By: Rick Dobson | Updated: 2020-05-21 | Comments | Related: > Performance Tuning
Problem
Please describe and demonstrate a framework for collecting query run times with the getdate function. Also, show how to compute the statistical significance of differences in run times for different queries or the same query with different indexes.
Solution
It is common for DBAs to be tasked with improving query performance. One especially intuitive approach to tuning queries is with the getdate function. This function returns the system time on a computer running SQL Server. You can learn more about the function (here and here).
Use the getdate function with the datediff function to determine how long a query runs. Simply invoke and save the output from the getdate function immediately before and after running a query that you want to tune by comparing it to another implementation. Then, use the datediff function to assess how long it took for a query to run. Complete your tuning by comparing that outcome to another T-SQL code sample or the same code sample with a different set of keys or indexes.
If you seek an easy, common sense approach about how to compare the run times for two different T-SQL examples, this may very well be the tip that you urgently need to read. The tip provides a framework for using the getdate function to return run times associated with a T-SQL query. More specifically, you will learn how to
- Populate a table with run times for a query statement
- Evaluate which indexes give the shortest average run times
- Contrast via a statistical test run times from two different query implementations
A framework for getting query runtimes with the getdate function
The following is a short script consisting of pseudo code and comments for deriving a set of run times for a test query. The script displays a framework for deriving a set of run times for invoking a test query multiple times.
- The code begins with a use statement to designate a default database context.
- Next, dbcc dropcleanbuffers and checkpoint statements save data buffer pages and clear the data buffers of any uncommitted data developed during prior time assessments. These statements allow you to test a query with a cold data buffer without having to shut down and restart the server.
- A while loop runs a test query multiple times and performs other useful
operations.
- Declare statements for @t0 and @t1 define and populate local variables for start and end times associated with the test query.
- The test query could be a select statement or a T-SQL statement that can modify data.
- An insert/select statement populates a table variable with successive query run times from within the while loop.
- After the while loop completes, other code copies the contents of the table variable to a more persistent data container.
- The framework concludes with code to compute the mean and variance of run times for the test query run from inside the while loop.
-- a framework for using the getdate function to record -- and save multiple run times for a test query as well -- as the mean and variance of the run times use statement that specifies a default database context go -- clean and then clear dirty data buffers dbcc dropcleanbuffers; checkpoint; -- T-SQL code to make SQL Server ready -- to run the test query -- declarations for while loop that runs -- the test query multiple times -- while loop for running test query multiple times while condition begin declare @t0 datetime = getdate() -- test query declare @t1 datetime = getdate() -- insert/select statement to save in a table variable -- time immediately before (@t0) and after (@t1) -- running test query as well as the difference between -- before and after times -- increment loop counter for while condition end -- copy table variable contents to a temporary or -- permanent table -- compute and display mean and variance for query run times
The test database tables for this tip
This tip demonstrates how to collect a set of run times for a query that joins two tables in a SQL Server database. Different keys and indexes are evaluated for scenarios to assess their impact on query performance. One table (yahoo_prices_valid_vols_only) in the test query for the scenarios is a fact table from a data warehouse with over fourteen million rows. The second table (ExchangeSymbols) has fewer than ten thousand rows.
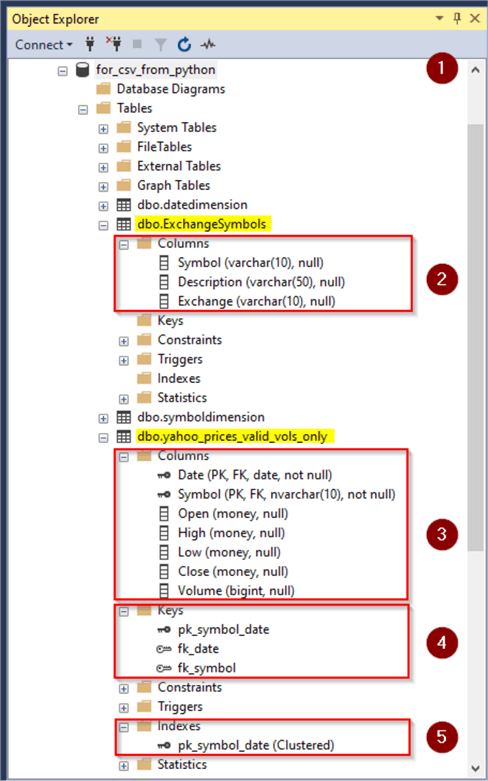
The following screen shot shows an Object Explorer view of the database, tables, and selected elements from each table in their base configuration.
