By: Aaron Bertrand | Updated: 2020-01-06 | Comments (3) | Related: > Indexing
Problem
Recently Grant Fritchey lamented that
not enough people are using columnstore indexes. I thought about ways I've
found them useful, and I wrote up this quick tip as a simple use case to make
COUNT(*) queries less painful. Of course Brent Ozar
quite promptly
blogged about it first, but I thought I'd add my own perspective.
Solution
Because of their nature, a COUNT(*) query is only
as efficient as your skinniest (non-filtered) index. People often think the clustered
index is the most efficient index to use for any operation in SQL Server, but it
is actually the least efficient for tasks like this (it's often forgotten
that a clustered index contains every single column, not just the columns defined
in its key). A skinnier, non-clustered index is better, while a non-clustered columnstore
index can be the best, especially in SQL Server 2019. (Personally,
I still prefer the DMVs, but that's another story.)
Let's take a trivial example where we dump 5,000,000 arbitrary rows from the system catalogs into four tables:
SELECT TOP (5000000) c.*
INTO dbo.t1
FROM sys.all_columns AS c
CROSS JOIN sys.all_objects AS o ORDER BY NEWID();
SELECT * INTO dbo.t2 FROM dbo.t1;
SELECT * INTO dbo.t3 FROM dbo.t1;
SELECT * INTO dbo.t4 FROM dbo.t1;
Then we'll create a typical clustered index on each table:
CREATE CLUSTERED INDEX t1cix ON dbo.t1(object_id, column_id);
CREATE CLUSTERED INDEX t2cix ON dbo.t2(object_id, column_id);
CREATE CLUSTERED INDEX t3cix ON dbo.t3(object_id, column_id);
CREATE CLUSTERED INDEX t4cix ON dbo.t4(object_id, column_id);
We'll leave the first table as it is. We'll pick the smallest non-nullable
column in the table, is_filestream, which is defined
as bit NOT NULL. On t2
we'll create a non-clustered index on just that column; on
t3 we'll create a non-clustered columnstore index
there; and on t4 we'll create a non-clustered
columnstore index but use COLUMNSTORE_ARCHIVE compression:
CREATE INDEX nc1 ON dbo.t2(is_filestream);
CREATE NONCLUSTERED COLUMNSTORE INDEX ncci1 ON dbo.t3(is_filestream);
CREATE NONCLUSTERED COLUMNSTORE INDEX ncci2 ON dbo.t4(is_filestream)
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
Now, we'll make sure the cache is cold, and then execute a
COUNT(*) query against each table, both in SQL Server
2017 compatibility mode, and again in SQL Server 2019 compatibility mode. I'm
going to include the DMV queries for comparison.
SELECT /* sys.partitions */ SUM(rows)
FROM sys.partitions
WHERE object_id = OBJECT_ID('dbo.t1') AND index_id = 1;
GO
SELECT /* sys.dm_db_partition_stats */ SUM(row_count)
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('dbo.t1') AND index_id = 1;
GO
ALTER DATABASE floob SET COMPATIBILITY_LEVEL = 140;
DBCC DROPCLEANBUFFERS;
GO
SELECT /* 17 t1 */ COUNT(*) FROM dbo.t1;
GO
SELECT /* 17 t2 */ COUNT(*) FROM dbo.t2;
GO
SELECT /* 17 t3 */ COUNT(*) FROM dbo.t3;
GO
SELECT /* 17 t4 */ COUNT(*) FROM dbo.t4;
GO
ALTER DATABASE floob SET COMPATIBILITY_LEVEL = 150;
DBCC DROPCLEANBUFFERS;
GO
SELECT /* 19 t1 */ COUNT(*) FROM dbo.t1;
GO
SELECT /* 19 t2 */ COUNT(*) FROM dbo.t2;
GO
SELECT /* 19 t3 */ COUNT(*) FROM dbo.t3;
GO
SELECT /* 19 t4 */ COUNT(*) FROM dbo.t4;
GO
Now, don't get me wrong; these were all pretty fast, given what they were doing; I have a fast disk and six cores, and some wouldn't fare so well on less capable systems. Here are the initial duration and CPU times (milliseconds):
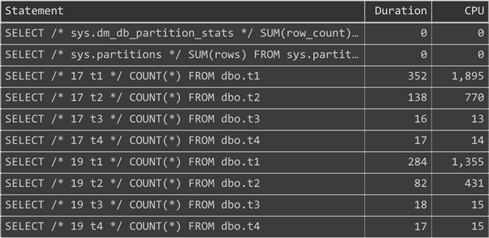
And here are runtime metrics from one execution in sys.dm_exec_query_stats:

