By: Aaron Bertrand | Updated: 2022-02-24 | Comments (3) | Related: > TSQL
Problem
Several years ago, I blogged about how you can reduce the impact on the transaction log by breaking delete operations up into chunks. Instead of deleting 100,000 rows in one large transaction, you can delete 100 or 1,000 or some arbitrary number of rows at a time, in several smaller transactions, in a loop. In addition to reducing the impact on the log, you could provide relief to long-running blocking. At the time, SSDs were just picking up traction, and newer technologies like Clustered Columnstore Indexes, Delayed Durability, and Accelerated Database Recovery didn't exist yet. So, I thought it might be time for a refresh to give a better picture of how this pans out in SQL Server 2019.
Solution
Deleting large portions of a table isn't always the only answer. If you are deleting 95% of a table and keeping 5%, it can actually be quicker to move the rows you want to keep into a new table, drop the old table, and rename the new one. Or copy the keeper rows out, truncate the table, and then copy them back in. But even when the purge is that much bigger than the keep, this isn't always possible due to other constraints on the table, SLAs, and other factors.
Again, if it turns out you have to delete rows, you will want to minimize the impact on the transaction log and how the operations affect the rest of the workload. The chunking approach is not a new or novel idea, but it can work well with some of these newer technologies, so let's put them to the test in a variety of combinations.
To set up, we have multiple constants that will be true for every test:
- SQL Server 2019, with four cores and 32 GB RAM (max server memory = 28 GB)
- 10 million row table
- Restart SQL Server after every test (to reset memory, buffers, and plan cache)
- Restore a backup that had stats already updated and auto-stats disabled (to prevent any triggered stats updates from interfering with delete operations)
We also have many variables that will change per test:
- Recovery model (simple or full)
- For simple, checkpoint in loop (yes or no)
- For full, log backup in loop (yes or no)
- Accelerated Database Recovery (on or off)
- Delayed Durability (forced or off)
- Table structure (rowstore or columnstore)
- Total number of rows to delete from the table (10% (1MM), 50% (5MM), 90%
(9MM))
- Of that total, number of rows to delete per loop iteration (all (so no loop), 10%, 1%)
- How often to commit transactions (0 (never), 10 (10% of the time), 100 (once))
This will produce 864 unique tests, and you better believe I'm going to automate all of these permutations.
And the metrics we'll measure:
- Overall duration
- Average/peak CPU usage
- Average/peak memory usage
- Transaction log usage/file growth
- Database file usage, size of version store (when using Accelerated Database Recovery)
- Delta rowgroup size (when using Columnstore)
Source Table
First, I restored a copy of AdventureWorks (AdventureWorks2017.bak, to be specific). To create a table with 10 million rows, I made a copy of Sales.SalesOrderDetail, with its own identity column, and added a filler column just to give each row a little more meat and reduce page density:
CREATE TABLE dbo.SalesOrderDetailCopy ( SalesOrderDetailID int IDENTITY, SalesOrderID int, CarrierTrackingNumber nvarchar(25), OrderQty smallint, ProductID int, SpecialOfferID int, UnitPrice money, UnitPriceDiscount money, LineTotal numeric(38,6), rowguid uniqueidentifier, ModifiedDate datetime, filler char(50) NOT NULL DEFAULT '' ); GO
Then, to generate the 10,000,000 rows, I inserted 100,000 rows at a time, and ran the insert 100 times:
INSERT dbo.SalesOrderDetailCopy ( SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid, ModifiedDate ) SELECT TOP(100000) SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid, ModifiedDate FROM Sales.SalesOrderDetail; GO 100
I did not create any indexes on the table; depending on the storage approach, I will create a new clustered index (columnstore half of the time) after the database is restored as a part of each test.
Automating Tests
Once the 10 million row table existed, I set a few options, backed up the database, backed up the log twice, and then backed up the database again (so that the log would have the least possible used space when restored):
ALTER DATABASE AdventureWorks SET RECOVERY FULL; ALTER DATABASE AdventureWorks SET AUTO_CREATE_STATISTICS OFF; ALTER DATABASE AdventureWorks SET AUTO_UPDATE_STATISTICS OFF; BACKUP DATABASE AdventureWorks TO DISK = 'c:\temp\awtest.bak' WITH INIT, COMPRESSION; BACKUP LOG AdventureWorks TO DISK = 'c:\temp\awtest.trn' WITH INIT, COMPRESSION; BACKUP LOG AdventureWorks TO DISK = 'c:\temp\awtest.trn' WITH INIT, COMPRESSION; BACKUP DATABASE AdventureWorks TO DISK = 'c:\temp\awtest.bak' WITH INIT, COMPRESSION;
Next, I created a Control database, where I would store the stored procedures that would run the tests, and the tables that would hold the test results (just the start and end time of each test) and performance metrics captured throughout all of the tests.
