By: Andrea Gnemmi | Updated: 2021-01-04 | Comments | Related: > SQL Server vs Oracle vs PostgreSQL Comparison
Problem
As most DBA's and developers that work with both SQL Server and Oracle already know, there are some differences in how you update rows using a join between SQL Server and Oracle. Notably, this is not possible with Oracle without some finesse. PostgreSQL has a similar ANSI SQL approach as SQL Server. In this article we compare how to execute updates when using a join between SQL Server, Oracle and PostgreSQL.
Solution
Below we will do a comparison of the different syntax used to update data when using a join.
A note regarding the terminology: in Oracle we will not have a database named Chinook, but a schema or more properly a User. In Oracle, unless you use Pluggable Databases, you can have only one database per instance.
For test purposes I will use the free downloadable database sample Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store with some sample data. All you have to do is download the version you need and run the scripts for the data structure as well as inserting the data.
SQL Server Update Statement with Join
We will start with a quick reminder of how a SQL UPDATE statement with a JOIN works in SQL Server.
Normally we update a row or multiple rows in a table with a filter based on a WHERE clause. We check for an error and find that there is no such city as Vienne. But rather, Wien in German or Vienna in English:
select customerid, FirstName,LastName, Address, city,country from dbo.Customer where city='Vienne'

We can correct this with a normal UPDATE statement such as:
update dbo.Customer set city='Wien' where city='Vienne'

We can also update the invoice table based on a customer. First, let's check the data with a simple SELECT query:
select invoice.BillingCity from invoice inner join customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne'
We have this result:
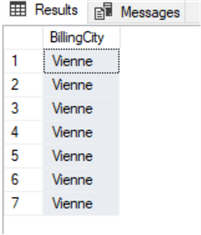
At this point we can do an UPDATE using the same JOIN clause as the SELECT query that we just did. I know that we could have used a simple UPDATE to the one table, but this example just shows how it can be done when doing a JOIN:
update invoice set invoice.BillingCity='Wien' from invoice inner join customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne'

We can even use a CTE (Common Table Expression) in the JOIN clause in order to have some particular filter.
For example, suppose we need to give a special discount on the total invoice for Austrian customers who spent more than 20 dollars on Rock and Metal (genre 1 and 3). The subset is easily extracted with the following query:
select Invoice.CustomerId,sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20
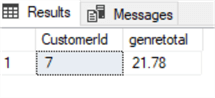
Suppose we want to apply a discount of 20%. We can apply it updating the total invoice table based on the above query using the below CTE:
; with discount as ( select Invoice.CustomerId, sum(invoiceline.UnitPrice*Quantity) as genretotal from invoice inner join InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join Track on Track.TrackId=InvoiceLine.TrackId inner join customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) update Invoice set total=total*0.8 from Invoice inner join discount on Invoice.CustomerId=discount.CustomerId
Oracle Update Statement with Join
How does this work in Oracle? The answer is pretty straightforward: in Oracle this syntax of UPDATE statement with a JOIN is not supported.
We must do some shortcuts in order to do something similar. We can make use of a subquery and an IN filter. For example, we can transform the first UPDATE with the JOIN that we used in SQL Server.
First, let's check with the same SELECT query the data of Invoice table in Oracle:
select invoice.BillingCity from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne';

We will transform the UPDATE statement using the above query as a subquery, but we will extract the primary key Invoiceid in order to do the update:
update chinook.invoice set invoice.BillingCity='Wien' where invoiceid in ( select invoiceid from chinook.invoice inner join chinook.customer on invoice.CustomerId=customer.CustomerId where customer.City='Vienne' );

