By: Aleksejs Kozmins | Updated: 2019-12-16 | Comments (1) | Related: More > Integration Services Development
Problem
Not so long ago, I participated in a project to migrate a large volume of data from an obsolete mainframe-based system. It was performed in a multi-step delta operation where new data was transferred a bit at a time (two - five days) after the previous step. The total number of source tables exceeded 900 and many of the source tables were un-normalized and contained over 150 columns. We need to check the data row by row as well as column by column to make sure all of the data was transferred correctly.
Solution
The main target of the verification is to compare the values of every pair of identical columns within the compared records and in case of a mismatch to log the primary key value, column name and mismatched values in a verification log. The sample SSIS package illustrates the essence of the approach in a simplified way, using a local database without any remote connections.
Note: the data used to illustrate the approach are taken from the open access database WideWorldImporters. The data are copied to another database and simplified to make the explanation easier.
There are two tables to compare: InvoiceSource and InvoiceDW. Initially we will verify values only of one field 'ConfirmedReceivedBy'. The data in the InvoiceDW table are slightly updated so there is data to log in the verification log.
The main points of the suggested approach are as follows.
All data from table columns are grouped by their compatibility:
- All integer fields
- All decimal fields
- All varchar and char fields
- All date and datetime fields
Each group of fields having compatible data types is used to build a flow source using a UNION ALL statement.
Here is an example of a flow source from the table InvoicesSource. The source includes three columns of nvarchar type and a primary key column 'InvoiceID'.
SELECT 'dbo.InvoicesSource' AS TABLE_NAME, InvoiceID AS PK, 'ConfirmedReceivedBy' AS FIELD_NAME, ConfirmedReceivedBy AS FIELD_VALUE FROM dbo.InvoicesSource UNION ALL SELECT 'dbo.InvoicesSource' AS TABLE_NAME, InvoiceID AS PK, 'CustomerPurchaseOrderNumber' AS FIELD_NAME, CustomerPurchaseOrderNumber AS FIELD_VALUE FROM dbo.InvoicesSource UNION ALL SELECT 'dbo.InvoicesSource' AS TABLE_NAME, InvoiceID AS PK, 'CreditNoteReason' AS FIELD_NAME, CustomerPurchaseOrderNumber AS FIELD_VALUE FROM dbo.InvoicesSource --- and further with other fields of VARCHAR data type ORDER BY PK, FIELD_NAME
The same flow source SQL statement should be built for table 'InvoicesDW'.
Both these statements are included in the OLE DB source components of the Data Flow task to build the flows for the 'Merge Join' processing.
Sample Data Flow
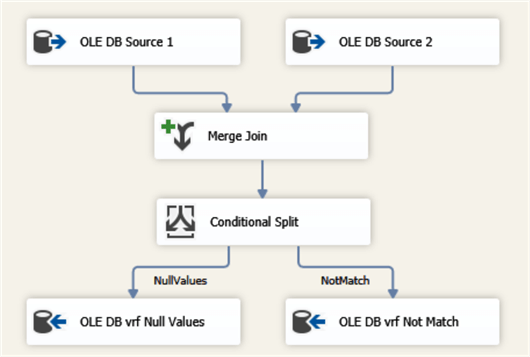
Fig.1. The verification Data Flow (basic version).
Here the source data flow where the OLE DB sources are merged using the primary key (PK) and FIELD_NAME as Join Keys (see Fig.2).
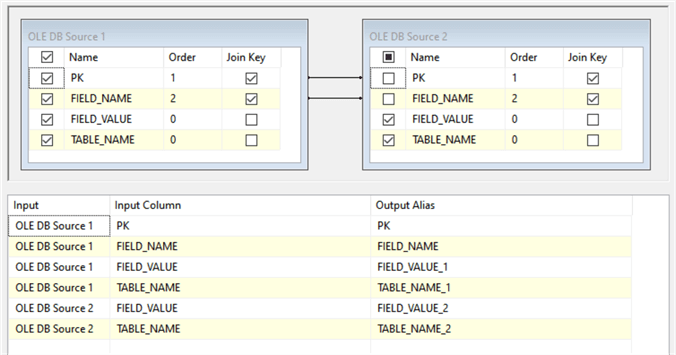
Fig 2. The Merge Join task for verification (initial version).
