By: Fikrat Azizov | Updated: 2020-05-13 | Comments (1) | Related: 1 | 2 | 3 | 4 | > Azure
Problem
If you're considering migrating on-premises Analysis Services model to the cloud, Azure Analysis Services is probably the best option. It provides you a powerful and scalable service, accessible from anywhere around the world. However, managing Azure Analysis Services may be more challenging, than its on-premises counterpart - SQL Server Analysis Services. In these series of tips, I'm going to share my experience of using Azure Logic App to automate Azure Analysis Services model refresh tasks.
Solution
Overview of Azure Analysis Services and Logic App Services
Azure Analysis Services (AAS) is a platform as a service from Microsoft, allowing you to create tabular models, which could be accessed using various visualization tools, like Power BI, SSRS, Tableau, etc. There're various tools to interact with AAS:
- The models could be developed and deployed to AAS, using Visual Studio or SQL Server Management Studio (SSMS).
- General AAS tasks, like service scaling and service monitoring could be performed, using Azure Portal.
- AAS models could be refreshed, using number of service API's. Although you can use to SSMS to refresh AAS models, you'd need to install it on the on-premises machine. However, the true cloud solution would require leveraging Azure Data Factory, Azure Logic App or other cloud services.
Azure Logic App is an integration tool, allowing to connect to many different cloud services, including AAS. Logic App has an intuitive graphical interface with variety of out of box transformation components, which allow creating cloud based ETL pipelines with little coding. Logic App also allows executing API calls against different Azure services and that's the capability we're going to use, to interact with AAS. If you're new to Logic App, I'd encourage you to visit this Microsoft documentation with a number of great tutorials. Another great resource is, Refreshing Azure Analysis Services models using Logic Apps By Adam MarcZak article, which explains specifics of AAS refresh from Logic App. I'm assuming you already have basic experience of creating Logic App applications, for the purpose of this tip.
Azure Analysis Services management API's
AAS has a few asynchronous API's to manage model refreshes, as well as to inquire their refresh statuses, as described below:
- The API to initiate a model refresh. This API allows sending a POST request to the following URL: https://regionName.asazure.windows.net/servers/serverName/models/modelName/refreshes where regionName is the region hosting your AAS, serverName is your AAS server's name and modelName is the name of the model to be refreshed. The model refresh API also includes extra parameters, like table names, partitions, parallelism degree, wrapped in a JSON format.
- API to check the status of ongoing refresh. This API requires sending a GET request to the following URL: https://regionName.asazure.windows.net/servers/serverName/models/modelName/refreshes/refreshID where refreshID is an internal ID of one of the ongoing refresh processes.
You can get more detailed information about AAS management API's here and here.
AAS refresh challenges and Logic App design
AAS cube processing can be a very time and resource consuming task, depending on the queries, used to build the model tables, as well as the sizes of the underlying SQL tables. On top of that, AAS processing could time out, if it runs beyond pre-configured timeout period. One of the typical approaches to overcome these challenges is to divide model tables into partitions and process each partition separately. Partitioning also allows you to process only selected partitions, based on their update patterns.
The Logic App applications I'll describe here, have been designed in a modular and parameterized way, to address the above mentioned challenges. It allows the model processing to be performed on various granularity levels (model, table, multi-table and partition levels). It makes sense to choose model level granularity for small cubes, table granularity for medium size tables and partition granularity for large tables.
Here is the brief description of these modules:
- The core module - This module initiates AAS refresh, inquires refresh status in a loop until successful or failure end, and logs important refresh details into SQL table. This module has a mandatory ModelName parameter, as well as optional table, partition and parallelism degree parameters.
- The parent module - This module serves as a shell module; it calls multiple core modules for processing different models and tables. This allows building the flexible processing flows to manage multiple model refresh tasks in parallel.
The core module's structure can be divided into following logical sections:
- Extract the input parameters and initialize the variables.
- Construct a JSON body for the model refresh.
- Initiate the model refresh.
- Inquire the refresh status in a loop.
- Log the refresh statistics and processing errors into the tables.
I'll describe each logical section listed here in detail, in the following sections.
Prepare AAS refresh logging structures
The core module logs execution statistics and error messages into Azure SQL DB, which then could be used to create the analytic reports. We'll use following two tables:
- CUBE_REFRESH_LOGS - This table contains model refresh statistics, like start/end time, duration, model/table/partition names, etc.
