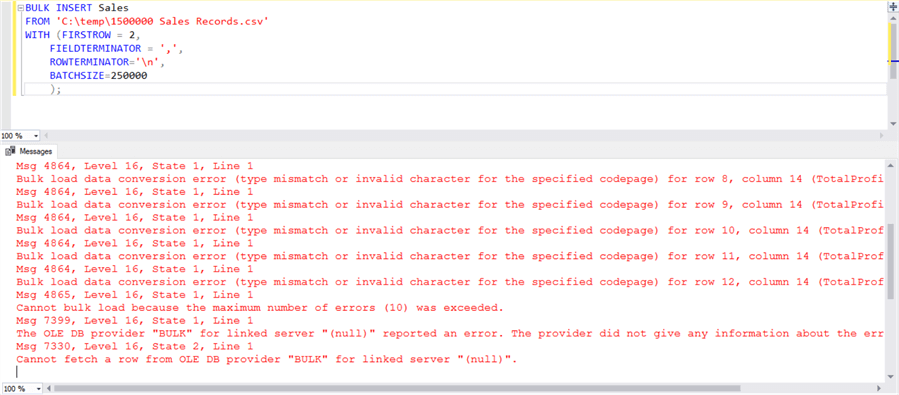
If you remove the max error argument, it will stop at 10 errors as it will use the default value. The max error argument can prove to be very useful where each row in the load is going to fail.
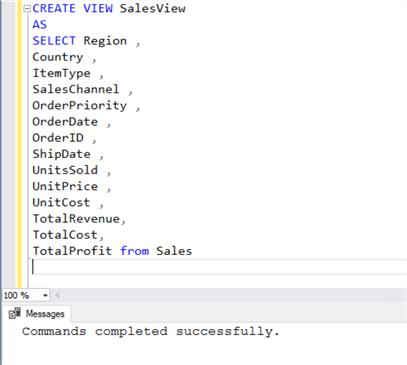
Right at the start of the tip we learned that we can load data in a table or view, as shown in the syntax. So, let's create a view that has a schema identical to the source file, as shown below. I have named the view SalesView, so that during the load we can be sure that we are using the view to bulk load the data and not the actual table.
CREATE VIEW SalesView
AS
SELECT [Region]
,[Country]
,[ItemType]
,[SalesChannel]
,[OrderPriority]
,[OrderDate]
,[OrderID]
,[ShipDate]
,[UnitsSold]
,[UnitPrice]
,[UnitCost]
,[TotalRevenue]
,[TotalCost]
,[TotalProfit]
FROM [dbo].[Sales]
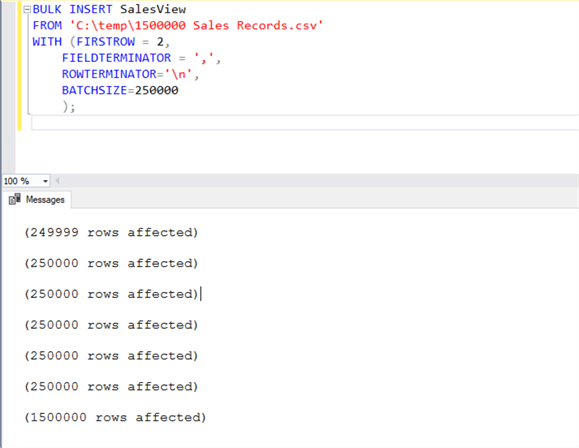
After creating the view, run the same script again, but first change to the view name instead of the table name. Once you execute the script, it may take a few seconds and you will see the data getting loaded in increments of 250,000. This is an effect of the BATCHSIZE parameter that we specified while executing the BULK INSERT statement.
BULK INSERT SalesView
FROM 'C:\temp\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
BATCHSIZE=250000);
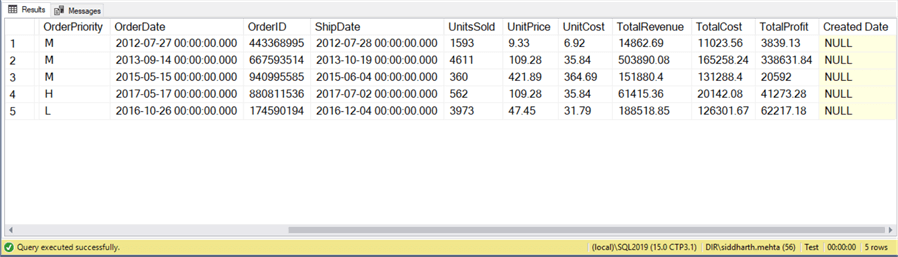
After the data is inserted you can select a few records and you will find that the data was loaded as expected and the created date field has empty values, as we neither provided a default value for it nor a computed formula.
SELECT TOP 5 * FROM [dbo].[Sales]
In this way, using the BULK INSERT statement one can easily import data from an external source very easily into SQL Server just with a single statement.
Next Steps
- Consider testing other options available with the BULK INSERT statement with different file formats to exploit the maximum potential of this statement.






About the author
 Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.
Siddharth Mehta is an Associate Manager with Accenture in the Avanade Division focusing on Business Intelligence.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-03-02
