By: Aaron Bertrand | Updated: 2020-01-29 | Comments (5) | Related: > Availability Groups
Problem
I recently came across an issue in a SQL Server Availability Group scenario where queries against a heavily-used queue table were taking longer and longer over time. The symptoms of the query were that logical reads were increasing rapidly, and we ultimately tracked it down to ghost records (and version ghost records) that were being created as rows from the queue table were consumed and deleted. Because the database was being used in a readable secondary, the ghost cleanup process simply wasn't able to keep up with the volume of deletes against the table. The first workaround implemented was to suspend the queue consumers and rebuild the table.
Solution
Rebuilding was an acceptable trade-off to keep performance stable, but it could
certainly be disruptive, even with ONLINE = ON. One idea I had was
to perform a "soft delete" instead of a real delete, to reduce ghost and
version ghost records. You can't avoid these completely, but you can minimize
their impact.
A soft delete is when you have a column that you update when a row becomes invalid. So, given the following queue table (a copy of the original):
CREATE TABLE dbo.QueueTable_Copy
(
QueueID bigint IDENTITY(1,1) NOT NULL,
OrgID int NOT NULL,
Score decimal(4, 2) NOT NULL,
LastChange datetimeoffset(4) NULL,
QueueURL nvarchar(1024) NOT NULL,
PK_Column uniqueidentifier NOT NULL DEFAULT NEWID(),
CONSTRAINT PK_QueueTable_Copy PRIMARY KEY CLUSTERED (PK_Column)
);
GO
CREATE UNIQUE INDEX IX_QueueTable_Copy_QueueID ON dbo.QueueTable_Copy(QueueID);
GO
CREATE INDEX IX_QueueTable_Copy_Covering
ON dbo.QueueTable_Copy(OrgID, Score DESC, LastChange)
INCLUDE (QueueID, QueueURL);
GO
I added the following bit column with a default of 0:
ALTER TABLE dbo.QueueTable_Copy ADD IsDeleted bit NOT NULL DEFAULT 0;
Then I created an index on that column so that when a row becomes "deleted," you're writing an update only to the indexes where that column is a member, instead of deleting a row and leaving ghost records in every index (except filtered indexes where the row was already excluded). Here is the index definition:
CREATE INDEX IX_QueueTable_Copy_Deleted
ON dbo.QueueTable_Copy(PK_Column, IsDeleted)
WHERE IsDeleted = 1;
We can also change an existing covering index that satisfies the query that pulls
a new item off the queue, adding context for the new column IsDeleted:
CREATE INDEX IX_QueueTable_Copy_Covering
ON dbo.QueueTable(OrgID, IsDeleted, Score DESC, LastChange)
INCLUDE(QueueID, QueueURL)
WHERE IsDeleted = 0
WITH (DROP_EXISTING = ON);
Now, it's true, when you soft delete a row and that adds it to the first index, that same change removes it from the second (leaving a ghost record). But cleanup on these indexes should be much less painful, because you're not scattering ghost records all over a table that's clustered on a GUID; you're only adding those ghost records to one non-clustered index.
To deal with these ghost records on the smaller index, you can fine tune when you run the following maintenance (occasionally for infrequent impact, or frequently for minimal duration per run):
CREATE PROCEDURE dbo.QueueTable_Copy_Cleanup
AS
BEGIN
DELETE dbo.QueueTable_Copy WHERE IsDeleted = (SELECT 1);
-- trick to use skinnier, filtered index, in case of forced parameterization
DBCC FORCEGHOSTCLEANUP;
END
You’ll want to test this operation on a real-ish workload to determine the impact and appropriate frequency.
Testing
Now, I have a measly laptop, so I don't have the ability right here to test
this fully with the right AG setup that exists in our production environment. But
I tried to get as close as I could to simulate the problem; I turned off ghost cleanup
with global trace flag 661 and enabled both allow snapshot
isolation and read committed snapshot isolation database settings.
I made sure the table had plenty of rows that would actually get deleted in the
load test, and plenty of rows that would get ignored.