Ignoring the DMV queries (where physical reads were 0, logical reads were ~10, and memory grant was <= 1MB), we can inspect each of the plans to see what is different.
2017 Compatibility Mode
In the first query against t1, we have a clustered
index scan in row mode with an I/O cost of 61.03
and a CPU cost of 1.83. Metrics captured above show that the physical
reads were over 165K, logical reads over 82K,
and that there was a very low memory grant of 104K.

The same query against t2 wisely used the non-clustered
index. It's still a scan, it's still in row mode, still
has a high I/O cost at 10.52, and has the same CPU cost of
1.83. Physical and logical reads were lower, at 28K
and 14K respectively, and the memory grant was again a
meager 104Kb.

The query against t3 used the columnstore index
and batch mode for all operators. The I/O and CPU costs were much
lower (0.003 and 0.55). Physical reads were a
lot lower, at 2.2K, and logical reads at 8.6K,
but the memory grant was higher at 4.8Kb.
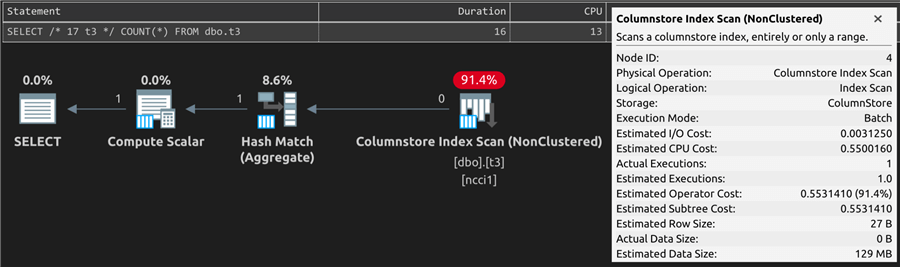
The plan for the query against t4 looks exactly
the same. And while the duration and CPU are far too short to reveal any differences,
we can see in the runtime metrics that physical and logical reads were way lower
(257 and 1,028) for the same memory grant as the
query against t3.
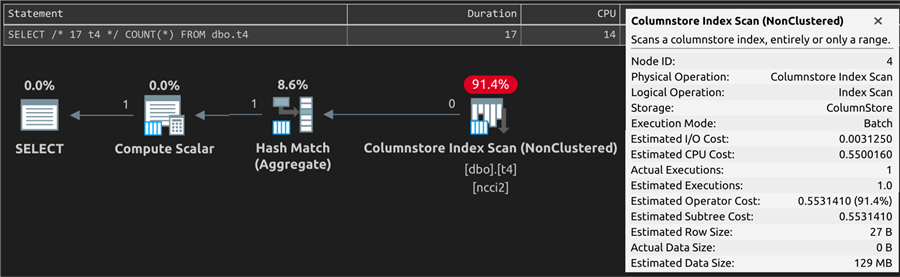
Quick summary: In 2017 compat level, a nonclustered columnstore index helps substantially with COUNT(*) queries.
2019 Compatibility Mode
In the first query against t1, we see that the
clustered index is still used for the count, because there isn't another index
to use. But you will note a major difference here: batch mode (I
talk a bit about
batch mode on rowstore in a previous tip).While the estimated
I/O and CPU costs are the same as before (61.03 and 1.83),
the duration is reduced by nearly 20%. The memory grant is slightly
higher, though, at 2.2MB.