- Item 1 denotes the default database name (for_csv_from_python).
- Item 2 shows the column names in the ExchangeSymbols table within the dbo schema. The ExchangeSymbols table has no keys nor indexes in its default configuration below.
- Item 3 shows the column names in the yahoo_prices_valid_vols_only table within the dbo schema. This table also has three keys as well as one index in its default configuration.
- Item 4 shows the names for the keys in the yahoo_prices_valid_vols_only
table.
- pk_symbol_date is the name for the primary key. Rows are unique by symbol and date column values.
- fk_date is a foreign key pointing at rows in the datedimension table within the data warehouse.
- fk_symbol is a foreign key pointing at rows in the symboldimension table within the data warehouse.
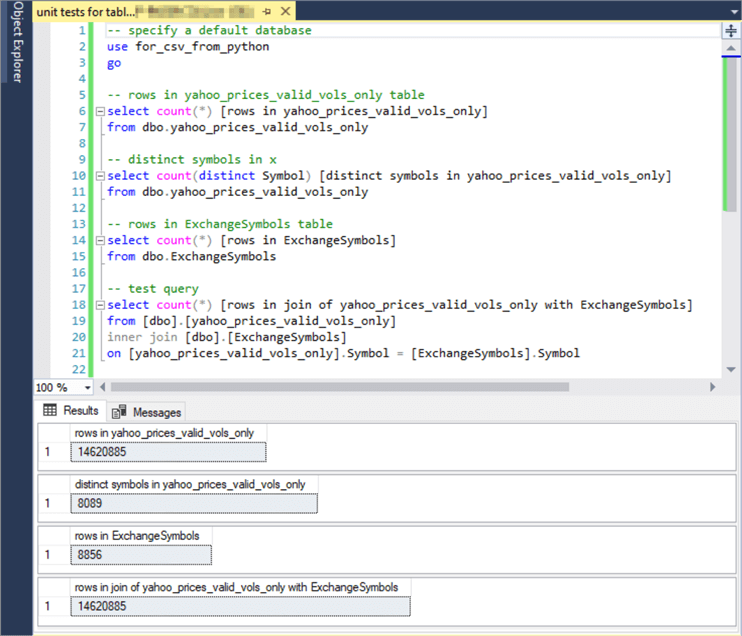
The next screen shot shows several queries with the yahoo_prices_valid_vols_only and ExchangeSymbols tables.
- The yahoo_prices_valid_vols_only fact table has 14620885 rows.
- The fact table contains 8089 distinct symbols. A symbol can appear on multiple rows for a set of trading dates during which its stock trades.
- The ExchangeSymbols table has 8856 rows. There is one row for each distinct symbol in ExchangeSymbols table. As a result, the ExchangeSymbols table contains some symbols that do not appear in the yahoo_prices_valid_vols_only fact table. This is, in part, a consequence of the two tables being from two different organizations that do not always follow the same naming conventions for symbols representing securities.
- The join of the yahoo_prices_valid_vols_only fact table with the ExchangeSymbols table contains 14620885 rows.
Timing one query with three different index settings
As a SQL Server DBA or developer, you probably encountered situations where any of several different index sets might be assigned to one or more tables in a query statement. Then, someone asks can you please determine which set of indexes runs the fastest? The framework comparing values returned by the getdate function before and after running a query is a good tool for answering this kind of question.
This section demonstrates how to use the getdate function framework to assess the mean and variance of a single query statement with three different key/index configurations. The first configuration is for the preceding screen shot from Object Explorer of the yahoo_prices_valid_vols_only and ExchangeSymbols tables in the for_csv_from_python database.
