By: Nai Biao Zhou | Updated: 2020-09-17 | Comments | Related: > Python
Problem
When performing practical data analysis, we frequently manipulate data stored in nonlinear data structures, such as tree structures or graph structures. Recursion–a distinct technique to achieve repetition–provides an elegant and concise solution for working with these nonlinear data structures. There are many classic examples of recursive implementation on the web [1,2,3]. With having some Python programming skills, we can read source code that implements recursive algorithms. However, recursion requires us to think in an unfamiliar way [4]. Even though we catch the basic idea of recursion, we may not be able to apply this technique to solve problems at work. How do we learn recursive techniques and apply these techniques to real-world projects?
Solution
We may already know how to use a for-loop or a while-loop to run a code block repeatedly. Recursion is another form of repetition. A recursive definition means a description of something that refers to itself. Recursion and looping share some similarities: a recursive function can achieve any repetition task implemented by loops, and vice versa. Sometimes, recursion may provide clean and concise solutions for problems that may be quite difficult to solve with loops.
However, recursive solutions are challenging to understand and debug; we should avoid recursion if it is inefficient. Although we may not use recursive techniques in our program, we should add recursion to our problem-solving toolbox and learn to think recursively. Some problems are naturally recursive, such as visiting leaves on a tree data structure or visiting nodes on a graph data structure [5]; it is easy to solve them when we think recursively.
To demonstrate the power of recursion and draw attention to recursive algorithms, we look at a classic example of recursion: The Tower of Hanoi. As shown in Figure 1, there are three posts: A, B, and C. The game's goal is to move all disks from A to C, using B as temporary storage [6]. We must follow these three rules when moving disks:
- We move one disk at a time;
- We must stack disks on one of the three posts;
- We must not place a larger disk on top of a smaller one;

Figure 1 Towers of Hanoi
Although we work on a simple case that there are three disks on A, writing a program to print out all steps to move disks from A to C seems big and scary; moreover, we may not know where to start. Using recursion, we can use several lines of Python code to solve this puzzle:
# Recursive function to move n disks from "from_post" to "to_post" via the temporary storage temp_post def moveDisk(n, from_post, to_post, temp_post): 'n is the number of disks. from_post, to_post and temp_post are three posts' if n == 1: print("Move disk from {} to {}".format(from_post,to_post)) else: moveDisk(n-1, from_post, temp_post, to_post) moveDisk(1, from_post, to_post, temp_post) moveDisk(n-1, temp_post, to_post, from_post) # Move three disks from A to C, using B as temporary storage moveDisk(3, "A", "C", "B") # The outputs of this program should look like the follows: ''' Move disk from A to C Move disk from A to B Move disk from C to B Move disk from A to C Move disk from B to A Move disk from B to C Move disk from A to C '''
The program prints step-by-step instructions to move all disks from A to C. We can verify the program's outputs by playing the interactive game available on [6]. When we increase the number of disks, the number of steps to solve this puzzle increases exponentially. Thus, a simple solution does not indicate an efficient solution.
Let us take a close look at the function "moveDisk." When there is one disk, we move it from A to C directly. Given more than one disk, the function "moveDisk" calls itself during its execution. We observe that the function divides the task into three subtasks when moving more than one disk:
- Move the top n-1 disks from A to B, using C as temporary storage;
- Move the bottom disk from A to C directly;
- Move the n-1 disks from the temporary storage B to C, using A as the new temporary storage;
This function does not use any explicit loops. The repeated recursive calls produce repetitions. When the function makes a recursive call, the first argument n–the number of disks–reduces by one. The repetition ends when n = 1, and the function does not make any further recursive calls.
We have a taste of recursion. When we first encounter this recursive function, the elegant program with few lines of code impresses us. Then, we may suspect whether this solution works correctly and ponder how to come up with this algorithm. Such curiosity can motivate us to learn recursive techniques.
Recursive techniques differ from the use of loops; this tip introduces the basic idea behind recursion and studies recursive algorithm’s characteristics. There are many ways to categorize recursions. Based on whether a function calls itself from within itself, we have two categories of recursion: direct recursion and indirect recursion [7]. This tip serves as an introductory tutorial; we use another categorization method. According to whether a recursive function returns a result, we broadly categorize recursion into two types: recursive function and recursive procedure. We provide examples of each type. The recursive technique to solve the Tower of Hanoi puzzle does not return a result; therefore, that technique is a recursive procedure.
To strengthen the understanding of recursion and have faith in recursion’s correctness, we explore the similarities between mathematical induction and recursion. The mechanism provided by mathematical induction gives us a hint to master recursive techniques [8].
As shown in the Tower of Hanoi puzzle solution, a recursive algorithm has two components: (1) base cases and (2) recursive cases. When handling recursive cases, the algorithm makes recursive calls. We cover a five-step process to design a recursive algorithm. Your website administrators want to go through all hyperlinks on their site and identify all inaccessible links. We use this five-step process as a template to solve this real-world problem.
I organize the remaining sections of this tip as follows: Section 1 provides four classic examples of recursive algorithms. We explore similarities between recursive thinking and mathematical induction in Section 2. Next, Section 3 covers techniques to design recursive algorithms. To use recursive techniques in practice, Section 4 provides sample code to scrape your website. Finally, the summary section wraps up this tip.
I tested code used in this tip with Microsoft Visual Studio Community 2019 and Python 3.7(64-bit) on Windows 10 Home 10.0 <X64>. The DBMS is Microsoft SQL Server 2017 Enterprise Edition (64-bit).
1 – Study Classic Recursion Examples
The basic idea behind recursion is the divide and conquer strategy, which decomposes a problem into smaller versions of the original problem. Therefore, we can use the same algorithm for all subproblems. The function or procedure that solves the original problem makes one or more recursive calls to itself during execution. The repetition process stops when the program makes no more recursive calls, and the original problem is solved.
Recursive functions may directly come from mathematical equations. The recursive implementation seems not challenging when mathematical equations are ready. To start with simple examples, we look at two recursive function examples, then, move to two recursive procedure examples.
1.1 Recursive Function Examples
In mathematics, a geometric series is a series with a constant ratio between successive terms [9]. We write a geometric sequence in this form:

