By: Kenneth Igiri | Updated: 2019-10-09 | Comments (4) | Related: > Database Configurations
Problem
There are situations where a SQL Server databases is handed over to you and you find that the primary data file is unnecessarily huge. Such large data files may present management difficulties such as the case where you cannot take partial backups or you are unable to migrate data files smoothly using the detach and attach method.
Solution
One key solution is to identify the largest tables in your primary file group and rebuild the table(s), directing the data to another file group which you have created with multiple data files possibly on separate disks.
Note: Separate disks may mean different things to different people depending on whether you are using SAN or DAS.
Definitions
To better understand this article, the following definition of terms will help:
- Datafile – A physical file that contains the operating system blocks that hold your actual data. At its core, a database is a collection of data files.
- Filegroup – Filegroups in SQL Server are used to group data files together for administrative, data allocation and placement purposes. Filegroups provide an abstraction layer between database objects such as tables and indexes and the actual physical files sitting on the operating system.
Scenario
We have a SQL Server instance containing one user database called KairosTraining. This database has one table and one filegroup at the beginning of the engagement – the PRIMARY filegroup. The assumption is that we have a single very large file which we intend to split to four files by moving the data in the core tables to a new filegroup containing four data files.
Preparation
We start out by checking the facts of our environment. We capture the size of our data files and the size of the core table we will be dealing with using the scripts in Listing 1. We then capture the current filegroup of the core table. This is shown in Fig. 2. We also check the location of the data files and confirm that indeed we have just one large data file (See Fig. 3).

Fig. 1 - Tab1 Sitting on Primary Filegroup
--Listing 1: Check size of databases and tables in a SQL Server instance -- Check the Size of all databases use tempdb go create table #DatabaseSize (fileid int, groupid int, size int, maxsize int, growth int, status int,perf int,name varchar(50),filename varchar(100)) go insert into #DatabaseSize exec sp_msforeachdb @command1='select * from [?]..sysfiles;' go select name [DB File Name] ,filename [DB File Path],size*8/1024 [DB Size (MB)] from #DatabaseSize order by [DB Size (MB)] desc go drop table #DatabaseSize go -- Check the size of all Tables in the user Database use KairosTraining go create table tablesize (name varchar(100),rows int,reserved varchar(100),data varchar(100), index_size varchar(100), unused varchar(100)) go insert into tablesize exec sp_MSforeachtable 'exec sp_spaceused ''?''' go select name [Table Name], CAST(REPLACE(data,'KB','') AS int) [Data Size (KB)], CAST(REPLACE(index_size,'KB','') AS int) [Index Size (KB)] from tablesize order by [Data Size (KB)] desc go drop table tablesize go
Fig. 2 shows us the size of our master data file KairosTraining (in the primary filegroup). We see that this file is about 3GB in size. For the purpose of this demonstration we shall assume this is a very large file. Fig. 3 also shows us the size of the core table Tab1 along with the size of its clustered index.

Fig. 2 - Size of All Data files in the SQL Instance

Fig. 3 - Size of Table Tab1
Moving a Table to a Different SQL Server Filegroup
Once we have identified the table we need to move, we proceed with the method. In SQL Server, the simple way to move data to another filegroup is to rebuild the clustered index. Tables in SQL Server cannot have more than one clustered index. This makes sense because a clustered index is an ordered index and you cannot order the records of a table (a fixed structure) in more than one way. Listing 2 shows us how we can identify the clustered index sitting on table Tab1. We can also see this visually as shown in Fig. 5
--Listing 2: Check All Indexes on Tab1 select * from sys.indexes where object_name (object_id)='Tab1';