Similarly, the query against t2 uses batch
mode to scan the non-clustered index, a benefit derived solely from the
2019 compat level. For a slightly higher memory grant (2.4MB),
and the same estimated costs as the first query against t2,
elapsed time is reduced by 30%.
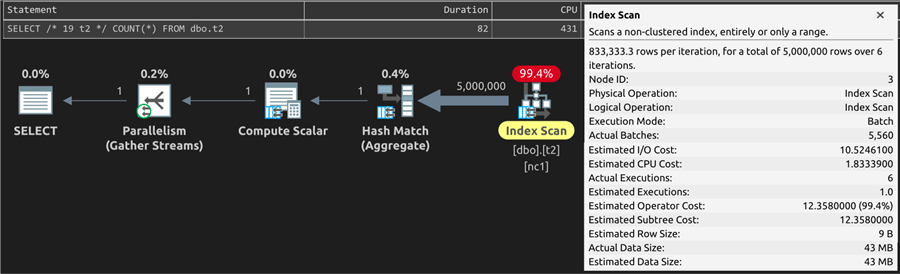
Included for completeness, the counts that use the columnstore:

One observation about the COLUMNSTORE_ARCHIVE compression
is that the plans don't account for this at all. I don't really trust
all of the metrics from the plans just yet; I think some of these properties haven't
adjusted to the inner workings of columnstore indexes. The estimated I/O cost for
the archive compressed columnstore, which looks like it should fit on about 80 pages,
is 0.003125; comparing that to the regular columnstore index, which
requires almost 1,000 pages (so the I/O costs should be way different), but it is
also estimated as 0.003125.

Quick summary: While 2019 compatibility level doesn't offer any additional
benefits to queries that can already take full advantage of batch mode for columnstore
indexes, it does offer substantial improvements to COUNT(*)
queries that can't use batch mode on rowstore indexes in earlier compat levels.
Caveats
There are a few things you should keep in mind:
- If you are upgrading to SQL Server 2019, also update the compat level to 150. Don't hold on to earlier compat levels, and make the new level a part of your testing process from the very beginning. A lot of the advanced changes they've made to query processing in SQL Server 2019 require the new compat level to have any effect whatsoever.
- If you're going to create a columnstore index to help satisfy
COUNT(*)queries, you should make sure that you choose a skinny, preferably non-nullable column that does not undergo modifications (so a create_date column would be a good candidate). Columnstore indexes are also most effective, generally, if the table doesn't experience a lot of deletes. - Some of the benefits of columnstore operations only work when all of the rowgroups are closed and compressed. You'll want to make sure you don't have any data sitting out in open, uncompressed delta stores. You can check for these using the following query:
SELECT
[table] = t.name,
[index] = i.name,
[state] = ps.state_desc,
row_count = SUM(ps.total_rows),
size_MB = CONVERT(DECIMAL(18,3), SUM(ps.size_in_bytes)/1024/1024.0)
FROM sys.dm_db_column_store_row_group_physical_stats AS ps
INNER JOIN sys.indexes AS I
ON ps.[object_id] = i.[object_id]
AND ps.index_id = i.index_id
INNER JOIN sys.tables AS t
ON t.[object_id] = i.[object_id]
WHERE i.type = 6 -- nonclustered columnstore
GROUP BY t.name, i.name, ps.state_desc
ORDER BY [table];
Ideally, all the values in [state]
will show as COMPRESSED.
Summary
If you are on (or are planning to move to) SQL Server 2017, and have costly
COUNT(*) queries, you should also consider implementing
columnstore indexes to reduce the pain of those queries. And if you are lucky enough
to be on SQL Server 2019, there are plenty of other benefits that you will just
"get
for free" under the newer compatibility level.
Next Steps
Read on for related tips and other resources:
- SQL Server Columnstore Indexes
- SQL Server 2016 Sort Order Batch Processing Mode
- What's New in the First Public CTP of SQL Server 2019
- Bad habits : Counting rows the hard way
- Why don't people use columnstore indexes?
- How to Make SELECT COUNT(*) Queries Crazy Fast
- Niko on Columnstore






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-01-06