where a is the first item, and r is the common ratio between terms;
 represents the nth item.
represents the nth item.
To give a concrete example, we let a = 7 and r = 2. The following shows the first five items in the sequence:
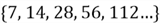
The following equations show how to compute the partial sums of the sequence:





We use a for loop in Python to compute the sum of these five items:
sum = 0 n = 5 a = 7 r = 2 sum = 0 for i in range(n): sum = sum + a*r**i print('The sum of the first {} items in the sequence is {}.'.format(n, sum)) #The output of the program should look like the following: '''The sum of the first 5 items in the sequence is 217.'''
There is a natural recursive definition in the equations to compute the partial sum of the sequence. We write the recursive definition in the following equations:


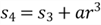

We can formalize these equations:

The general form indicates that the partial sum is "a" when n = 1. The partial sum of the first n items adds the partial sum of the first (n-1) items to the nth item. Given this mathematical definition, the recursive implementation seems natural, and here is the program that uses a recursive function:
# A recursive function def computeSum(n,a,r): print('Call the function computeSum({}, {}, {})'.format(n,a,r)) if n == 1: return a else: # Make a recursive function call res = computeSum(n-1, a, r) + a*r**(n-1) print('computeSum({}, {}, {})={}'.format(n,a,r,res)) return res n = 5 a = 7 r = 2 sum = computeSum(n,a,r) print('The sum of the first {} items in the sequence is {}.'.format(n, sum)) #The output of the program should look like the following: ''' Call the function computeSum(5, 7, 2) Call the function computeSum(4, 7, 2) Call the function computeSum(3, 7, 2) Call the function computeSum(2, 7, 2) Call the function computeSum(1, 7, 2) computeSum(2, 7, 2)=21 computeSum(3, 7, 2)=49 computeSum(4, 7, 2)=105 computeSum(5, 7, 2)=217 The sum of the first 5 items in the sequence is 217. '''
The program uses two print statements to track how the function calls itself. As shown in program outputs, the program's start point is to calculate the sum for n = 5. When the function computes the sum for n = 5, it calls itself to find a value for n = 4. When the function calculates the sum for n = 4, it calls itself to find a value for n = 3. The process continues until the function needs to find a value for n = 1 to compute the case when n =2. Since we know the value is "a" when n = 1, the process stops, and we then obtain the value for n = 2, 3, 4, and 5, sequentially. This computation is recursive, but not circular. The process stops at n = 1, and the function does not make any recursive call. We call the case that terminates the process to be a base case for the recursion.
To help understand the process, we give each version a different name. Invoking the recursive function "computeSum" is equivalent to calling the following five functions in a chain. The last function in the chain is the base case for the recursion.
def computeSum5(n, a, r): return computeSum4(4, 7, 2) + a*r**(5-1) def computeSum4(n, a, r): return computeSum3(3, 7, 2) + a*r**(4-1) def computeSum3(n, a, r): return computeSum2(2, 7, 2) + a*r**(3-1) def computeSum2(n, a, r): return computeSum1(1, 7, 2) + a*r**(2-1) def computeSum1(n, a, r): return a n = 5 a = 7 r = 2 sum = computeSum5(n,a,r) print('The sum of the first {} items in the sequence is {}.'.format(n, sum)) #The output of the program should look like the following: '''The sum of the first 5 items in the sequence is 217.'''
This example exhibits four critical characteristics of recursive definitions:
- There are one or more base cases that we have solutions for immediately;
- There are one or more recursive cases that make recursive calls