- The yahoo_prices_valid_vols_only table has three keys.
- A clustered primary key named pk_symbol_date that is based on date values within symbol values.
- A foreign key pointing at the symbol column in the symboldimension table.
- A foreign key pointing at the date column in the datedimension table.
- The ExhangeSymbols table has no keys or indexes in its base configuration, but it does contain a column of symbol values – many of which overlap with those in the symboldimension table.
Here' s a script to use the getdate framework to return the mean and the variance of thirty run times for a query to count the number of rows in the inner join of the yahoo_prices_valid_vols_only and ExchangeSymbols tables.
- The script starts with a pair of comment lines to indicate the index configuration for which run times are being evaluated.
- Next, a use statement specifies a default database context.
- Then, a pair of statements (dbcc dropcleanbuffers and checkpoint) copy all dirty data buffer pages to storage and empties the data buffer pages.
- The next block of statements re-initializes the pk_symbol_date and fk_symbol keys for the yahoo_prices_valid_vols_only table.
- Next, a pair of declare statements specify some scalar and table local variables.
- The scalar local variables (@cnt, @i, and @itrs) track the iterations
through a while loop statement.
- @cnt is assigned the count of rows from the test query statement being run multiple times.
- @itrs is assigned a value of thirty, which specifies the test query will be run thirty times.
- @i counts successive passes through the loop. The local variable is initialized to zero. Its value increases by one for each successive pass through the loop.
- The second declare statement is for a local table variable named @query_run_results.
This table variable has four columns.
- row_cnt which is for the assignment of the count function value from the test query. The count function returns the number of rows from the inner join of the yahoo_prices_valid_vols_only and ExchangeSymbols tables.
- start_time which is for the assignment of the output of the getdate function just before the execution of the test query (@t0).
- end_time which is for the assignment of the output of the getdate function just after the execution of the test query (@t1).
- diff_in_ms which is for the assignment of the output from a datediff function that computes the difference in milliseconds between @t0 and @t1.
- The scalar local variables (@cnt, @i, and @itrs) track the iterations
through a while loop statement.
- Then, the while loop code appears.
- The condition for continuing execution of the loop is that @i must be less than @itrs.
- A begin…end block marks the beginning and the end of the code
to be repeated in the loop.
- The first statement assigns a getdate function value to @t0.
- The next statement is the test query. Notice that the select list assigns the value of a count function to the @cnt local variable.
- The third statement assigns a getdate function value to @t1.
- An insert statement followed by a select statement copies the current values of @cnt, @t0, @t1, and a datediff function for the difference in milliseconds between @t0 and @t1 into a new row for the @query_run_results table variable.
- The last statement in the begin…end block increments the value of @i by one.
- The first block of code after the while loop drops any prior version of a table named #pk_symbol_date_and_fk_symbol_date_time_runs. Then, it copies with an into clause in a select statement the row values from the @query_run_results table variable into #pk_symbol_date_and_fk_symbol_date_time_runs. By specifying the target table to receive the contents of the @query_run_results table variable as a local temp table, a global temp table, or a regular SQL Server table, you can control the persistence and scope of the run time values in the table variables.
- The final block of code in the script below computes the mean and variance of the run times in #pk_symbol_date_and_fk_symbol_date_time_runs.