- CUBE_REFRESH_ERRORS - This table contains error messages, encountered during AAS refresh.
These tables can be created in any SQL database, which can be accessed by Logic App, including Azure SQL Db, Azure SQLDW, etc. I've created an Azure SQL DB for the purpose of logging and used the below scripts to create these tables:
CREATE TABLE [CUBE_REFRESH_LOGS] ( [Id] [int] PRIMARY KEY IDENTITY(1,1) NOT NULL, [CubeName] [varchar](100) NULL, [StartTime] [datetime] NULL, [EndTime] [datetime] NULL, [RefreshStatus] [varchar](30) NULL, [PartitionName] [varchar](100) NULL, [TableName] [varchar](100) NULL, [JSONBody] [varchar](8000) NULL ) GO CREATE TABLE [CUBE_REFRESH_ERRORS] ( [Id] [int] PRIMARY KEY IDENTITY(1,1) NOT NULL, [CubeName] [varchar](100) NULL, [TableName] [varchar](100) NULL, [PartitionName] [varchar](100) NULL, [StartTime] [datetime] NULL, [EndTime] [datetime] NULL, [Errmessage] [varchar](5000) NULL )
In addition, let's create two stored procedures to populate these tables, using below script:
CREATE PROC [SP_LOG_AAS_REFRESH_ERRORS] @CubeName [varchar](100), @TableName [varchar](100), @PartitionName [varchar](100), @StartTime [varchar](20), @EndTime [varchar](20), @ErrMessage [varchar](4000) AS DECLARE @StTm Datetime,@EndTm datetime SET @StTm=Dateadd(hour,-5,CAST(substring(@StartTime,1,19) AS Datetime)) SET @EndTm=Dateadd(hour,-5,CAST(substring(@EndTime,1,19) As Datetime)) INSERT INTO CUBE_REFRESH_ERRORS([CubeName] ,[TableName] ,[PartitionName] ,[StartTime] ,[EndTime] ,[ERRMESSAGE]) VALUES(@CubeName,@TableName,@PartitionName,@StTm,@EndTm,@ErrMessage) GO CREATE PROC [SP_LOG_AAS_REFRESH_STATS] @CubeName [varchar](100), @StartTime [nvarchar](100), @EndTime [nvarchar](100), @RefreshStatus [nvarchar](100), @PartitionName [varchar](100), @TableName [varchar](100), @JSONBody [varchar](8000) AS DECLARE @StTm DAtetime,@EndTm datetime SET @StTm=Dateadd(hour,-5,CAST(substring(@StartTime,1,19) AS Datetime)) SET @EndTm=Dateadd(hour,-5,CAST(substring(@EndTime,1,19) As Datetime)) INSERT INTO CUBE_REFRESH_LOGS([CubeName] ,[StartTime] ,[EndTime] ,[RefreshStatus] ,[PartitionName],TableName,JSONBody) VALUES(@CubeName,@StTm,@EndTm,@RefreshStatus,@PartitionName,@TableName,@JSONBody) GO
Extract the input parameters and initialize the variables
The purpose of this section is to extract parameters and initialize variables. Let's create a new Logic app named as Admin-Refresh-AAS-Child and add a HTTP trigger to it - this component will enable us to call the core module from other Logic Apps. Include the following JSON body inside the HTTP trigger, to be able to receive essential model parameters from outside this app:
"properties": { "JSONBody": { "type": "string" }, "MaxParallelism": { "type": "string" }, "ModelName": { "type": "string" }, "PartitionName": { "type": "string" }, "TableName": { "type": "string" } }, "type": "object" }
This JSON schema allows passing following parameters:
- ModelName - Represents the model name.
- JSONBody - Represents JSON string with multiple table names.
- TableName - Represents the specific table name to be processed. Note that this module will handle JSonBody parameter, if both JSonBody and TableName parameters supplied.
- PartitionName - Represents specific partition name. Note that TableName parameter is required, if PartitionName is supplied.
- MaxParallelism - Represents the parallelism degree of the processing job (by default equals to 2).