- All chains of recursion eventually end up at one of the base cases;
- The combination of results from each recursive call is the solution to the original problem.
When we compute the partial sum of a geometric sequence, the mathematical equation naturally suits a recursive function. However, such an equation may not always be available. Let us look at an example of forming an equation by ourselves. The example task is to reverse a date in the format "yyyyMMdd." For example, the reverse of the date "20200801" is "10800202".
In the partial sum computation, a smaller version of the original problem is to tackle fewer items in the sequence. When we know the sum of the first (n-1) items in the sequence, we can immediately obtain the sum of the first n items according to the mathematical equation. However, in this example, knowing the reverse of date "20200731" does not help know the reverse of "20200801." Dealing with a date before the original date is not a smaller instance of the same problem.
The simpler version of the original problem is to reverse fewer characters in the date string. If we know the reverse of the string "020801", the reverse of the date string "20200801" is the reverse of "020801" plus the first character "2". Then, we can form a recursive formula:

where s denotes a string, and
 denotes the reverse of an n-character string.
denotes the reverse of an n-character string.
When a recursive formula is available, the recursive implementation seems obvious. The following program computes the reverse of the date string "20200801" and demonstrates four critical characteristics of the recursive function definition.
def reverseString(s): if len(s) == 1: return s else: return reverseString(s[1:]) + s[0] dateString = '20200801' reversedDateString = reverseString(dateString) print('The reverse of date {} is {}.'.format(dateString, reversedDateString)) #The output of the program should look like the following: '''The reverse of date 20200801 is 10800202.'''
1.2 Recursive Procedure Examples
The recursive function to solve the Towers of Hanoi puzzle differs from these two recursive function examples in that the function, traditionally called method, does not return a result. Since we may not form mathematical formulas for procedures, determining the smaller version of the original problem seems challenging. To adopt recursive techniques, we should have an abstract view of procedures without considering the problem's complexity [4].
We usually start with easy cases, solve small problems, and then conclude some patterns. When there are two disks on A, as shown in Figure 2, we perform three steps:
- Move the top disk from A to B;
- Move the bottom disk from A to C;
- Move the top disk from B to C;
We use three steps to move disks from A to C, using the B as temporary storage.
Because of symmetry, the procedure is the same when we want to move disks from A to B using C as temporary storage. At the initial stage, two disks may be on B or C. The solution is the same as well. We can use the same method to move disks from B to C using A as temporary storage.

Figure 2 Two Disks
We consider the three-step procedure that moves two disks from one post to another to be a single operation. When there are three disks, we can also perform three steps to move disks from A to C:
- Move the top two disks from A to B, as shown in Figure 3;
- Move the bottom disk from A to C;
- Move the top two disks from B to C;

Figure 3 Three Disks
Now we know how to move three disks from one post to another. We consider moving three disks to be a single operation. When there are four disks, we still can perform three steps to move disks:
- move the top three disks from A to B, as shown in Figure 4;
- move the bottom disk to C;
- move the top three disks from B to C;