CREATE DATABASE [Control]; GO USE [Control]; GO CREATE TABLE dbo.Results ( TestID int NOT NULL, StartTime datetime2(7) NULL, EndTime datetime2(7) NULL ); CREATE TABLE dbo.Metrics ( dt datetime2(7) NOT NULL DEFAULT(sysdatetime()), cpu decimal(6,3), mem decimal(18,3), db_size decimal(18,3), db_used decimal(18,3), db_perc decimal(5,2), log_size decimal(18,3), log_used decimal(18,3), log_perc decimal(5,2), vstore decimal(18,3), rowgroup decimal(18,3) ); CREATE CLUSTERED COLUMNSTORE INDEX x ON dbo.Metrics;
Capturing the permutations of all the 864 tests I wanted to perform took a few tries, but I ended up with this:
;WITH bits(b) AS (SELECT * FROM (VALUES(0),(1)) ASbits(b)),
rec(model) AS (SELECT * FROM (VALUES('FULL'),('SIMPLE')) ASx(model)),
chk(chk) AS (SELECT * FROM bits),
logbk(logbk) AS (SELECT * FROM bits),
adr(adr) AS (SELECT * FROM bits),
dd(dd) AS (SELECT * FROM bits),
struct(struct) AS (SELECT * FROM (VALUES('columnstore'),('rowstore')) ASstruct(struct)),
rowtotal(rt) AS (SELECT * FROM (VALUES(10),(50),(90)) ASrowtotal(r)),
rowperloop(rp) AS (SELECT * FROM (VALUES(100.0),(10),(1)) ASrowperloop(r)),
committing(c) AS (SELECT * FROM (VALUES(0),(10),(100)) AScommitting(r))
SELECT TestID = IDENTITY(int,1,1),* INTO dbo.Tests
FROM rec
LEFT OUTER JOIN chk ON rec.model = 'SIMPLE'
LEFT OUTER JOIN logbk ON rec.model = 'FULL'
CROSS JOIN adr
CROSS JOIN dd
CROSS JOIN struct
CROSS JOIN rowtotal
CROSS JOIN rowperloop
CROSS JOIN committing;
As expected, this inserted 864 rows with all of those combinations.
Next, I created a stored procedure to capture the set of metrics described earlier. I am also monitoring the instance with SolarWinds SQL Sentry, so there will certainly be some other interesting information available there, but I also wanted to capture the important details without the use of any third party tools. Here is the procedure, which goes out of its way to produce all of the metrics for any given timestamp in a single row:
CREATE PROCEDURE dbo.CaptureTheMetrics
AS
BEGIN
WHILE 1 = 1
BEGIN
IF EXISTS(SELECT 1 FROM sys.databases WHERE name = N'AdventureWorks' AND state = 0)
BEGIN
;WITH perf_src AS
(
SELECT instance_name, counter_name, cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name LIKE N'%total server memory%'
OR (
[object_name] LIKE N'%:Resource Pool Stats%'
AND counter_name IN(N'CPU usage %', N'CPU usage % base')
AND instance_name = N'default')
OR (
counter_name IN(N'Log File(s) Size (KB)', N'Log File(s) Used Size (KB)')
AND instance_name = N'AdventureWorks')
),
cpu AS
(
SELECT cpu = COALESCE(100*(CONVERT(float,val.cntr_value) / NULLIF(base.cntr_value,0)),0)
FROM perf_src AS val
INNER JOIN perf_src AS base
ON val.counter_name = N'CPU usage %'
AND base.counter_name = N'CPU usage % base'
),
mem AS
(
SELECT mem_usage = cntr_value/1024.0
FROM perf_src
