By: Jeffrey Yao | Updated: 2019-09-11 | Comments (5) | Related: > TSQL
Problem
In my work I sometimes need to import csv files and one column of the csv file is an alphanumeric string, with values like the following:
| Code |
|---|
| Abc3.1xy2m |
| Abc10.12xy1a |
| Abc1.2xy31b |
| Abc1.10xy31c |
| Abc1.0xy1b |
| Abc10.2xy2a |
| Abc3.1xy11m |
Once the data is loaded into a table, the values will be presented in a report, where the column [Code] needs to be sorted as follows. Each numeric part of the file has significance, so they data needs to sort as follows:
| Code |
|---|
| Abc1.0xy1b |
| Abc1.2xy31b |
| Abc1.10xy31c |
| Abc3.1xy2m |
| Abc3.1xy11m |
| Abc10.2xy2a |
| Abc10.12xy1a |
Using an ORDER BY in SQL Server will give the following results which is not the same as above:
| Code |
|---|
| Abc1.0xy1b |
| Abc1.10xy31c |
| Abc1.2xy31b |
| Abc10.12xy1a |
| Abc10.2xy2a |
| Abc3.1xy11m |
| Abc3.1xy2m |
How can this be done with T-SQL?
Solution
When sorting alphanumeric strings, we will extract all numbers and have two types of strings:
- Strings composed of non-digits, let's call this S-string, we may have multiple S-strings.
- Strings composed of digits 0 to 9, i.e. such string can be converted to numbers, and let's call this N-string, and we may have multiple N-strings.
Sorting Strings in SQL Server with T-SQL
For example, "Abc1.2xy31b" and "Abc1.10xy31c" can be decomposed to the following strings (S1 means 1st S-string and N3 means the 3rd N-string)
| Original | S1 | N1 | S2 | N2 | S3 | N3 | S4 |
|---|---|---|---|---|---|---|---|
| Abc1.2xy31b | Abc | 1 | . | 2 | xy | 31 | b |
| Abc1.10xy31c | Abc | 1 | . | 10 | xy | 31 | c |
When we compare these two strings, in the N2 column, we know that as a number, 2 is smaller than 10, so for these two strings, "Abc1.2xy31b" should be smaller than "Abc1.10xy31c". But if the strings are compared directly, because string "2" is bigger than string "10", "Abc1.2xy31b" should be bigger than "Abc1.10xy31c".
Let's see this in T-SQL.
use tempdb
go
drop table if exists #t; -- applicable to sql server 2016+gogo
create table #t (a varchar(100));
go
insert into #t (a) values ('Abc1.2xy31b'), ('Abc1.10xy31c')
go
select * from #t order by a asc
If we run the query, we will get the following, i.e. "Abc1.2xy31b" is at the bottom of the returned result set via the "order by a asc", meaning "Abc1.2xy31b" is considered "bigger" in value compared to "Abc1.10xy31c".
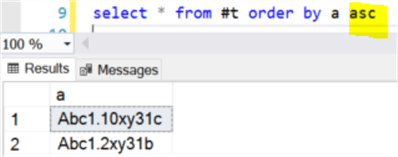
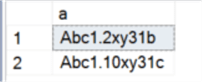
This is NOT what we want, we want the following result set instead when we use "order by a asc", because the second set of numeric values are "2" and "10" and "2" should come before "10".
Sorting Rules Defined
Our sorting rule will be such that when in comparison, all alphanumeric strings will be decomposed into S strings and N strings in their original sequence, and if S strings are the same, then the N strings need to be compared and we will compare the numeric values of N strings.
Now let's look at a simple comparison of the following two strings:
- 10-abc
- 2-abc
According to our rule, if we sort the two string in ascending order, we should have this, but this is not possible in T-SQL in its natural way.
