By: Ron L'Esteve | Updated: 2020-02-20 | Comments (4) | Related: > Azure Synapse Analytics
Problem
I currently have numerous parquet (snappy compressed) files in Azure Data Lake Storage Gen2 from an on-premises SQL Server that I had generated using my previous article, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2. Now I would like to fully load the snappy parquet files from ADLS gen2 into an Azure Synapse Analytics (SQL DW) table. I am familiar with Polybase and BULK INSERT options, but would like to explore Azure Synapse's new COPY INTO command which is currently in preview. How might I be able to get started with COPY INTO and load my ADLS gen2 files into an Azure Synapse Table?
Solution
Azure Synapse Analytics' new COPY INTO command offers numerous benefits including eliminating multiple steps in the data load process, and reducing the number of database objects needed for the process. Additionally, COPY INTO does not require CONTROL access to the sink SQL DW as with Polybase and only requires INSERT and ADMINISTER DATABASE BULK OPERATIONS permissions. At the time of writing this article, the COPY command is still in preview, however it is expected to become generally available in early 2020 and is also expected to have better performance than Polybase. In this article, I will demonstrate some common scenarios for using the COPY INTO command.
Features of the COPY INTO command
The COPY INTO command supports the following arguments. For more information, see: COPY (Transact-SQL) (preview).
FILE_TYPE = {'CSV' | 'PARQUET' | 'ORC'}
FILE_FORMAT = EXTERNAL FILE FORMAT OBJECT
CREDENTIAL = (AZURE CREDENTIAL)
ERRORFILE = http(s)://storageaccount/container]/errorfile_directory[/]
ERRORFILE_CREDENTIAL = (AZURE CREDENTIAL)
MAXERRORS = max_errors
COMPRESSION = { 'Gzip' | 'DefaultCodec'|'Snappy'}
FIELDQUOTE = 'string_delimiter'
FIELDTERMINATOR = 'field_terminator'
ROWTERMINATOR = 'row_terminator'
FIRSTROW = first_row
DATEFORMAT = 'date_format'
ENCODING = {'UTF8'|'UTF16'}
IDENTITY_INSERT = {'ON' | 'OFF'}
Prerequisites
There are a few expected pre-requisites that I will need prior to running the COPY INTO Command.
1) Azure Data Lake Storage Gen 2: For more information on creating an ADLS gen2 account to store source data, see: Create an Azure Storage account
2) Azure Synapse Analytics (SQL DW) & Destination Table: Azure Synapse will be used as the sink. Additionally, an Azure Synapse table will need to be created which matches the column names, column order, and column data types. For more information on creating Azure Synapse Analytics, see: Quickstart: Create and query an Azure SQL Data Warehouse in the Azure portal
3) Azure Data Factory V2: ADFv2 will be used as the E-L-T tool. For more information on creating a Data Factory, see: Quickstart: Create a data factory by using the Azure Data Factory UI.
Data Preparation
Data Preparation of the source data will be an important and necessary process prior to creating parquet files in ADLS gen2. Below are a few data preparation steps that I will need to complete to ensure that my parquet files are ready to be run through the COPY INTO command.
Remove spaces from the column names
I have often noticed issues with column names containing spaces while loading parquet files to Azure Synapse. These spaces in the column names can be handled by creating a view and assigning an alias to the columns containing spaces.
Alternatively, as a more complex solution, column name spaces can be eliminated on multiple source tables by leveraging the sys columns and sys tables with the following script:
For more information on implementing and using this script, see: SQL SERVER – Script: Remove Spaces in Column Name in All Tables
SELECT 'EXEC SP_RENAME ''' + B.NAME + '.' + A.NAME + ''', ''' + REPLACE(A.NAME, ' ', '') + ''', ''COLUMN'''
FROM sys.columns A
INNER JOIN sys.tables B
ON A.OBJECT_ID = B.OBJECT_ID
AND OBJECTPROPERTY(b.OBJECT_ID, N'IsUserTable') = 1
WHERE system_type_id IN (SELECT system_type_id
FROM sys.types)
AND CHARINDEX(' ', a.NAME) <> 0
Convert VARCHAR(MAX) to VARCHAR (4000)
For more information on Azure Synapse Analytics limits on data types and maximum values for various other components, see: Azure Synapse Analytics (formerly SQL DW) capacity limits.
From this article, I can see that the data type varchar(max) is currently unsupported in Azure Synapse and therefore, I will need to use the following syntax on my source on-premise system to convert varchar(max) to varchar (4000) datatypes. I can achieve this by either converting my source table or creating a view by using the syntax below.
Syntax:
CONVERT(VARCHAR(length), nvarchar_column_name)
Example:
SELECT column1 as column1, column2 as column2, CONVERT(VARCHAR(4000), nvarchar_column) as nvarchar_column FROM dbo.table_name
COPY INTO using PARQUET file
The preferred method of using the COPY INTO command for big data workloads would be to read parquet (snappy compressed) files using snappyparquet as the defined File_Format. Additionally, for this scenario, I will be using a Managed Identity credential.
Below is the COPY INTO SQL syntax for snappy parquet files that I ran in Azure Synapse.