Figure 4 Four Disks
After we played with several simple cases, the abstract view of the procedure appears. To move n disks from A to C, we can perform these three steps:
- Move the top (n-1) disk from A to B, using C as the temporary storage;
- Move the bottom disk from A to C;
- Move the top n-1 disk from B to C, using A as the temporary storage;
Since the algorithm to move n disks is the same as the algorithm to move (n-1) disks, we decompose a problem into a simpler version of the same problem. When we continue to break down the problem into successively smaller ones, eventually we reach a subproblem that we have an easy solution for. In this example, the recursive process stops when n = 1 because we can move one disk from A to C directly.
It is noteworthy that the number of steps grows exponentially as the number of disks increases linearly. This fact reminds us that a simple program may require excessive computing resources. We should be able to think recursively, but we should take program efficiency and performance into consideration when determining whether to adopt a recursive implementation.
The Towers of Hanoi is a fun game to play. The solution to the puzzle demonstrates a way of using recursive procedures to solve a complex problem. In practice, data in a tree structure has a recursive nature. The window file system organizes directories and files into a tree-like structure shown in Figure 5. Each directory may contain files and other directories, which in turn may contain files and other directories.

Figure 6 A Tree Like Folder in Windows System
Using recursive techniques, we can walk through all directories and files within a directory. The function "os.walk" in Python’s os module can walk through a directory tree either top-down or bottom-up [10]. However, to demonstrate recursive procedures, we explore a recursive algorithm that finds file sizes, last modified dates, and created dates. To have an abstract view of a directory, we consider every item in the directory to be an entry. Therefore, we can use the same procedure to handle directories and files. When the program visits a directory, it performs the following actions:
- List all entries in the directory;
- Go through each entry;
When we list all entries within a directory, each entry is a simpler version of the directory. Therefore, the same algorithm can act on each entry. We use four functions in the os module: os.path.isdir(path), os.path.split(path), os.listdir(path), and os.path.join(path, fileName). We create a recursive procedure in Python to walk through a directory tree from root to leaves with the use of these functions.
import os import time def walkFileDirectory(path, indent = 0): tab = ' ' if not os.path.isdir(path): statinfo = os.stat(path) (dirname, filename) = os.path.split(path) dateCreated = time.strftime('%d/%m/%Y %H:%M%p', time.localtime(statinfo.st_mtime)) dateModified = time.strftime('%d/%m/%Y %H:%M%p', time.localtime(statinfo.st_mtime)) size = statinfo.st_size/1000 print("{:50}{:>10,.0f}KB{:>25}{:>25}".format(tab*indent+filename, size,dateCreated,dateModified)) else: print('{}+ {}\\'.format(tab*indent, path)) indent += 1 for pathName in os.listdir(path): childPath = os.path.join(path, pathName) walkFileDirectory(childPath, indent) walkFileDirectory('C:\\temp')
The Python code implementation contains two base cases and one recursive case. The program does not make any further recursive calls when the path represents a file, or the path points to an empty folder. The recursive calls avoid infinite repetitions because all calls end up invoking one of these two cases. We combine all information from the printout in each repetition to be a solution to the initial problem.
2 – Recursive Thinking and Mathematical Induction
Some people may find it hard to understand recursion because recursion has few analogs in everyday life [4]. Recursive thinking is comparable to mathematical induction. They are very similar in two ways: both techniques must establish one or more base cases, and secondly, we do not need to carry the problem all the way to the solution. These similarities help us learn the recursion algorithm [8].
To review the mathematical induction technique, we consider a geometric sequence in this form:

We find a formula to compute the partial sum of the first n items [9]:

Assuming we do not know how to derive this formula, we want to prove that the equation is correct. The mathematical induction technique helps us to prove the equation:
Step 1: Show the equation is true for the first case, i.e., n = 1:

Step 2: Show that, if the equation is true when n = k, then it is true when n = k+1:
Assuming it is true for n = k, then we have this equation:
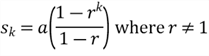
We add the (k+1)th item,
 ,
to the both sides:
,
to the both sides:

The left side is
 .
We check if the equation is true for n = k+1
.
We check if the equation is true for n = k+1
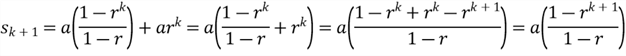
The equation holds when computing the sum of the first (k+1) items. Therefore, we can conclude that the equation is correct. We end the proof using the mathematical induction technique.
Even though the mathematical induction has two steps, we can think of this proof as a sequence of proofs:
When n = 1, we prove the equation explicitly in Step 1;
In step 2, we prove the equation is true for n = k + 1 if it is true when n = k. Because the equation is true for n = 1, we know it is true for n = 2;
Because the equation is correct for n = 2, it is true for n = 3;
Because the equation is correct for n = 3, it is true for n = 4;
This sequence continues endlessly, and we are sure that the equation is correct for any positive integer number of n.
We proved the correctness of this equation, but we did not derive this equation. Now let us derive the equation:
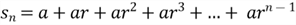
Multiply both sides by r:

Subtract two equations:

Rearrange the equation:

The mathematical induction and the derivative process are different. The difference reminds us that we do not need to think about the equation's derivation when using mathematical induction techniques to prove this equation. This point also holds when we use recursive techniques.
For demonstration, we compute the sum of the first three items in the geometric sequence:
- When we compute the sum of the first three items, i.e., n= 3, we want to know the result for n = 2.
- To find the result for n = 2, we need the result for n = 1.
- The base case for the recursive function is n = 1, i.e., we know the result for n = 1.
- We combine all these results as the solution to the initial problem.
Just as the mathematical induction technique does not need to derive the equation, the recursive technique does not require knowing how to compute the sum of the items in the sequence in detail. Instead, the recursive technique follows a pattern of getting the sum of the first n items using the computed sum of the first (n-1) terms.
3 – Design Recursive Algorithms
We studied two recursive function examples and two recursive procedure examples. In these examples, we solved complex problems by decomposing them into smaller instances of the same problem. Then, we used the same decompositional technique to subdivide each of these subproblems into new simpler subproblems. Eventually, the subproblems became so simple that the solutions were apparent, and we did not need to divide them further. We consolidated all these solved components as the solution to the original problem. In order to make the process more concrete and actionable, we generalize a five-step process to design a recursive algorithm [11]:
- Determine the size of the problem. The size is a property that measures the complexity of the problem. In many problems, size is one of the input parameters of the recursive functions or methods.
- Define base cases. Bases cases associate with the smallest instance of the original problem. A recursive program begins by testing whether its size meets any base case condition. Any possible chain of recursive calls should eventually reach one base case. The handling of base cases should not make any further recursive calls [12].
- Decompose the problem into smaller instances of the same problem. The decomposing process should be able to decrease the problem size.
- Define recursive cases. The algorithm handles recursive cases if the problem size does not meet any base case condition. When handling these recursive cases, the program makes recursive calls; each recursive call should reduce the problem size and make progress toward a base case.
- Write pseudo-code to implement the algorithm.
An effective strategy to learn any programming concept, including recursive techniques, is to learn by doing. Let us tackle a real-world problem:
When you review your web site, some hyperlinks on the site worked correctly on the day when the contents went online. However, these hyperlinks may not be accessible now. To improve user experience, we want to go through all web pages on the site and discover all inaccessible links.
First, we determine the size of the problem. The size is the number of unvisited hyperlinks on the website. These hyperlinks may associate with internal pages or external pages. Since we do not need to check hyperlinks on external websites, we consider external pages do not contain any hyperlinks. We can use the same algorithm to handle internal hyperlinks and external hyperlinks. The initial value of the size is equal to the total number of hyperlinks, which is a constant (or approximate to a constant) at the moment of web scraping. In each recursive call, the number of unvisited hyperlinks tends to decrease, and the number of visited hyperlinks increases.
Then, we look at base cases. We define the size of the problem, but it impractical to know the size. We maintain a list of visited hyperlinks. This list tends to grow in each recursive call. When we cannot find any unvisited hyperlinks, the problem size reduces to zero. Thus, we have two base case conditions:
- a hyperlink is not accessible;
- the web page associated with a hyperlink does not contain any unvisited hyperlinks.
Next, when we use the same algorithm to handle each hyperlink, the problem size automatically decreases. This kind of problem is naturally recursive. When we correctly determine the problem size, we immediately know how to decompose the original problem.