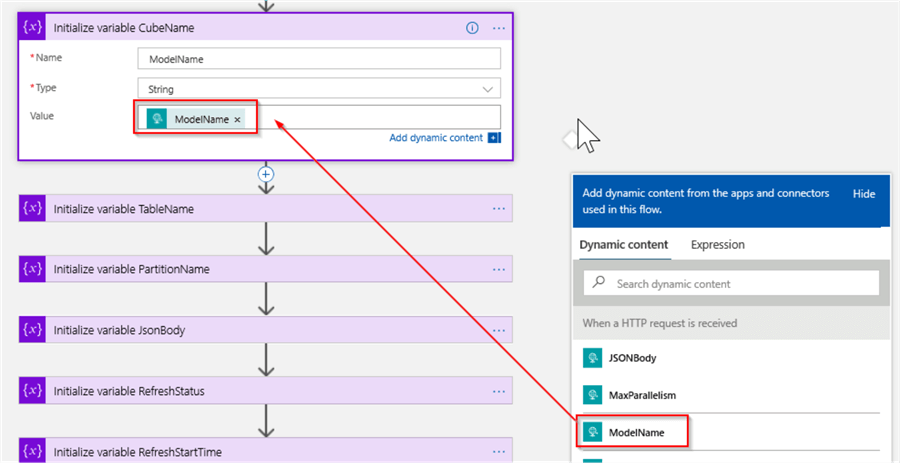
Next, add 'Initialize variable' action named as 'Initialize variable CubeName', enter ModelName as the variable name and string as the data type. Select the ModelName from the list of dynamic expressions on the right-hand side, as follows:
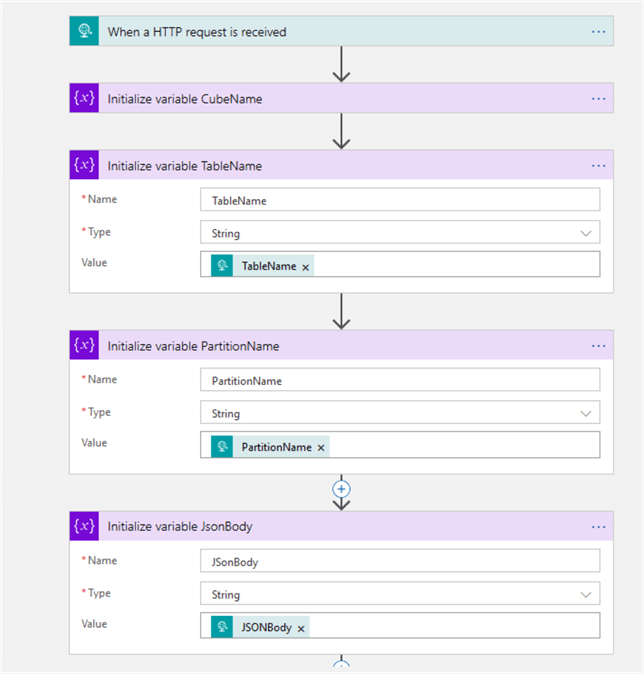
Now, let's add a few more 'Initialize variable' actions to receive the remaining parameters TableName, PartitionName and JSonBody, as follows:
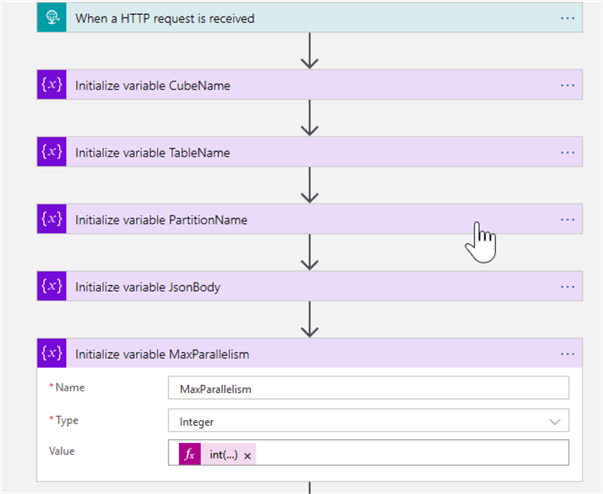
Add another 'Initialize variable' action to extract the MaxParallelism parameter and convert it into integer type, using the expression int(triggerBody()?['MaxParallelism']), as follows:
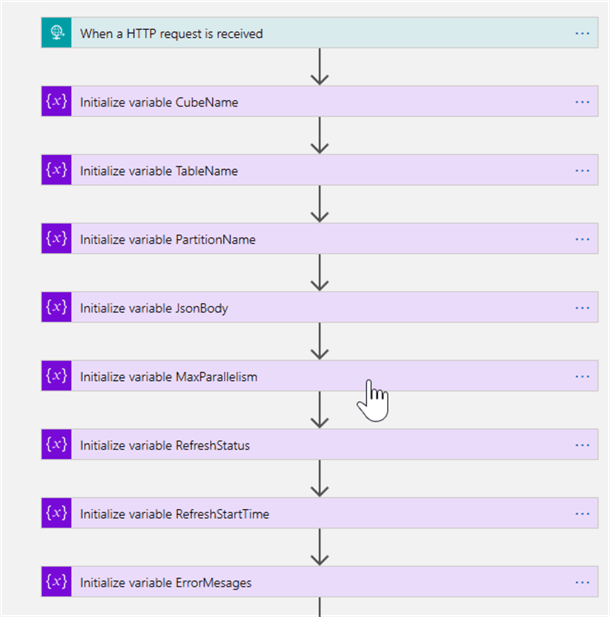
Next, let's initialize a few more variables, with the following configurations:
| Variable name | Type | Value/expression |
|---|---|---|
| RefreshStatus | String | |
| RefreshStartTime | String | utcNow() |
| ErrorMessages | String |
Here's the screenshot of actions we've added in this section:
Construct a JSON body for the model refresh
The purpose of this section is to build a JSON string, which will be needed when we initiate the model refresh.
Based on the parameters passed to the core module, I've designed the data flows for the following processing scenarios:
- Full model processing - This flow will start, when both TableName and JSonBody parameters are empty.
- Multi-table processing - This flow will start, when JSonBody parameter is not empty.