I populated this table with 1,500,000 arbitrary rows from sys.all_columns:
SET NOCOUNT ON;
GO
INSERT dbo.QueueTable_Copy(OrgID, Score, LastChange, QueueUrl)
SELECT a,b,c,d FROM (SELECT TOP (1000)
ABS(object_id), ABS(column_id % 99), sysdatetimeoffset(), 'http://'
FROM sys.all_columns ORDER BY NEWID()) x(a,b,c,d)
UNION ALL
SELECT a,b,c,d FROM (SELECT TOP (500)
245575913, ABS(column_id % 99), sysdatetimeoffset(), 'http://'
FROM sys.all_columns ORDER BY NEWID()) y(a,b,c,d);
GO 1000
Populating the original table was easier, since I just needed the same 1.5 million rows I already dumped into the first table. Don't worry, this was on a restored backup, not in production:
TRUNCATE TABLE dbo.QueueTable; INSERT dbo.QueueTable(OrgID, Score, LastChange, QueueURL) SELECT OrgID, Score, LastChange, QueueURL FROM dbo.QueueTable_Copy;
Next, I made two stored procedures to simulate the important part of the current queue-pulling logic:
CREATE PROCEDURE dbo.PickOneCurrent
@OrgID int = 245575913
AS
BEGIN
DECLARE @QueueID int, @QueueURL nvarchar(1024);
DECLARE @t Table (QueueID bigint, QueueURL nvarchar(1024));
;WITH x AS
(
SELECT TOP (1) QueueID, QueueURL
FROM dbo.QueueTable WITH (ROWLOCK, READPAST)
WHERE OrgID = @OrgID
ORDER BY Score DESC, LastChange
)
DELETE x
OUTPUT [deleted].QueueID , [deleted].QueueURL
INTO @t;
-- other logic with @t
END
GO
CREATE PROCEDURE dbo.PickOneNew
@OrgID int = 245575913
AS
BEGIN
DECLARE @QueueID int, @QueueURL nvarchar(1024);
DECLARE @t Table (QueueID bigint, QueueURL nvarchar(1024));
;WITH x AS
(
SELECT TOP (1) QueueID, QueueURL, IsDeleted
FROM dbo.QueueTable_Copy WITH (ROWLOCK, READPAST)
WHERE OrgID = @OrgID
AND IsDeleted = (SELECT 0) -- trick for filtered index even under forced param
ORDER BY Score DESC, LastChange
)
UPDATE x SET IsDeleted = 1
OUTPUT [deleted].QueueID , [deleted].QueueURL
INTO @t;
-- other logic with @t
END
GO
Next, I set up a batch to log and monitor the workload I would throw at this. Using a simple logging table:
CREATE TABLE dbo.Logging
(
EventTime datetime2 NOT NULL default sysdatetime(),
TableName sysname,
IndexId int,
PageCount int,
RecordCount int,
GhostRecordCount int,
VersionGhostRecordCount int
);
And then a simple batch that would loop, populate the logging table as the workload is running, and also trickle new rows into the table (to simulate more data being added to the queue):
SET NOCOUNT ON;
DECLARE
@table sysname,
@workload char(3) = 'old'; -- switch to 'new'
IF @workload = 'old'
BEGIN
SET @table = N'QueueTable';
INSERT dbo.QueueTable(OrgID, Score, LastChange, QueueURL)
SELECT TOP (5) 245575913, ABS(column_id % 99), sysdatetimeoffset(), 'http://'
FROM sys.all_columns ORDER BY NEWID();
END
IF @workload = 'new'
BEGIN
SET @table = N'QueueTable_Copy';
INSERT dbo.QueueTable_Copy(OrgID, Score, LastChange, QueueURL, IsDeleted)
SELECT TOP (5) 245575913, ABS(column_id % 99), sysdatetimeoffset(), 'http://', 0
FROM sys.all_columns ORDER BY NEWID();
END
INSERT dbo.Logging
SELECT sysdatetime(), @table, index_id, SUM(page_count), SUM(record_count),
SUM(ghost_record_count), SUM(version_ghost_record_count)
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(N'dbo.' + @table),
NULL, NULL , 'DETAILED')
GROUP BY index_id;
WAITFOR DELAY '00:00:01';
GO 10000
Then I opened two instances of (an older version of) SQLQueryStress and let them rip, one at a time, calling the old and new stored procedure 2,500 times each, using 200 threads, to simulate the high concurrency of the production queue table usage. The results after 500,000 iterations each:
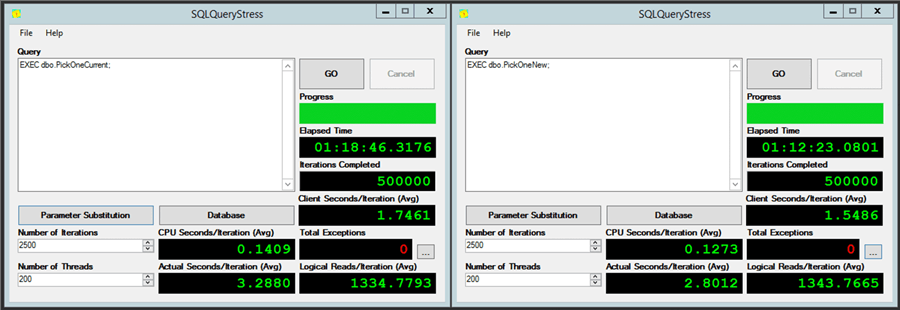
Throughput was slightly better with the filtered indexes and soft deletes, but
I was surprised logical reads stayed so high. Of course this didn't account
for other read queries against the queue and the more complex logic involved in
the readers. And this workload doesn't really account in either
case for the maintenance that will have to come at some point in the form of
ghost cleanup and/or index rebuilds. Though I did call the maintenance routine about
halfway through to see how it would impact things (the delete and FORCEGHOSTCLEANUP
in the new case, and just FORCEGHOSTCLEANUP in the old case).