- 2-abc
- 10-abc
On the other hand, if we change the string as follows, i.e. pad 0 to the left of the numeric string to make the numeric strings be the same length:
- 0010-abc
- 000002-abc
If the strings are like this, then when we use the order by clause in T-SQL to get the desired results:
- 0002-abc
- 0010-abc
The demo T-SQL code is as follows:
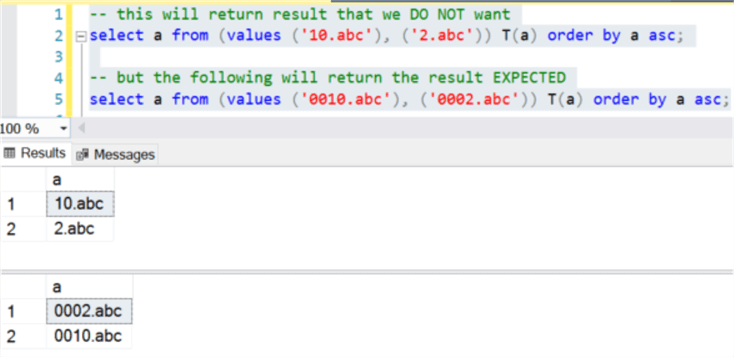
-- this will return result that we DO NOT want
select a from (values ('10.abc'), ('2.abc')) T(a) order by a asc;
-- but the following will return the result EXPECTED
select a from (values ('0010.abc'), ('0002.abc')) T(a) order by a asc;
SQL Server T-SQL User Defined Function to Order Numbers within a String
So the algorithm to make "10.abc" and "2.abc" strings to be in the order expected via T-SQL can be designed as follows.
For each N string inside the source string, we will pad 0 to the left of the N string to make the N string length to be bigger than the largest N string length inside the source string.
For example, if we have an alphanumeric string like the following:
- Abc_1.2.34_xy56789-mn
The longest N string of this source string is "56789", if we pad 0 to each of the N string to make each N string to have a length of 6, we will get the following new source string:
- Abc_000001.000002.000034_xy056789-mn
This is like standardizing all strings for comparison, and once all strings are "standardized", we can sort the strings to get the expected result.
So the key here is to come up with a solution to standardize all source strings. I created a user defined function (UDF), it will accept three parameters:
- 1st is the source string,
- 2nd is length of the numeric string after padding
- 3rd parameter is the letter to be padded. This can be omitted as we can use '0' as the default, but I left it there so we can have more flexibility, for example, we can use '9' as default, and this will cause the sorting in descending order.
Here is the UDF, it will search through the source string @src, and pad specified letter @letter to the left of N string to make the final N string to be of length = @plen.
use tempdb -- change to your own db or master
go
drop function if exists dbo.udf_ExpandDigits;
go
-- function: standardize alphanumeric string by left padding 0 to the numeric string inside @src
-- we assume source string to be less than 1K in length (you can change it if needed)
-- example
-- select dbo.udf_ExpandDigits('a1-bc23-def456-ghij', 5, '0') will return
-- a00001-bc00023-def00456-ghij
create function dbo.udf_ExpandDigits(@src varchar(1024), @plen int, @letter char(1))
returns varchar(max)
as
begin
if @plen >= 100
return @src;
declare @p int, @p2 int, @num varchar(100);
declare @ret_val varchar(max)='';
if (PATINDEX('%[0-9]%', @src) =0 )
set @ret_val = @src;
else
begin
set @p = patindex('%[0-9]%', @src);
while(@p > 0)
begin
set @p2=patindex('%[^0-9]%', substring(@src, @p, 1000))
if (@p2 > 0)
begin
set @num=substring(@src, @p, @p2-1);
set @ret_val += left(@src, @p-1) + case when len(@num) < @plen then right(replicate(@letter, @plen) + @num, @plen) else @num end; ;
set @src = substring(@src, @p+@p2-1, len(@src));
set @p = patindex('%[0-9]%', @src);
end
else
begin
set @num = substring(@src, @p, len(@src));
set @ret_val += left(@src, @p-1)+ case when len(@num) < @plen then right(replicate(@letter, @plen) + @num, @plen) else @num end;
set @src ='';
break;
end
end -- while (@p > 0)
if len(@src) > 0
set @ret_val += @src;
end -- else
return @ret_val;
end -- function
go
-- example:
-- select dbo.udf_ExpandDigits('a1-bc23-def456-ghij', 5, '0')
The key details of the algorithm is described as below:
- Search the position of the first numeric letter and if not found, just return the original @src string
- If a numeric value (i.e. 0 – 9) is found, mark its position as @p
- Starting from @p, find the next non-numeric letter, if found, mark its position as @p2 and then retrieve the number between @p and @p2-1, pad the letter @letter to the left of this extracted number so the whole number's length is @plen. Reset @src string to start from the end of the number and then repeat step 3
- If not found, i.e. from @p to the end of the @src string, it is a whole number, then extract this number, pad the letter @letter to the left of this extracted number so the whole number's length is @plen, and set @src to empty string and exit the loop of step 3.