- Single table processing - This flow will start, when JSonBody parameter is empty and TableName parameter is not empty.
- Partition processing - This flow will start, when both TableName and PartitionName parameters are non- empty.
We'll first design the flow for multi-table processing scenario (scenario #2).
In order to check if the JSonBody parameter was supplied, let's add the Condition action named 'Check if JSON body was supplied' with the following condition:
empty(variables('JSonBody')) is equal true
The false outcome of the 'Check if JSON body was supplied' action would mean that non-empty JSON parameter was supplied. So, let's add Set variable action to the false outcome of this condition and use it to assign some dummy value ('Multiple values' string, in my example) to the variable TableName-we'll need this for logging purposes:
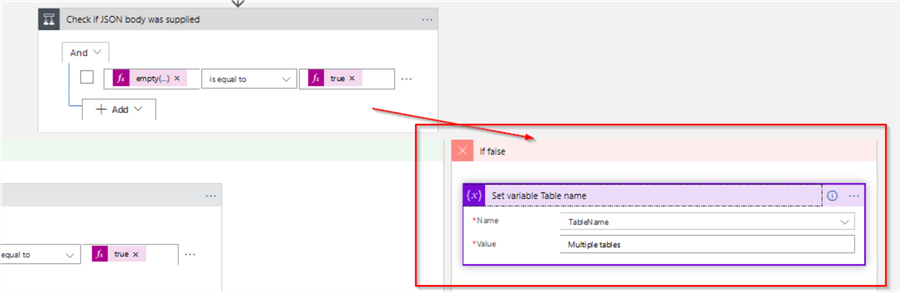
Now, let's construct the flow for a full model processing (scenario #1). Add a condition action to the 'Check if JSON body was supplied' action's true outcome with the below expression, and name it as 'Check if Table name was supplied':
empty(variables('TableName')) is equal to true
Here's how your screen should look with the new addition:
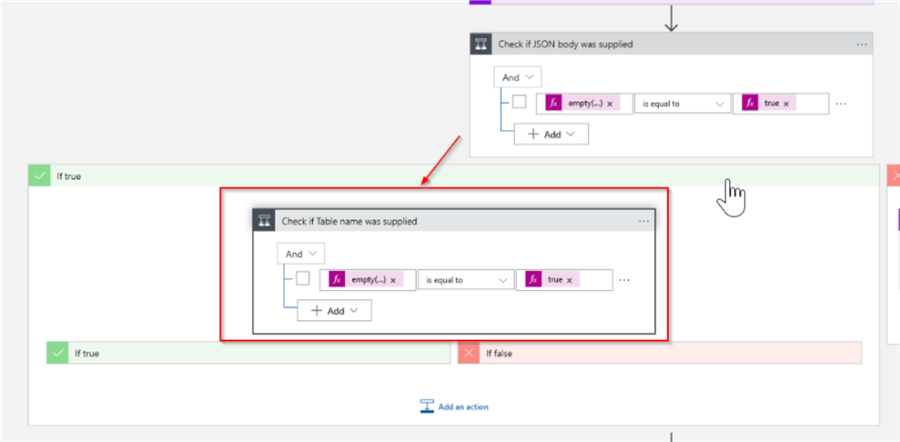
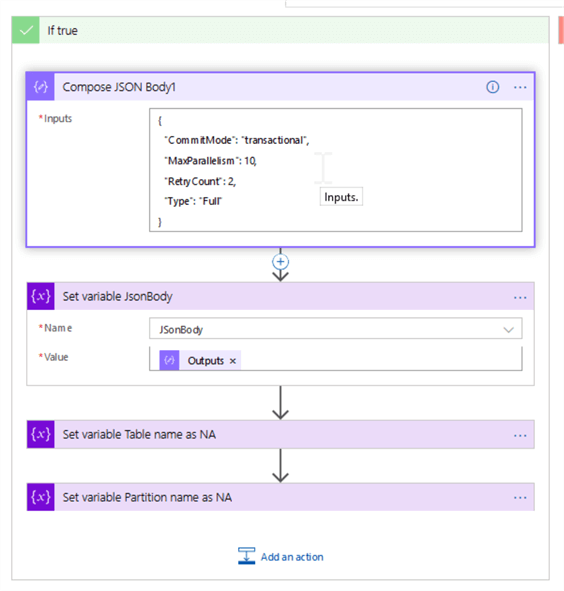