The joined records are analyzed in the Conditional Split task that compares the FIELD_VALUE data from both joined records (see Fig.3).
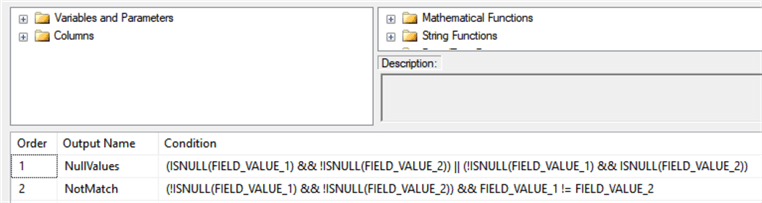
Fig 3. The data verification rules.
The task is intended to filter the mismatched values and direct them to the verification log.
There are two rules to detect the values mismatch:
- NullValues: one of the two values is empty and the other is not
- NotMatch: both non empty values are not equal
This two step mismatch check is done just for the sake of simple scripting.
The last fragment of the verification is the logging of the results (see Fig.4):
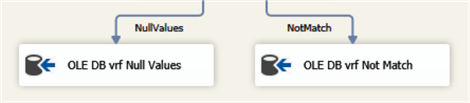
Fig.4. The logging of the mismatched values for both options.
The Verification Log and Logging
Generally speaking, the verification results can be reported in different forms. Our target is an automated approach to data verification using verification log suitable for different data types. That is why this log table has the following structure (see Fig.5):
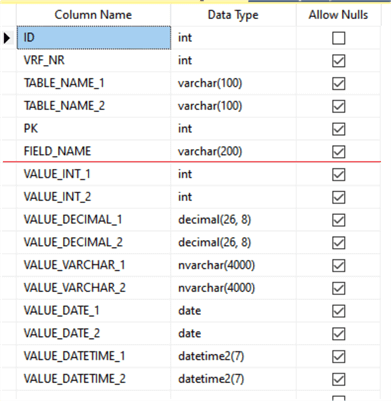
Fig.5. The structure of the VerificationLog table.
The common group of fields includes:
- VRF_NR: the verification run number (explained later)
- TABLE_NAME_1 and TABLE_NAME_2: the names of the verified tables
- PK: the primary key field
- FIELD_NAME: the verified field name.
The values group of fields consists of the pairs of fields having the same data type: VALUE_INT_1 and VALUE_INT_2, etc. Both verified fields have the same data type, so, in case of a mismatch both values are placed in appropriate fields of the given type.
In our case the verified values have a varchar data type, that is why the mapping section in both OLEDB destination tasks looks as follows:
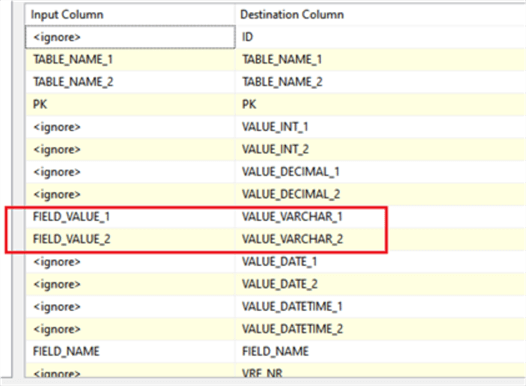
Fig.6 The structure of the verification log with fields for different data types.
In case of verification of another group of fields, e.g. integer type, the fields FIELD_INT_1 and FIELD_INT_2 should be filled in. The verification result containing discrepancies in the processed varchar data is shown in Fig.7.
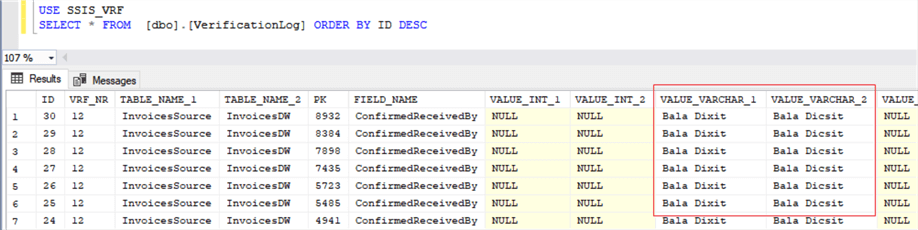
Fig.7. The fragment of the verification result.