Don't forget to commit. Since we are in Oracle, there is no auto commit by default:
commit;
That was quite easy, but let's suppose that we need to an UPDATE based on another big table and use the value in the other table.
Suppose that we would like to do the same UPDATE like we did with the CTE on SQL Server, we can overcome the JOIN problem with this code:
update
( select invoice.customerid,total
from chinook.Invoice
inner join
( select Invoice.Cust merId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal
from chinook.invoice
inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId
inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId
inner join chinook.customer on customer.CustomerId=Invoice.CustomerId
where country='Austria' and GenreId in (1,3)
group by Invoice.CustomerId
having sum(invoiceline.UnitPrice*Quantity)>20
)
on Invoice.CustomerId=Customerid_sub
)
set total=total*0.8;
commit;
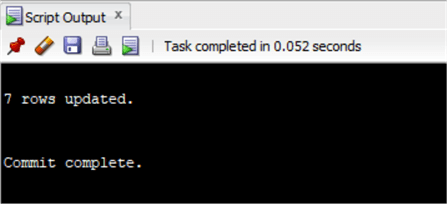
As you may have noticed, I transformed the CTE in a subquery and joined it with the Invoice table similar to the update done with SQL Server. But this time it is a select statement with the primary key and the total that we'd like to update. I've put this result as the table to update. It is a workaround, but it works! Only thing you have to be careful about is ensuring that the results are unique and you are not trying to update more rows than the ones you need. This is why I always do a select before to check how many rows should be updated.
There is a more elegant solution, making use of the MERGE statement. The syntax is similar to MERGE in SQL Server so we will use the same UPDATE as in the last example. This should be written like this:
MERGE INTO chinook.Invoice USING ( select Invoice.CustomerId as customerid_sub, sum(invoiceline.UnitPrice*Quantity) as genretotal from chinook.invoice inner join chinook.InvoiceLine on Invoice.InvoiceId=InvoiceLine.InvoiceId inner join chinook.Track on Track.TrackId=InvoiceLine.TrackId inner join chinook.customer on customer.CustomerId=Invoice.CustomerId where country='Austria' and GenreId in (1,3) group by Invoice.CustomerId having sum(invoiceline.UnitPrice*Quantity)>20 ) ON (Invoice.CustomerId=Customerid_sub) WHEN MATCHED THEN UPDATE set total=total*0.8;
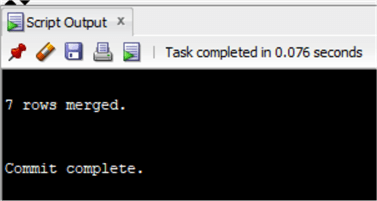
As you can see, it is more readable than the previous solution. In SQL Server, performance of MERGE statements is not always the best. Keep this in mind when using it and test it before use in a production environment.
PostgreSQL Update Statement with Join
What about PostgreSQL? In this case, the same concepts that work in SQL Server do the job also on PostgreSQL. We have just a few differences with the syntax as we do not specify the join. But we use the old join syntax with the WHERE clause.
Let's adapt the same SQL code we have used on SQL Server and test it on the Chinook database on PostgreSQL:
update "Invoice" set "BillingCity"='Wien' from "Customer" where "Invoice"."CustomerId"="Customer"."CustomerId" and "Customer"."City"='Vienne'

In this case we do not need to specify the first table on which we will do the update. The rest is exactly the same as in SQL Server.
Let's test the code with the CTE (please note that in PostgreSQL we need to put all column names that have been created with a capital letter under quotes otherwise it will not recognize them!):
; with discount as
( select "Invoice"."CustomerId", sum("InvoiceLine"."UnitPrice"*"Quantity") as genretotal
from "Invoice"
inner join "InvoiceLine" on "Invoice"."InvoiceId"="InvoiceLine"."InvoiceId"
inner join "Track" on "Track"."TrackId"="InvoiceLine"."TrackId"
inner join "Customer" on "Customer"."CustomerId"="Invoice"."CustomerId"
where "Country"='Austria' and "GenreId" in (1,3)
group by "Invoice"."CustomerId"
having sum("InvoiceLine"."UnitPrice"*"Quantity")>20
)
update "Invoice"
set "Total"="Total"*0.8
from discount
where "Invoice"."CustomerId"=discount."CustomerId"

Summary
In this tip we've seen the syntax differences for UPDATE statements when using a JOIN in SQL Server, Oracle and PostgreSQL.
Next Steps
- There are other ways of updating with joins in Oracle, notably using the WHERE EXISTS clause with subqueries. But it is similar to what was achieved using the syntax that I've employed in my code example.
- Please note that I have used SSMS for SQL Server, SQL Developer for Oracle and PGAdmin for PostgreSQL. All are available for download free of charge.






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-01-04