WHERE counter_name like '%total server memory%'
),
dbuse AS
(
SELECT db_size = SUM(base.size/128.0),
used_size = SUM(base.size/128.0) - SUM(val.unallocated_extent_page_count/128.0)
FROM AdventureWorks.sys.dm_db_file_space_usage AS val
INNER JOIN AdventureWorks.sys.database_files AS base
ON val.[file_id] = base.[file_id]
),
vstore AS
(
SELECT size = CONVERT(bigint,persistent_version_store_size_kb)/1024.0
FROM sys.dm_tran_persistent_version_store_stats
WHERE database_id = DB_ID(N'AdventureWorks')
),
rowgroup AS
(
SELECT size = SUM(size_in_bytes)/1024.0/1024.0
FROM AdventureWorks.sys.dm_db_column_store_row_group_physical_stats
),
loguse AS
(
SELECT log_size = base.cntr_value/1024.0,
used_size = val.cntr_value/1024.0
FROM perf_src as val
INNER JOIN perf_src as base
ON val.counter_name = N'Log File(s) Used Size (KB)'
AND base.counter_name = N'Log File(s) Size (KB)'
)
INSERT Control.dbo.Metrics
(
cpu,mem,db_size,db_used,db_perc,log_size,log_used,log_perc,vstore,rowgroup
)
SELECT cpu = CONVERT(decimal(6,3),cpu.cpu),
mem = CONVERT(decimal(18,3),mem.mem_usage),
db_size = CONVERT(decimal(18,3),dbuse.db_size),
db_used = CONVERT(decimal(18,3),dbuse.used_size),
db_perc = CONVERT(decimal(5,2),COALESCE(100*(CONVERT(float,dbuse.used_size)
/NULLIF(dbuse.db_size,0)),0)),
log_size = CONVERT(decimal(18,3),loguse.log_size),
log_used = CONVERT(decimal(18,3),loguse.used_size),
log_perc = CONVERT(decimal(5,2),COALESCE(100*(CONVERT(float,loguse.used_size)
/NULLIF(loguse.log_size,0)),0)),
vstore = CONVERT(decimal(18,3), vstore.size),
rowgroup = CONVERT(decimal(18,3),COALESCE(rowgroup.size, 0))
FROM cpu
INNER JOIN mem ON 1 = 1
INNER JOIN dbuse ON 1 = 1
INNER JOIN loguse ON 1 = 1
LEFT OUTER JOIN vstore ON 1 = 1
LEFT OUTER JOIN rowgroup ON 1 = 1;
END
-- wait three seconds, then try again:
WAITFOR DELAY '00:00:03';
END
END
GO
I put that stored procedure in a job step and started it. You may want to use a delay other than three seconds – there is a trade-off between the cost of the collection and the completeness of the data that may lean more one way than the other for you.
Finally, I created the procedure that would contain all the logic to determine exactly what to do with the combination of parameters for each individual test. This again took several iterations, but the final product is as follows:
CREATE PROCEDURE dbo.DoTheTest
@TestID int
AS
BEGIN
SET ANSI_WARNINGS OFF;
SET NOCOUNT ON;
PRINT 'Starting test ' + RTRIM(@TestID) + '.';
DECLARE @sql nvarchar(max);
-- pull test-specific data from Control.dbo.Tests
DECLARE @model varchar(6), @chk bit, @logbk bit,
@adr bit, @dd bit, @struct varchar(11),
@rt decimal(5,2), @rp decimal(5,2), @c tinyint;
SELECT @model = model, @chk = chk, @logbk = logbk, @adr = adr,
@struct = struct, @rt = rt, @rp = rp, @c = c
FROM dbo.Tests WHERE TestID = @TestID;
-- reset memory, cache, etc.