COPY INTO [Table1]
FROM 'https://lake.dfs.core.windows.net/lake/staging/Table1/parquet/*.parquet'
WITH (
FILE_FORMAT = [snappyparquet],
CREDENTIAL = (IDENTITY='Managed Identity')
)
After running the command, the snappy parquet file was copied from ADLS gen2 into an Azure Synapse table in around 30 seconds per 1 million rows.
Additionally, after performing the Data Preparation step, I did not encounter any errors with the following data types: DATETIME, INT, NVARCHAR (4000).
Also, NULL ints, commas, and quotes in text fields were not an issue with this snappy parquet format.
COPY INTO using CSV file
Certain scenarios may require the source files to be in csv format. For this scenario, there is bit more set-up required on the source dataset.
I will begin by configuring a csv dataset in Azure Data Factory and will list the following connection properties.
- Column Delimiter: Comma (,)
- Row Delimiter: auto detect
- Encoding: Default (UTF-8). This will need to be set for csv files. Alternatively, the Encoding can be specified in the COPY INTO command syntax.
- Escape Characters: '' (NOTE that this setting will allow double quotes and commas in text fields)
- Quote Characters: Double Quote (") (NOTE that this setting will allow double quotes and commas in text fields)
- NULL Value: @concat('') (NOTE that this setting will allow NULL INT datatypes)
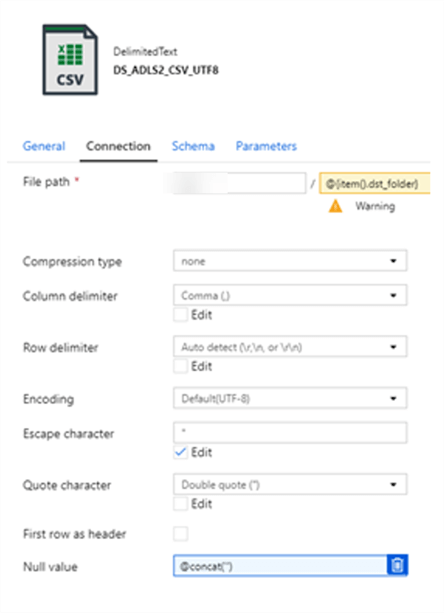
Below is the COPY INTO SQL syntax for csv files that I ran in Azure Synapse.
Note that I am also specifying the ENCODING as UTF8 in the syntax along with a FIELDTERMINATOR = ','
COPY INTO [Table1]
FROM 'https://sdslake.dfs.core.windows.net/lake/staging/Table1/csv/*.csv'
WITH (
FILE_TYPE = 'CSV',
CREDENTIAL = (IDENTITY='Managed Identity'),
ENCODING = 'UTF8',
FIELDTERMINATOR = ','
)
Similar to the COPY INTO using snappy parquet syntax, after running the command, the csv file was copied from ADLS gen2 into an Azure Synapse table in around 12 seconds for 300K rows.
Additionally, after performing the Data Preparation step, I did not encounter any errors with the following data types: DATETIME, INT, NVARCHAR (4000).
Also, after configuring the csv dataset properties, NULL ints, commas, and quotes in text fields were not an issue with this csv file type.
Using COPY INTO from Azure Data Factory
To use the COPY INTO command from Azure Data Factory, ensure that you have an Azure Synapse dataset created.

Next, add a Copy activity to a new ADF pipeline.
The source will be the dataset containing the ADLS gen2 storage account and the sink will be the Azure Synapse dataset.
Once the sink dataset is configured to an Azure Synapse dataset, the various copy methods will be displayed.
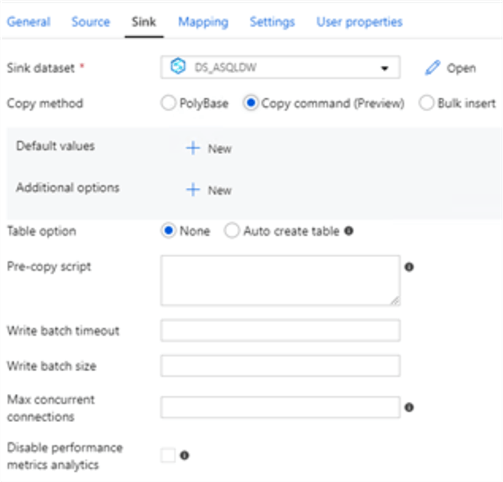
As we can see, the options include Polybase, Copy command (Preview), and Bulk Insert. I'll go ahead and select Copy command (Preview).
Note that there is an option to add a Pre-copy script in the event that I would like to truncate my staging table prior to a full re-load. Additionally, there is an option to 'Auto Create table'.
When I run the pipeline, the snappy parquet file from ADLS gen2 will be loaded to Azure Synapse from the Azure Data Factory Pipeline.
Next Steps
- Explore Polybase as an alternative option for loading data from ADLS gen2 to Azure Synapse Analytics (SQL DW) in the article - Load data from Azure Data Lake Storage to SQL Data Warehouse.
- Explore BULK INSERT as an alternative option for loading data from ADLS gen2 to Azure Synapse Analytics (SQL DW) in the article - Examples of bulk access to data in Azure Blob storage.
- For more detail on using Azure Data Factory to copy data to Azure Synapse, see: Copy and transform data in Azure Synapse Analytics (formerly Azure SQL Data Warehouse) by using Azure Data Factory.






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-02-20