After we define the problem size and base cases, we define recursive cases. When the problem size is not zero, there should be unvisited hyperlinks in the list. The program invokes the recursive method to process each unvisited hyperlink.
Finally, we write pseudo-code to implement the algorithm:
def getLinks(pageUrl): hyperlinks = extractNewHyperlinksInPage(pageUrl) if failed to access the pageUrl: # Base case 1 savePageUrl(pageUrl) else if len(hyperlinks) = 0: # Base case 2 pass else: # Recursive case for each pageUrl in hyperlinks: getLinks(pageUrl) # Make a recursive call
4 – A Real-World Example
We designed the recursive algorithm in Section 3. We need to collect all hyperlinks on every web page of your web site and check if we can access these hyperlinks. We store these hyperlinks in a database table for further analysis and verification.
4.1 Design the Web Scraping Data Model
When we write a program to collect data from websites, a common mistake is to define a data model based on content on websites [14]. Such a data model is unsustainable because different websites use different formats to store information. We may need to add new attributes to the data model when scraping other web sites. We should design the data model based on business requirements and, then, find ways to hunt for information.
To provide site administrators with useful information about hyperlinks, the information we collect should uniquely identify a hyperlink:
- The web address (i.e., URL) of the hyperlink;
- The web address of the page that contains the hyperlink;
- The link text;
- The accessibility of the hyperlink;
- The audit date;
With this information, site administrators can quickly locate a hyperlink and perform further analysis. This data model does not tie-up to any specific website. If we decide to store some information from specific websites, adding new attributes to this data model may not be a good idea. The data model design for web scraping is not in the scope of this tip. However, we should know we need to design a data model for web scraping.
To save data to persistent storage, we create a database table in SQL server:
CREATE TABLE [dbo].[WebPages]( [PageId] [int] IDENTITY(1,1) NOT NULL, [PageUrl] [nvarchar](max) NOT NULL, [ContainerUrl] [nvarchar](max) NOT NULL, [LinkTitle] [nvarchar](max) NOT NULL, [Accessible] [bit] NULL, [DateAudit] [datetime] NOT NULL, CONSTRAINT [PK_WebPages] PRIMARY KEY CLUSTERED([PageId] ASC) )
4.2 Python Implementation
The Hyperlink data model holds information about a hyperlink. When we make a recursive function call, we pass a Hyperlink instance from a caller to a callee. We use the Beautiful Soup package [15] to extract all hyperlinks on a web page and use the pyodbc module to access a SQL server database. We can find the version of Beautiful Soup from the requirements.txt generated from the Python virtual environment:
beautifulsoup4==4.9.1 pip==19.2.3 pyodbc==4.0.30 setuptools==41.2.0 soupsieve==2.0.1 We convert the algorithm in Section 3 into the Python code implementation. We use some helper functions to keep code concise, clean, and readable. The program tracks visited web addresses; the program scans a page only when the URL is not in the list of visited URLs. During the execution, each hyperlink on the site makes a recursive call until one base case occurs. def getHyperlinks(hyperLink, visitedPages = set()): blnInternalLink, blnAccessible, bs = accessWebPage(hyperLink) if blnInternalLink == True and blnAccessible== True: hyperlinks = extractNewHyperlinksInBSObject(bs,hyperLink,visitedPages) else: hyperlinks = set() if blnAccessible == False: logVisitedPages(hyperLink, 0) elif len(hyperlinks) == 0: pass else: for link in hyperlinks: getHyperlinks(link, visitedPages)
4.3 The Complete Source Code of the Example
With the use of the Beautiful Soup package and the pyodbc module, we convert the algorithm design into Python code, as shown in the following. Depending on the scale of a website, the program may take several hours. We also should know the fact that the Python interpreter limits the depths of recursion. Python's default recursion limit is 1000, which is probably enough for most projects. For further information on this limit, check out sys.getrecursionlimit() and sys.setrecursionlimit() [16].
To test code, we can quickly use any web project template in Visual Studio 2019 to create a simple website. Then, we watch how the program goes through each page and processes hyperlinks on the page. As web scraping may have a detrimental effect on the target websites, some site administrators block scraping.