SET @sql = N'EXEC master.sys.sp_configure
@configname = N''max server memory (MB)'', @configvalue = 27000;
EXEC master.sys.sp_configure
@configname = N''max server memory (MB)'', @configvalue = 28000;
RECONFIGURE WITH OVERRIDE;
DBCC FREEPROCCACHE WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;';
EXEC sys.sp_executesql @sql;
-- restore database
SET @sql = N'ALTER DATABASE AdventureWorks SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE AdventureWorks
FROM DISK = ''c:\temp\awtest.bak'' WITH REPLACE, RECOVERY;';
EXEC sys.sp_executesql @sql;
-- set recovery model
SET @sql = N'ALTER DATABASE AdventureWorks SET RECOVERY ' + @model + N';';
EXEC sys.sp_executesql @sql;
-- set accelerated database recovery
IF @adr = 1
BEGIN
SET @sql = N'ALTER DATABASE AdventureWorks SET ACCELERATED_DATABASE_RECOVERY = ON;';
EXEC sys.sp_executesql @sql;
END
-- set forced delayed durability
IF @dd = 1
BEGIN
SET @sql = N'ALTER DATABASE AdventureWorks SET DELAYED_DURABILITY = FORCED;';
EXEC sys.sp_executesql @sql;
END
-- create columnstore index or rowstore PK
IF @struct = 'columnstore'
BEGIN
SET @sql = N'CREATE CLUSTERED COLUMNSTORE INDEX cci ON dbo.SalesOrderDetailCopy;';
END
ELSE
BEGIN
SET @sql = N'CREATE UNIQUE CLUSTERED INDEX pk
ON dbo.SalesOrderDetailCopy(SalesOrderDetailID);';
END
EXEC AdventureWorks.sys.sp_executesql @sql;
-- update stats, to be sure
SET @sql = N'UPDATE STATISTICS dbo.SalesOrderDetailCopy WITH FULLSCAN;';
EXEC AdventureWorks.sys.sp_executesql @sql;
-- log the start
INSERT dbo.Results(TestID, StartTime)
VALUES(@TestID, sysdatetime());
DECLARE @rc int = 10000000; -- we know there are 10 million rows in the table;
-- you would likely use COUNT(*) FROM dbo.table
DECLARE @RowsToDeleteTotal int = @rc * (@rt/100.0);
DECLARE @NumberOfLoops int = @RowsToDeleteTotal / (@RowsToDeleteTotal*@rp/100.0);
DECLARE @Top int = @RowsToDeleteTotal / @NumberOfLoops;
DECLARE @i int = 1, @commit bit = 0;
-- set up loop
WHILE @i <= @NumberOfLoops
BEGIN
IF ((@c = 10 AND @i % 10 = 1) OR (@c = 100 AND @i = 1)) AND @@TRANCOUNT = 0
BEGIN
BEGIN TRANSACTION;
END
SET @sql = N'DELETE TOP (@Top) AdventureWorks.dbo.SalesOrderDetailCopy
WHERE (@rt = 90.00 AND SalesOrderDetailID % 10 <> 0)
OR (@rt <> 90.00 AND SalesOrderDetailID % (@rc/@RowsToDeleteTotal) = 0);';
EXEC AdventureWorks.sys.sp_executesql @sql,
N'@Top int, @rt int, @rc int, @RowsToDeleteTotal int',
@Top, @rt, @rc, @RowsToDeleteTotal;
SET @commit = CASE WHEN ((@c = 10 AND (@i % 10 = 0 OR @i = @NumberOfLoops))
OR (@c = 100 AND @i = @NumberOfLoops)) THEN 1 ELSE 0 END;
IF @commit = 1 AND @@TRANCOUNT = 1
BEGIN
COMMIT TRANSACTION;
END
IF (@logbk = 1 OR @chk = 1) AND (@c = 0 OR @commit = 1)
BEGIN
-- run these twice to make sure log wraps
SET @sql = CASE WHEN @chk = 1 THEN N'CHECKPOINT; CHECKPOINT;'
ELSE N'BACKUP LOG AdventureWorks TO DISK = N''c:\temp\aw.trn''
WITH INIT, COMPRESSION;
BACKUP LOG AdventureWorks TO DISK = N''c:\temp\aw.trn''
WITH INIT, COMPRESSION;' END;
EXEC AdventureWorks.sys.sp_executesql @sql;
END
SET @i += 1;
END
-- log the finish
UPDATE dbo.Results
SET EndTime = sysdatetime()
WHERE TestID = @TestID
AND EndTime IS NULL; -- so we can repeat tests
IF @@TRANCOUNT > 0
BEGIN
COMMIT TRANSACTION;
END
END
GO
There is a lot going on there, but the basic logic is this:
- Pull the test-specific data (TestID and all the parameters) from the dbo.Tests table
- Give SQL Server a kick by making an sp_configure change and clearing buffers and plan cache
- Restore a clean copy of AdventureWorks, with all 10 million rows intact, and no indexes
- Change the options of the database depending on the parameters for the current test
- Create either a clustered columnstore index or a clustered B-tree index
- Update stats on the table manually, just to be sure
- Log that we have started the test
- Determine how many iterations of the loop we need, and how many rows to delete inside each iteration
- Inside the loop:
- Determine if we need to start a transaction on this iteration
- Perform the delete
- Determine if we need to commit the transaction on this iteration
- Determine if we need to checkpoint / back up the log on this iteration
- After the loop, we log that this test is finished, and commit any uncommitted transactions
To actually run the test, I don't want to do this in Management Studio (even on the same VM), because of all the output, extra traffic, and resource usage. I created a stored procedure and put this into a job also:
CREATE PROCEDURE dbo.RunAllTheTests
AS
BEGIN
DECLARE @j int = 1;
WHILE @j <= 864
BEGIN
EXEC Control.dbo.DoTheTest @TestID = @j;
END
END
GO
That took far longer than I'm comfortable admitting. Part of that was because
I had originally included a 0.1% test for rowperloop
which, in some cases, took several hours. So I removed those from the table a few
days in, and can easily say: if you are removing 1,000,000 rows, deleting 1,000
rows at a time is highly unlikely to be an optimal choice, regardless of any other
variables:

(While that seems to be an anomaly compared to most other tests, I bet that wouldn't be much faster than deleting one row or 10 rows at a time. And in fact it was slower than deleting half the table or most of the table in every other scenario.)