The Metadata-based Approach
The described Data Flow task works as required, but composing SELECT … UNION ALL …statements when there are many and tables becomes a really tough and unproductive job. The right way is to build such statements automatically based on the metadata stored in the system table 'information_schema.columns' (see Fig.8):
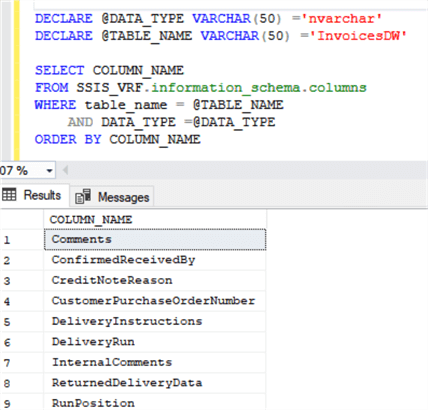
Fig. 8. The list of fields of the same data type from the InvoicesDW table.
The selected fields are included in the SELECT … UNION ALL… statements for both tables. When done, these strings should be used as dynamic SQL expressions in both OLEDB sources in the Data Flow task.
The Automated Verification Process
In general, the automation of the verification process can be achieved in the following way.
The first step of the verification process should be the generation of two SQL statements for source data flows based on the tables metadata. This step should be performed by a special stored procedure and the result should be transmitted to the Data Flow task through the SSIS package variables. The procedure should have the following input parameters:
- the names of the verified tables as two input parameters
- the group of compatible data types for the source flows of the verified data
This is the way to parameterize the verification process and to make it table independent. In this case, no change within the package is needed when it is applied to a new pair of tables.
A family of verification packages should be created, each for its own group of compatible data (integer, decimal, char/varchar, date/datetime). These packages should have similar structures. A new package can be created as a copy of the existing one with the following changes:
- A new group of data types should be specified and should be placed into a special package variable.
- For example, if the package focused on integer data verification this variable should have the following value: #int#smallint#tinyint#bigint#. For another package to verify date and datetime data this value is #date#datetime#datetime2#.
Here, all the basic data types are framed with the character '#' just to simplify the metadata processing.
The format of the output values in OLE DB source components should be updated for the new data types. The Fig.9 shows how the output format for FIELD_VALUE column is specified for varchar and integer.

Fig.9. The output data types specification in the OLE DB data sources for nvarchar and integer data.
The mapping of the verification results should be specified. As mentioned above, all the non-matched data should go to the fields having the appropriate data type (see Fig.10).
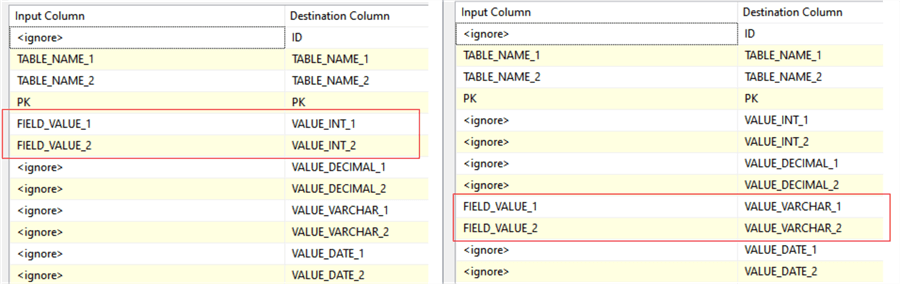
Fig.10. The mapping for non-matched values for different data types.
Implementation
The above described approach is illustrated by the set of SSIS packages given in the attached example DFT_VRF.zip.
This set consists of the following packages.
- VRF_0.dtsx. Includes only a Data Flow task with directly given SQL statements for source flows, intended to verify only data of nvarchar type.
- Three other packages – VRF_1_nvarchar.dtsx, VRF_2_datetime.dtsx, VRF_3_integer.dtsx – are focused on different groups of data. They are developed as table independent with a special stored procedure that builds the source SQL statements based on the tables metadata. The structure of one of these packages is shown below.