Fig. 4 - Output of Listing 2
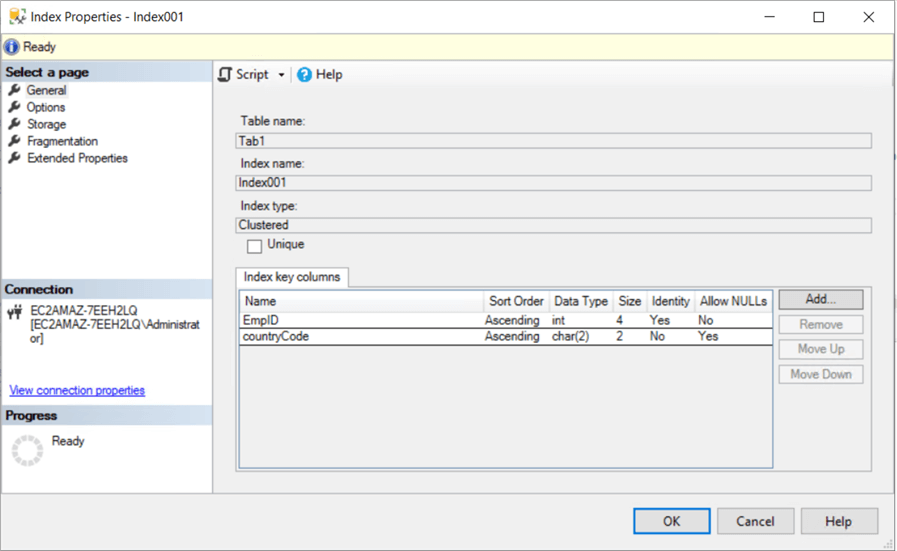
Fig. 5 - Clustered Index on Tab1
Using the code in Listing 3, we proceed to create a new filegroup called FG. We then add four data files to this new filegroup. Using the code in Listing 4, we rebuild the clustered index on table Tab1. Notice that we can easily reverse this by changing the name of the filegroup in the ON clause of the statement. Fig. 6 shows us the new data files that have been added to the database on filegroup FG.
--Listing 3: Create Filegroup FG USE [master] GO ALTER DATABASE [KairosTraining] ADD FILEGROUP [FG] GO USE [master] GO ALTER DATABASE [KairosTraining] ADD FILE ( NAME = N'KairosTraining01', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\KairosTraining01.ndf' , SIZE = 524288KB , FILEGROWTH = 524288KB ), ( NAME = N'KairosTraining01', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\KairosTraining02.ndf' , SIZE = 524288KB , FILEGROWTH = 524288KB ), ( NAME = N'KairosTraining01', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\KairosTraining03.ndf' , SIZE = 524288KB , FILEGROWTH = 524288KB ), ( NAME = N'KairosTraining01', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\KairosTraining04.ndf' , SIZE = 524288KB , FILEGROWTH = 524288KB ) TO FILEGROUP [FG] GO

Fig. 6 - New Datafiles on KairosTraining Database
--Listing 4: Create Filegroup FG USE [KairosTraining] GO DROP INDEX [Index001] ON [dbo].[Tab1] WITH ( ONLINE = OFF ) GO CREATE CLUSTERED INDEX [Index001] ON [dbo].[Tab1] ( [EmpID] ASC, [countryCode] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [FG] GO
Once we successfully rebuild the clustered index, we have effectively moved Tab1 to a new filegroup FG as shown in Fig. 7.

Fig. 7 - Tab1 Moved to Filegroup FG
Other Use Cases
The technique we have discussed is useful for splitting the data in one large data file to smaller data files but can also be used to achieve the following:
- To organize a set of tables such that you can execute Partial Backup operations for them in one step. This makes sense since they only way to ensure a table is sitting on a particular physical file is to move that table to a filegroup which contains those physical files.
- In order to move specific data to volumes with faster disks. This means, you may have identified tables which are hot tables and require more stringent response times. You may like to dedicate Flash Storage for such tables for instance. You simply create a filegroup with files sitting on this flash storage.
- To simply reorganize tables for better performance. Rebuilding clustered indexes is equivalent to reorganizing the table thus removing fragmentation assuming a large number of DML operations such as deletes have fragmented a large table.
Listing 5 shows the syntax for taking a Partial Backup of the FG Filegroup.
--Listing 5: Taking a Partial Backup of the FG Filegroup backup database KairosTraining filegroup='FG' to disk='C:\Backup\KairosTraining_Part_01', disk='C:\Backup\KairosTraining_Part_02', disk='C:\Backup\KairosTraining_Part_03', disk='C:\Backup\KairosTraining_Part_04' with stats=10;
Next Steps
- In this article, we have discussed the simple approach available in SQL Server to move tables from one filegroup to another. We also gave a background as to why we may want to do this – to have more manageable data file sizes and to be able to backup sets of large tables as Partial Backups. You can learn more about physical structures in SQL Server, Partial Backups and how SQL Server stores data in the following references:






About the author
 Kenneth Igiri is a Database Administrator with eProcess International S.A. Ecobank’s technology services hub. He has over eight years of experience with SQL Server and Oracle.
Kenneth Igiri is a Database Administrator with eProcess International S.A. Ecobank’s technology services hub. He has over eight years of experience with SQL Server and Oracle.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-10-09