Performance Results
After discarding the results from the 0.1% tests, I put the rest into a second metrics table with the durations loaded:
SELECT
r.TestID,
duration = DATEDIFF(SECOND, r.StartTime, r.EndTime),
avg_cpu = AVG(m.cpu),
max_cpu = MAX(m.cpu),
avg_mem = AVG(m.mem),
max_mem = MAX(m.mem),
max_dbs = MAX(m.db_size),
max_dbu = MAX(m.db_used),
max_dbp = MAX(m.db_perc),
max_logs = MAX(m.log_size),
max_logu = MAX(m.log_used),
max_logp = MAX(m.log_perc),
vstore = MAX(m.vstore),
rowgroup = MAX(m.rowgroup)
INTO dbo.RelevantMetrics
FROM dbo.Results AS r
INNER JOIN dbo.Tests AS t
ON r.TestID = t.TestID
LEFT OUTER JOIN dbo.Metrics AS m
ON m.dt >= r.StartTime AND m.dt <= r.EndTime
WHERE t.rp <> 0.1
GROUP BY r.TestID, r.StartTime, r.EndTime;
CREATE CLUSTERED COLUMNSTORE INDEX cci_rm ON dbo.RelevantMetrics;
I had to use an outer join on the metrics table because some tests ran so quickly that there wasn't enough time to capture any data. This means that, for some of the faster tests, there won't be any correlation with other performance details other than how fast they ran.
Then I started looking for trends and anomalies. First, I checked out duration and CPU based on whether Delayed Durability (DD) and/or Accelerated Database Recovery (ADR) were enabled:
SELECT
delayed_dur = dd,
accelerated_dr = adr,
avg_duration = AVG(duration*1.0),
[max_duration] = MAX(duration),
avg_cpu = AVG(avg_cpu),
max_cpu = MAX(max_cpu)
FROM dbo.RelevantMetrics AS m
INNER JOIN dbo.Tests AS t ON t.TestID = m.TestID
GROUP BY dd, adr;
Results (with anomalies highlighted):

Seems like overall duration is improved, on average, about the same amount, when either option is turned on (or both – and when both are enabled, the peak is lower). There seems to be a duration outlier for ADR alone that didn't affect the average (this specific test involved deleting 9,000,000 rows, 90,000 rows at a time, in FULL recovery, on a rowstore table). The CPU outlier for DD also didn't affect the average – this specific example was deleting 1,000,000 rows, all at once, on a columnstore table.
What about overall differences comparing rowstore and columnstore?