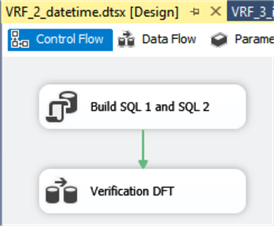
Fig.11. The structure of the package VRF_2_datetime.dtsx.
Here the first module calls a stored procedure dbo.BUILD_VRF_SQL that generates the SQL statements for source flows. The next module is the Data Flow task that accepts the generated source statements and performs the verification process.
To make the process fully parameterized, the verified tables and the primary key field should be passed to the package from the outside. The configuration table dbo.VRF_config is used for this purpose (see Fig.12).
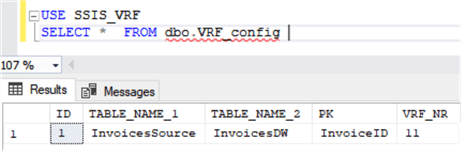
Fig.12. The structure and content of the configuration table.
Both verified tables and the primary key field given in this table are read by the stored procedure dbo.BUILD_VRF_SQL.
Therefore, to apply the verification to another pair of tables you only need to specify them in the configuration table.
The field VRF_NR is the order number of the verification run which is calculated incrementally.
Conclusion
In short, the main points of the suggested approach are as follows:
- The verification source flows are built as a combination of columns with compatible data types included in SELECT … UNION ALL… statement.
- The building of the source flows is automated and is based on the metadata of the verified tables.
The same result can be achieved using T-SQL only. I had such experience and comparing both approaches I can definitely say that the described one is more advantageous because of the following:
- The T-SQL implementation is based on complicated dynamic SQL statements, rather difficult in development and debugging. The SSIS based approach is simpler and more transparent.
- The SSIS package is more productive in processing of large tables than the T-SQL implementation.
- To verify the data of different data types the dynamic T-SQL scripts should be applied consistently to each of these types. As to the SSIS based approach, the packages for all groups of data types can be executed in parallel. It means that the verification of two tables can be performed in one run.
Setup Test Environment
To reproduce what is given in the article download DFT_VRF.zip and perform the following steps.
- Create and populate the training database with the SQL scripts given in CreateTrainingDB.zip.
- Run the SQL-scripts following the numbers in the file names.
- The created database should contain the following tables
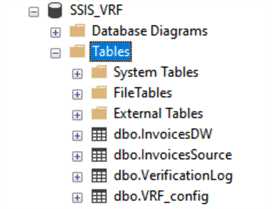
- and the stored procedure dbo. BUILD_VRF_SQL
- Create the folder C:\ SSIS_DFT_vrf and unzip SSIS_DFT_vrf.zip to this folder (see Fig.13).
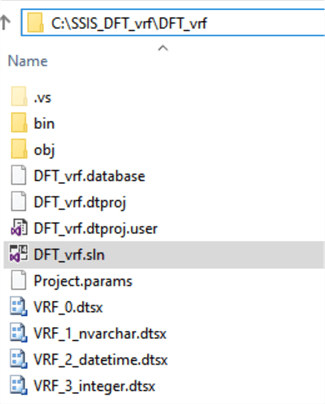
- Open VisualStudio, find and open C:\SSIS_DFT_vrf\SSIS_DFT_vrf.sln
- Open and execute the given SSIS packages:
- VRF_0.dtsx. Includes only a Data Flow task with directly given SQL statements to verify the data of nvarchar type.
- Other packages – VRF_1_nvarchar.dtsx, VRF_2_datetime.dtsx, VRF_3_integer.dtsx – are focused on different group of data.
- Check the verification results after execution of each package with the following T-SQL:
USE SSIS_VRF SELECT * FROM dbo.VerificationLog ORDER BY ID DESC
Next Steps
- Check out these other SSIS tips.






About the author
 Aleksejs Kozmins is a Data Warehousing and Business Intelligence professional, focused on efficient SQL Server Integration Services processes.
Aleksejs Kozmins is a Data Warehousing and Business Intelligence professional, focused on efficient SQL Server Integration Services processes.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2019-12-16