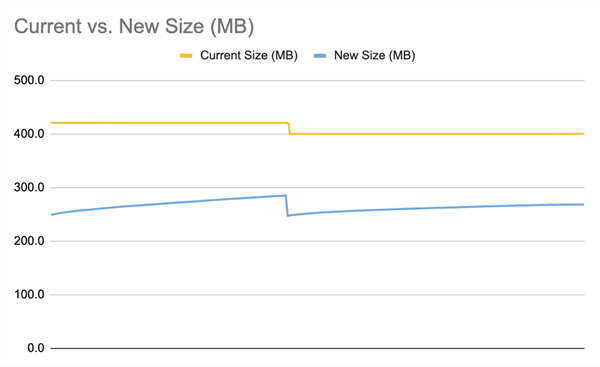
More interesting to me, though, were the results in the logging table. In these charts, orange represents the metrics for the current, delete-on-select model, and blue represents the new, soft delete approach. The point at which I called the maintenance routine in each workload should be obvious, though I did have to smooth out the curves a little because, in the new approach, overall system resource usage was lower — as a result, I was able to capture almost twice as many samples.
First, the overall size, as you might expect, is smaller with the filtered indexes, but it does creep up over time during the workload. The non-filtered indexes stayed the same size throughout (save for the drop after the cleanup):
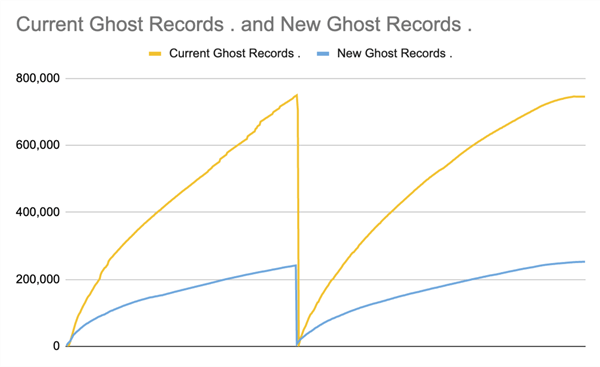
The impact to ghost records is profound, but when you think about it, updating a value that is the predicate for inclusion in a single index, versus deleting the entire row across all indexes, is going to lead to about 66% fewer ghost records (and they’re smaller, to boot):
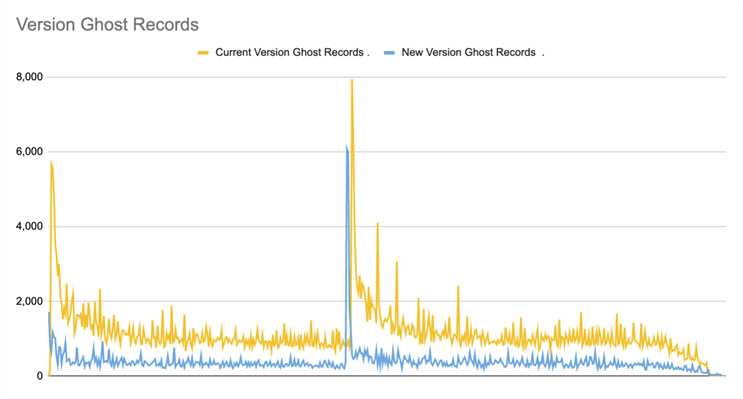
And finally, version ghost records are significantly lower in the soft delete scenario as well, but the pattern is a little more erratic:
Conclusion
Nothing is free. But if you find you are constantly losing ground because ghost records can't be cleaned up quickly enough, one thing that can help is to reduce the number of ghost records you are creating. In my situation, this seemed to help all around — it made a minor improvement to queue table throughput and, more importantly, significantly slowed the rate of ghost record creation. Without running this change in a full-on production workload, and of course knowing nothing about your scenario, I can't guarantee that the impact will be exactly on this order. But it is roughly what I predicted when I first floated the idea, except for similar logical read figures, which I do plan to investigate.
Next Steps
Read on for related tips and other resources:
- Processing Data Queues in SQL Server with READPAST and UPDLOCK
- SQL Server Filtered Indexes What They Are, How to Use and Performance Advantages
- How to Overcome the SQL Server Filtered Index UnMatchedIndexes Issue
- Using tables as Queues
- Dealing with Large Queues






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-01-29