from urllib.request import urlopen, Request, URLError from urllib.parse import urljoin, urlparse from bs4 import BeautifulSoup from os import path import collections import pyodbc import re def logVisitedPages(hyperLink, blnAccessible): dbConn = createDBConnection() InserDataIntoDB(dbConn,hyperLink, blnAccessible) closeDBConnection(dbConn) def createDBConnection(): server = '.' database = yourDatabase dbConn = pyodbc.connect(Driver="{SQL Server}",Server=server,Database=database,Trusted_Connection="Yes") return dbConn def closeDBConnection(dbConn): dbConn.close() def InserDataIntoDB(dbConn,hyperLink, blnAccessible): cursor = dbConn.cursor() sqlStatement = constructSQLStatement(hyperLink, blnAccessible) if sqlStatement != None: cursor.execute(sqlStatement) dbConn.commit() def constructSQLStatement(hyperLink, blnAccessible): pageUrl = hyperLink.Url.replace("'","") containerUrl = hyperLink.ContainerUrl.replace("'","") linkTitle = hyperLink.LinkTitle.replace("'","") sqlStatement = "INSERT INTO [dbo].[WebPages]([PageUrl],[ContainerUrl],[LinkTitle],[Accessible],[DateAudit]) \ VALUES ('{}','{}','{}',{}, getdate())".format(pageUrl,containerUrl,linkTitle,blnAccessible) return sqlStatement def accessWebPage(hyperLink): blnInternalLink = False blnAccessible = False bs = None try: req = Request(hyperLink.Url) req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)') response = urlopen(req) if response.getcode() == 200: blnAccessible = True if hyperLink.Url.lower().startswith(hyperLink.BaseUrl.lower()): blnInternalLink = True bs = BeautifulSoup(response, 'html.parser') pageTitle = bs.find("title") if pageTitle != None: blnAccessible = not pageTitle.get_text().startswith('Error 404') except URLError: blnAccessible = False except: pass return blnInternalLink, blnAccessible, bs def extractValidUrl(link, container): isValid = True url = link.attrs['href'].strip() absoluteUrl = urljoin(container.BaseUrl,url) absoluteUrl = absoluteUrl.lower().split("#")[0] for token in ['mailto','@','<','\n']: if absoluteUrl.find(token) > -1: isValid = False for extension in ['.doc','.docx','.xls','.xlsx','.csv','pdf','exe','zip','jpg','jpeg']: if absoluteUrl.find(extension) > -1: isValid = False if urlparse(absoluteUrl)[0] not in ("http","https"): isValid = False return absoluteUrl, isValid def extractlinkTitle(link): linkTitle = link.text if not linkTitle: linkImg = link.find('img', src=True) if linkImg: if 'title' in linkImg: linkTitle = img['title'] elif 'alt' in linkImg: linkTitle = linkImg['alt'] else: linkTitle = path.basename(linkImg['src']) return linkTitle def extractLinkInfo(link, container): url, isValid = extractValidUrl(link, container) linkTitle = extractlinkTitle(link) return HyperLink(Url=url, LinkTitle = linkTitle, ContainerUrl = container.Url, IsValid = isValid, BaseUrl = container.BaseUrl) def extractNewHyperlinksInBSObject(bs,hyperLink, visitedPages): hyperlinks = set() try: for link in bs.find_all('a'): if 'href' in link.attrs: childHyperLink = extractLinkInfo(link, hyperLink) if childHyperLink.IsValid == True and childHyperLink.Url not in visitedPages: visitedPages.add(childHyperLink.Url) hyperlinks.add(childHyperLink) print(childHyperLink.Url) # For debugging logVisitedPages(childHyperLink, 'null') except: pass return hyperlinks def getHyperlinks(hyperLink, visitedPages = set()): blnInternalLink, blnAccessible, bs = accessWebPage(hyperLink) if blnInternalLink == True and blnAccessible== True: hyperlinks = extractNewHyperlinksInBSObject(bs,hyperLink,visitedPages) else: hyperlinks = set() if blnAccessible == False: logVisitedPages(hyperLink, 0) elif len(hyperlinks) == 0: pass else: for link in hyperlinks: getHyperlinks(link, visitedPages) if __name__ == "__main__": websiteUrl = 'https://www.yourwebsite.com/' HyperLink = collections.namedtuple('HyperLink', 'Url, LinkTitle, ContainerUrl, IsValid, BaseUrl') homePage = HyperLink(Url=websiteUrl, LinkTitle='YourTitle', ContainerUrl=websiteUrl, IsValid = True, BaseUrl = websiteUrl) getHyperlinks(homePage) print("The program ran successfully!")
Summary
With the use of recursion, solutions to complex problems may be surprisingly concise, easily understood, and algorithmically efficient [4]. Unlike other problem-solving techniques, such as looping, which provide common-sense solutions, recursion needs us to think about problems in a new way.