-- scenario to be evaluated -- pk_symbol_date and fk_symbol for yahoo_prices_valid_vols_only -- set a default database context use for_csv_from_python go -- clean and then clear dirty data buffers dbcc dropcleanbuffers; checkpoint; -- re-initialize keys for test scenario -- conditionally drop the default primary key if (select(object_id('pk_symbol_date'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date; -- add a fresh copy of the primary key alter table dbo.yahoo_prices_valid_vols_only add constraint pk_symbol_date primary key clustered (Symbol, Date); -- conditionally drop the default foreign key constraint named fk_symbol if (select(object_id('fk_symbol'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint fk_symbol; -- add a fresh copy of the default foreign key constraint named fk_symbol alter table dbo.yahoo_prices_valid_vols_only add constraint fk_symbol foreign key (Symbol) references dbo.symboldimension (Symbol) on delete cascade on update cascade; -- declarations for while loop -- and to store results from while loop declare @cnt int , @i integer = 0 , @itrs integer = 30 declare @query_run_results table(row_count int, start_time datetime, end_time datetime, diff_in_ms int) -- while loop for multiple runs of query to time while @i < @itrs begin -- @t0 is datetime before query run declare @t0 datetime = getdate() -- query to time goes here select @cnt= count(*) from [dbo].[yahoo_prices_valid_vols_only] inner join [dbo].[ExchangeSymbols] on [yahoo_prices_valid_vols_only].Symbol = [ExchangeSymbols].Symbol -- @t1 is datetime before query run declare @t1 datetime = getdate() -- store results from while loop iteration insert into @query_run_results select @cnt ,@t0 ,@t1 ,datediff(ms,@t0,@t1) -- increment @i for completion of current iteration set @i = @i + 1 end -- transfer run times from table variable to table for test scenario -- create table for run times from table variable begin try drop table #pk_symbol_date_and_fk_symbol_date_time_runs end try begin catch print '#pk_symbol_date_and_fk_symbol_date_time_runs ' + 'not available to drop.' end catch select row_count ,start_time ,end_time ,diff_in_ms into #pk_symbol_date_and_fk_symbol_date_time_runs from @query_run_results -- compute mean and variance from multiple time runs select avg(diff_in_ms) [average for durations in ms with pk_symbol_date and fk_symbol] ,var(diff_in_ms) [variance for durations in ms with pk_symbol_date and fk_symbol] from #pk_symbol_date_and_fk_symbol_date_time_runs
You can easily adapt the preceding script to collect run times for other configurations of keys and/or indexes. This tip examines two other scenarios:
- one that drops the pk_symbol_date key from the default configuration
- another that adds non-clustered columnstore indexes to both the ExchangeSymbols and yahoo_prices_valid_vols_only tables after removing other keys from the yahoo_prices_valid_vols_only table
The code for each scenario is largely similar. Therefore, this tip displays only the dissimilar parts for each scenario. The download for this tip includes a script file for each of the three scenarios run consecutively after one another.
Here' s the dissimilar parts for the scenario that drops the pk_symbol_date key from the base scenario. Ellipses (…) mark omitted identical code blocks that are the same across scenarios.
- The comments at the top indicate the script is for a scenario that drops the primary key named pk_symbol_date.
- After the comments, a use statement to specify a default database context is represented by an ellipsis.
- Next, the pk_symbol_date primary key is conditionally restored, and the fk_symbol foreign key is and dropped and restored.
- After the keys are re-configured for the scenario, the code to successively run the test query thirty times is represented by an ellipsis.
- Then, the displayed code below copies the run times calculated and saved in the omitted code to #remove_pk_symbol_date_primay_key_date_time_runs.
- The script concludes by computing and displaying the mean and variance of the query run times in #remove_pk_symbol_date_primay_key_date_time_runs.
-- scenario to be evaluated -- remove pk_symbol_date primary key for yahoo_prices_valid_vols_only -- re-initialize keys for test scenario -- conditionally drop the default primary key if (select(object_id('pk_symbol_date'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date; -- conditionally drop the default foreign key constraint named fk_symbol if (select(object_id('fk_symbol'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint fk_symbol; -- add a fresh copy of the default foreign key constraint named fk_symbol alter table dbo.yahoo_prices_valid_vols_only add constraint fk_symbol foreign key (Symbol) references dbo.symboldimension (Symbol) on delete cascade on update cascade; -- transfer run times from table variable to table for test scenario -- create table for run times from table variable begin try drop table #remove_pk_symbol_date_primay_key_date_time_runs end try begin catch print '#remove_pk_symbol_date_primay_key_date_time_runs ' + 'not available to drop.' end catch select row_count ,start_time ,end_time ,diff_in_ms into #remove_pk_symbol_date_primay_key_date_time_runs from @query_run_results -- compute mean and variance from multiple time runs select avg(diff_in_ms) [average for durations in ms with remove pk_symbol_date primay key] ,var(diff_in_ms) [variance for durations in ms with remove pk_symbol_date primay key] from #remove_pk_symbol_date_primay_key_date_time_runs
Here' s the dissimilar code blocks for the scenario that uses the columnstore indexes for the ExchangeSymbols and yahoo_prices_valid_vols_only tables instead of those in the base configuration keys. Ellipses (…) mark omitted identical code blocks that are the same across scenarios. The most noteworthy distinction is the code for adding the non-clustered columnstore indexes, which are included in the section with a header comment about re-initializing keys for the test scenario.