The true outcome of this conditional check would match the scenario, where both TableName and JSonBody parameters were empty, e.g. cube needs to be processed on the full model level. So, let's add a Data operations action with the below expression and assign its output to the JSonBody variable:
{
"inputs": {
"CommitMode": "transactional",
"MaxParallelism": 10,
"RetryCount": 2,
"Type": "Full"
}
}}
Next, add a couple of Set variable actions to the end of this flow, to set the variables TableName and PartitionName to 'NA' string, for logging purposes, as follows:
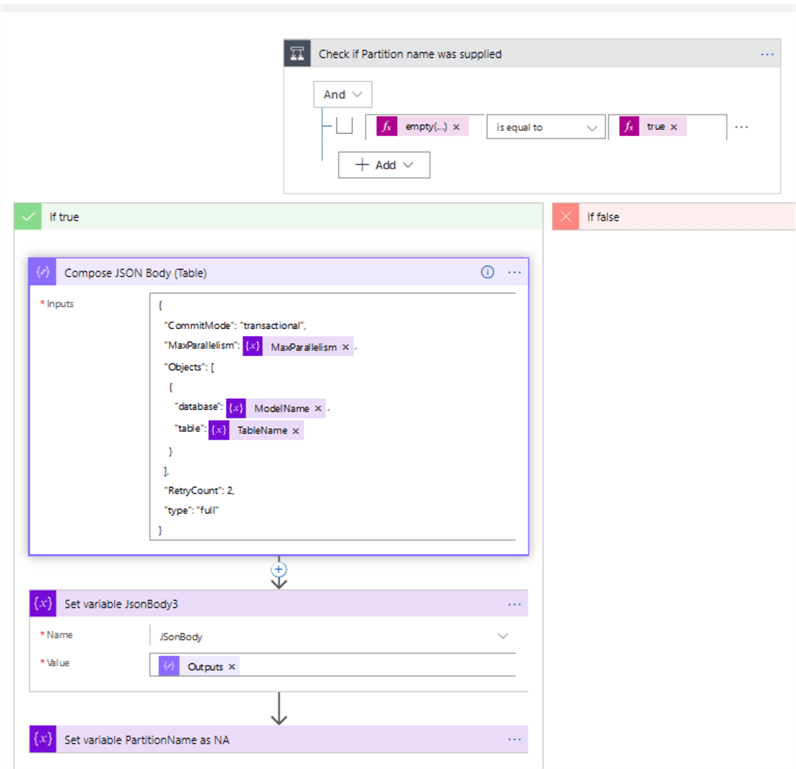
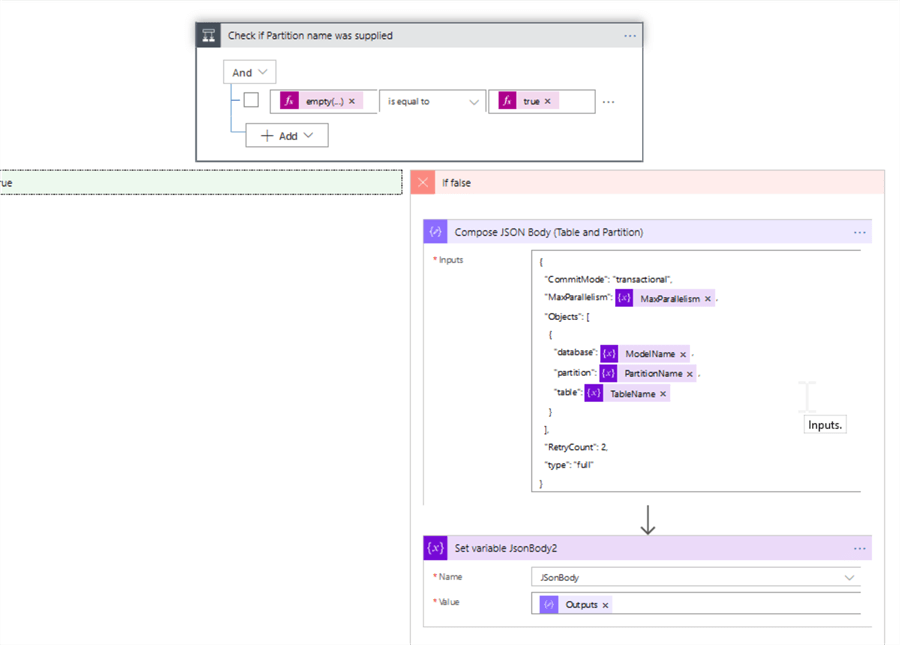
Now, let's construct data flows to address the scenarios #3 and 4. Let's add the condition action, named 'Check if Partition name was supplied' to the false outcome of the 'Check if Table name was supplied' condition, with the following expression:
empty(variables('PartitionName')) is equal to true
This action would check if PartitionName parameter has been supplied. The true outcome of this condition would address the table level processing (scenario #3). Let's add a Data operations action (named as 'Compose JSON Body' in my example) to the true outcome, with the following expression:
{
"inputs": {
"CommitMode": "transactional",
"MaxParallelism": "@variables('MaxParallelism')",
"Objects": [
{
"database": "@variables('ModelName')",
"table": "@variables('TableName')"
}
],
"RetryCount": 2,
"type": "full"
}
}}