We started the tip with the Tower of Hanoi, and we provided a concise, elegant solution to the puzzle. Then, we introduced the recursive algorithm behind the solution. We categorized recursion into two types: recursive functions and recursive procedures. Some problems are naturally recursive; it is easy to solve them when we think recursively. Recursion should be in our problem-solving toolbox.
After a brief overview of the basic idea behind recursion, i.e., the divide and conquer approach, we gave two classic recursive examples for each recursion type. We summarized four critical characteristics of recursive definitions.
While on the subject of thinking recursively, we presented the mathematical induction technique, which helps us to have faith in recursion’s correctness. We then concluded a five-step procedure for designing a recursive algorithm. We tackled a real-world problem using the procedure.
Finally, we gave a complete source code in Python for a real-world project. We used Beautiful Soup to search all hyperlinks on a web page and use pyodbc module to access a SQL server database. We wrote several helper functions to keep the code clean and concise.
Reference
[1] Pierre, S. (2020). Recursion in Python. Retrieve from Towards Data Science: https://towardsdatascience.com/recursion-in-python-b026d7dde906.
[2] Thapliyal, R. (2014). Program for Tower of Hanoi. Retrieve from GeeksforGeeks: https://www.geeksforgeeks.org/c-program-for-tower-of-hanoi/.
[3] Wanggonta, K. (2019). Fibonacci sequence with Python recursion and memorization. Retrieve from DEV: https://dev.to/wangonya/fibonacci-sequence-with-python-recursion-and-memoization-f7h.
[4] Roberts, E. (2005). Thinking Recursively with Java. Hoboken, NJ: John Wiley & Sons
[5] Sheena. (2018). Python Recursion by Example. Retrieve from Code Mentor Community: https://www.codementor.io/@sheena/python-recursion-by-example-n8v9zlans.
[6] MathsIsFun. (2018). Tower of Hanoi. Retrieve from MathsIsFun: https://www.mathsisfun.com/games/towerofhanoi.html.
[7] Rout, R. A. (2020). Types of Recursions. Retrieve from GeeksforGeeks: https://www.geeksforgeeks.org/types-of-recursions/.
[8] Smith, Y. (2019). No Need to Know the End: Recursive Algorithm and Mathematical Induction. Retrieve from Towards Data Science: https://towardsdatascience.com/no-need-to-know-the-end-recursion-algorithm-and-mathematical-induction-5a9e4c747c3c.
[9] Wikipedia. (2020). Geometric series. Retrieve from Wikipedia: https://en.wikipedia.org/wiki/Geometric_series.
[10] Python Doc. (2020). os — Miscellaneous operating system interfaces. Retrieve from The Python Software Foundation: https://docs.python.org/3/library/os.html.
[11] Rubio-Sanchez, M., (2017). Introduction to Recursive Programming. Boca Raton, FL: CRC Press.
[12] Goodrich, T. M., Tamassia & R. Goldwasser, H. M. (2013). Data Structures and Algorithms in Python. Hoboken, NJ: John Wiley & Sons.
[13] MSSQLTips. (2020). About MSSQLTips. Retrieve from MSSQLTips: https://www.mssqltips.com/about/.
[14] Mitchell, R. (2018). Web Scraping with Python, 2nd Edition. Sebastopol, CA: O'Reilly Media.
[15] Crummy. (2020). Beautiful Soup. Retrieve from Crummy: https://www.crummy.com/software/BeautifulSoup/.
[16] Python Doc. (2020). sys — System-specific parameters and functions. Retrieve from The Python Software Foundation: https://docs.python.org/3/library/sys.html.
Next Steps
- We provide four classic examples of recursive algorithms. As a good exercise, we can solve these sample problems using a recursive and an iterative technique and, then, contrast problem-solving strategies. This tip categorizes recursion into two types: recursive function and recursive procedure. To apply recursive techniques and proceed to more advanced topics, we should also know other categorization methods. Some texts may introduce these types of recursion: linear recursion, tail recursion, binary recursion, and multiple recursions. The last example provided in this tip is to go through all hyperlinks on a website, tag those inaccessible hyperlinks, and store all these visited web addresses into a database table. There is much room for improvement to the sample code. For example, we can record error codes when a page is not accessible.
- Check out these related tips:
- Learning Python in Visual Studio 2019
- Python Programming Tutorial with Top-Down Approach
- Web Screen Scraping with Python to Populate SQL Server Tables
- Beginners Guide to Python for SQL Server Professionals
- Data Science: Cleansing Your Data Using Python
- Scraping HTML Tables with Python to Populate SQL Server Tables






About the author
 Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.
Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2020-09-17