- Non-clustered columnstore indexes based on symbol column values are added for the ExchangeSymbols and yahoo_prices_valid_vols_only tables.
- Additionally, both the pk_symbol_date and fk_symbol keys are dropped from the yahoo_prices_valid_vols_only table.
You should also note that the successive run times for the test scenario are saved in a table named #nonclustered_columnstore_indexes_date_time_runs. Aside from these changes, the modifications for adding columnstore indexes are very similar to those for dropping a primary key.
-- scenario to be evaluated -- nonclustered columnstore index (ExchangeSymbols table) -- nonclustered columnstore index (yahoo_prices_valid_vols_only table) -- re-initialize keys for test scenario -- conditionally drop primary key constraint named fk_symbol if (select(object_id('pk_symbol_date'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint pk_symbol_date; -- conditionally drop foreign key constraint named fk_symbol if (select(object_id('fk_symbol'))) is not null alter table dbo.yahoo_prices_valid_vols_only drop constraint fk_symbol; -- create first nonclustered columnstore index begin try create nonclustered columnstore index [ix_ncl_cs_ExchangeSymbols_Symbol] on [dbo].[ExchangeSymbols] ([Symbol]) with (drop_existing = off, compression_delay = 0) end try begin catch create nonclustered columnstore index [ix_ncl_cs_ExchangeSymbols_Symbol] on [dbo].[ExchangeSymbols] ([Symbol]) with (drop_existing = on, compression_delay = 0) end catch -- create second nonclustered columnstore index begin try create nonclustered columnstore index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date] on [dbo].[yahoo_prices_valid_vols_only] ([Symbol],[Date]) with (drop_existing = off, compression_delay = 0) end try begin catch create nonclustered columnstore index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date] on [dbo].[yahoo_prices_valid_vols_only] ([Symbol],[Date]) with (drop_existing = on, compression_delay = 0) end catch -- transfer run times from table variable to table for test scenario -- create table for run times from table variable begin try drop table #nonclustered_columnstore_indexes_date_time_runs end try begin catch print '#nonclustered_columnstore_indexes_date_time_runs ' + 'not available to drop.' end catch select row_count ,start_time ,end_time ,diff_in_ms into #nonclustered_columnstore_indexes_date_time_runs from @query_run_results -- compute mean and variance from multiple time runs select avg(diff_in_ms) [average for durations in ms with nonclustered_columnstore_indexes] ,var(diff_in_ms) [variance for durations in ms with nonclustered_columnstore_indexes] from #nonclustered_columnstore_indexes_date_time_runs -- diagnostic select statement to see successive run times -- select * from #non_clustered_columnstore_index_time_runs -- remove nonclustered indexes drop index [ix_ncl_cs_ExchangeSymbols_Symbol] on [dbo].[ExchangeSymbols] drop index [ix_ncl_cs_yahoo_prices_valid_vols_only_Symbol_date] on [dbo].[yahoo_prices_valid_vols_only] go
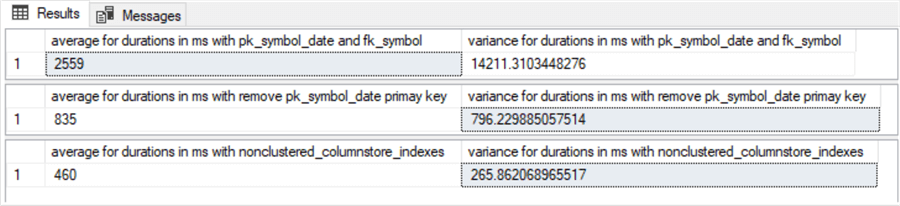
Here' s the results set from running consecutively the scripts for all three scenarios. The first, second, and third rows of results are, respectively, for the base index configuration, the configuration with a dropped primary key, and the configuration with non-clustered columnstore indexes.