Test the User Defined Function to Order Numbers within a String
We will use the data below and do the sorting test. Here is the code to create the sample data:
use tempdb -- script run in a SQL Server 2016
go
drop table if exists #t;
go
create table #t (id int identity, code varchar(50));
go
-- populate the sample data
insert into #t (code) values
('Abc3.1xy2m')
, ('Abc10.12xy1a')
, ('Abc1.2xy31b')
, ('Abc1.10xy31c')
, ('Abc1.0xy1b')
, ('Abc10.2xy2a')
, ('Abc3.1xy11m');
go
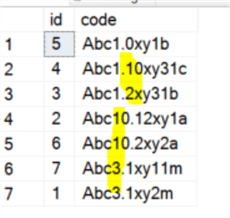
If we do a query with order by [code] asc:
select id, [code] from #t order by [code] asc;
We get the following result, which is not what we want:
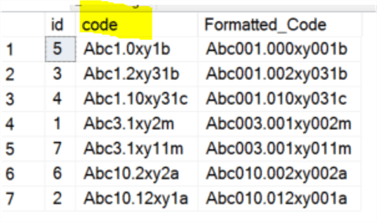
However if we do the following (computed column [Formatted_Code] is added for viewing converted data, but can be omitted):
select id, [Code], Formatted_Code=dbo.udf_ExpandDigits([code], 3, '0') from #t order by Formatted_Code asc
We can see the column [Code] is ordered the way we want.
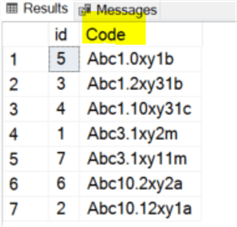
We can modify the query to the following (i.e. getting rid of the [Formatted_Code] column):
select id, [Code] from #t order by dbo.udf_ExpandDigits([code], 3, '0') asc;
and we get the following which is the result we want:
Summary
In this tip, we discussed how to order numeric values within alphanumeric strings using T-SQL, this technique is obviously not very efficient because the function needs to process the string value of each row in an internal loop, so when a table has millions of rows, this method will be very time-consuming.
But this alphanumeric string ordering is critical in some DBA daily operations, such as when we have multiple scripts stored in multiple folders, and the script names or folder names contain alphanumeric strings to indicate the execution sequence of each script. So ordering these scripts by full names (i.e. path + file name) for deployment is the first step for a successful deployment.
Next Steps
To improve the function mentioned in the tip, it is better to use a Regular Expression to find and extract numbers in a string. However, SQL Server T-SQL currently does not support Regular Expression, so we may implement a CLR function to utilize the powerful RegEx capability in T-SQL and this will surely improve the performance of our current T-SQL version function.
Please read the following related articles and share your own ideas about alphanumeric string sorting in T-SQL.






About the author
 Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.
Jeffrey Yao is a senior SQL Server consultant, striving to automate DBA work as much as possible to have more time for family, life and more automation.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-09-11