Next, add two Set variable actions to the same flow, first one to assign the results of the Compose JSON Body action to the JSonBody variable, followed by a second action to assign 'NA' string to PartitionName value. Here's the screenshot for this section of the flow:
Finally, let's address the last scenario, where both TableName and PartitionName parameters were supplied (scenario #4), by adding a Data operations action to the 'Check if Partition name was supplied' condition's false outcome, with the below expression:
{
"inputs": {
"CommitMode": "transactional",
"MaxParallelism": "@variables('MaxParallelism')",
"Objects": [
{
"database": "@variables('ModelName')",
"partition": "@variables('PartitionName')",
"table": "@variables('TableName')"
}
],
"RetryCount": 2,
"type": "full"
}
}}
Next, add a Set variable action to assign the results of the previous action to the JSonBody variable.
Here's the screenshot for the false outcome of the 'Check if Partition name was supplied' condition:
This concludes the construction of preparatory steps for the core module to refresh AAS models. In the next tip I'll describe the steps required to initiate refresh and inquire model refresh status.
Next Steps
- Read: Refreshing Azure Analysis Services models using Logic Apps By Adam MarcZak
- Read: Logic App tutorials from Microsoft
- Read: Automate Azure Analysis Services management using Logic App- Part 2






About the author
 Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.
Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-05-13