What these results readily convey is that the columnstore store indexes have vastly superior performance (much shorter average run times) compared to either the base configuration or the base configuration with the pk_symbol_date key dropped.
Assessing the statistical significance of the difference between two means
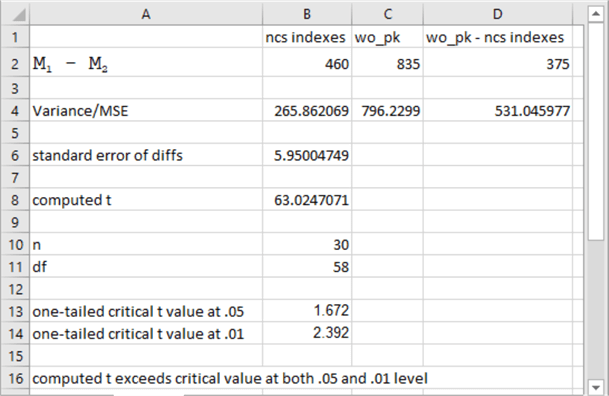
Because this tip' s code examples compute both the mean and the variance of run times for a scenario, you can assess the statistical significance of the mean run time differences between a pair of scenarios. The following screen shot of an Excel worksheet shows how to use the means and variances of the thirty run times based on non-clustered columnstore indexes (ncs indexes) versus the base configuration with the pk_symbol_date key dropped (wo_pk).
- The quantities in cells B2 and C2 are the means, respectively, for the run times based on non-clustered columnstore indexes and the base configuration keys with the pk_symbol_date key dropped.
- The quantities in cells B4 and C4 are the sample variances, respectively of the run times based on non-clustered columnstore indexes and the base configuration keys with the pk_symbol_date key dropped. Excel displays the variances to six or four places after the decimal point, but the actual quantities in the cells exactly match the results sets from the sample code.
- The mean squared error (MSE) is in cell D4. This quantity equals (B4+C4)/2. As you can see, it is just the average of the sample variances.
- The quantity in cell B6 is the standard error of the difference between the means; this is sometimes called the pooled standard deviation. You can compute it with this expression: sqrt((2*D4)/B10) where B10 is the sample size in each group (30).
- The computed t value in cell B8 for the difference between the group means equals D2/B6.
- You can compare computed t values versus selected critical t values. Critical values depend on a probability level and the sum of the sample sizes across both groups less 2. The sample size of each group for the run time values is 30, the quantity in B10. Critical t values are widely available on the internet as well as from specialized statistics software packages. For example, use this link to verify the critical t values reported in this tip.
- The spreadsheet below shows critical t values for a one-tailed test in cells B13 and B14. Because the computed t value in cell B8 exceeds the critical t value in cell B14, the difference between the means is statistically significant at beyond the .01 level of significance.
Next Steps
The T-SQL scripts and worksheet analysis are in this tip' s download file. The download file includes:
- a framework for using the getdate function to return run times associated with a T-SQL query
- T-SQL code for consecutively running the framework for the three scenarios discussed in this tip
- an Excel workbook file with a demonstration of how to use the means and variances from two scenarios to assess the statistical significance of the difference between the scenarios; however, the workbook expressions permit you to determine the statistical significance of the difference in means between any two scenarios
Try out the code examples for this tip. If you want to test the code with the data used for demonstrations in this tip, then you will also need to run scripts from this article Collecting Time Series Data for Stock Market with SQL Server and this article Time Series Data Fact and Dimension Tables for SQL Server.
Of course, the best way to test the results is with your own queries for data available within your organization. This approach will allow you to pick best performing queries for data in your organization.






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-05-21