SELECT struct, avg_duration = AVG(m.duration*1.0), [max_duration] = MAX(m.duration), avg_mem = AVG(m.avg_mem), max_mem = MAX(m.max_mem) FROM dbo.RelevantMetrics AS m INNER JOIN dbo.Tests AS t ON t.TestID = m.TestID GROUP BY struct;
Results:

Columnstore is 20% slower, on average, but required less memory. I also wanted to see the impact on data file and log file size and usage:
SELECT struct,
avg_dbsize = AVG(r.max_dbs),
avg_dbuse = AVG(r.max_dbp),
avg_logsize = AVG(r.max_logs),
avg_loguse = AVG(r.max_logp)
FROM dbo.RelevantMetrics AS r
INNER JOIN dbo.Tests AS t
ON r.TestID = t.TestID
GROUP BY t.struct;
Results:

Finally, on today's hardware, deleting in chunks doesn't seem to have the same benefits it once had, at least in terms of duration. The 18 fastest results here, and 72 of the fastest 100, were tests where all the rows were deleted in one shot, revealed by this query:
;WITH x AS
(
SELECT TOP (100) rp, duration,
rn = ROW_NUMBER() OVER (ORDER BY duration)
FROM dbo.RelevantMetrics AS m
INNER JOIN dbo.Tests AS t
ON m.TestID = t.TestID
INNER JOIN dbo.Results AS r
ON m.TestID = r.TestID
ORDER BY duration
)
SELECT rp,
SpotsInTop100 = COUNT(*),
FirstSpotInTop100 = MIN(rn)
FROM x
GROUP BY rp
ORDER BY rp;
Results:
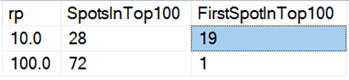
And if we look at averages across all of the data, as in this query:
SELECT TotalRows = t.rt, -- % of 10 MM
RowsPerLoop = t.rp,
avg_duration = AVG(r.duration*1.0)
FROM dbo.RelevantMetrics AS r
INNER JOIN dbo.Tests AS t
ON r.TestID = t.TestID
GROUP BY t.rt, t.rp
ORDER BY t.rt, t.rp;
We see that deleting all the rows at once, regardless of whether we are deleting 10%, 50%, or 90%, is faster than chunking deletes in any way (again, on average):
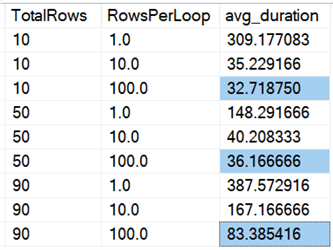
In chart form:
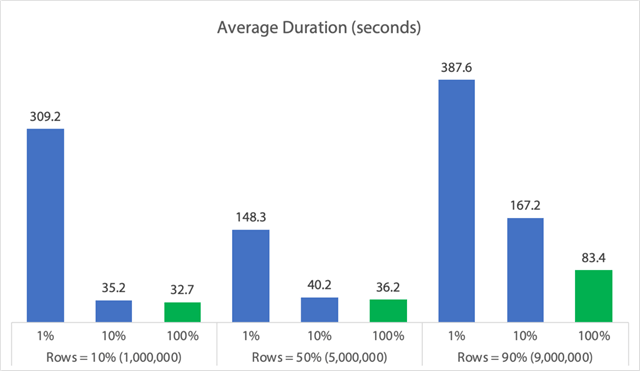
(Note that if we take out the 6,062 second max_duration outlier identified earlier, that first column drops from 309 seconds to 162 seconds.)
Now, even in the best case, that's still 33, 36, or 83 seconds where a delete is running and potentially blocking everyone else, and this is ignoring other measured impacts like memory, log file, CPU, and so on. Duration certainly shouldn't be your only criteria; it just happens that it's usually the first (and sometimes only) thing people look at. This test harness was meant to show that you can and should be capturing several other metrics, too, and the results show that outliers can come from anywhere.
Using this harness as a model, you can construct your own tests focused more narrowly on the constraints and capabilities in your environment. I didn't attack the metrics from all possible angles, since that's a lot of permutations, but I'm going to keep this database around. So, if there are other ways you want to see the data sliced up, just let me know in the comments below, and I'll see what I can do. Just don't ask me to run all the tests again.
Caveats
This all doesn't consider a concurrent workload, the impact of table constraints like foreign keys, the presence of triggers, and a host of other possible scenarios. Another thing to test (potentially in a future tip) is to have multiple jobs that interact with this same table throughout the operation, and measure things like blocking durations, wait types and times, and gauge in which situations one set of activity has a more dramatic impact on the other set.
Next Steps
Read on for related tips and other resources:
- CRUD Operations in SQL Server
- Differences between Delete and Truncate in SQL Server
- Deleting Historical Data from a Large Highly Concurrent SQL Server Database Table
- Break large delete operations into chunks
- SQL Server Clustered and Nonclustered Columnstore Index Example
- Delayed Durability in SQL Server 2014
- Delayed Durability while Purging Data
- Accelerated Database Recovery in SQL Server 2019






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-02-24
