By: Ron L'Esteve | Updated: 2021-01-20 | Comments (2) | Related: > Azure Data Factory
Problem
In my previous article, Logging Azure Data Factory Pipeline Audit Data, I discussed a variety of methods for capturing Azure Data Factory pipeline logs and persisting the data to either a SQL Server table or within Azure Data Lake Storage Gen2. While this process of capturing pipeline log data is valuable when the pipeline activities succeed, how can we also capture and persist error details related to Azure Data Factory pipelines when activities within the pipeline fail?
Solution
In this article, I will cover how to capture and persist Azure Data Factory pipeline errors to an Azure SQL Database table. Additionally, we will re-cap the pipeline parameter process that I had discussed in my previous articles to demonstrate how the pipeline_errors, pipeline_log, and pipeline_parameter relate to each other.
Explore and Understand the Meta-Data driven ETL Approach
Prior to continuing with the demonstration, try to read my previous articles as a pre-requisite to gain background and knowledge around the end-to-end meta-data driven E-T-L process.
- Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2
- Load Data Lake files into Azure Synapse Analytics Using Azure Data Factory
- Loading Azure SQL Data Warehouse Dynamically using Azure Data Factory
- Logging Azure Data Factory Pipeline Audit Data
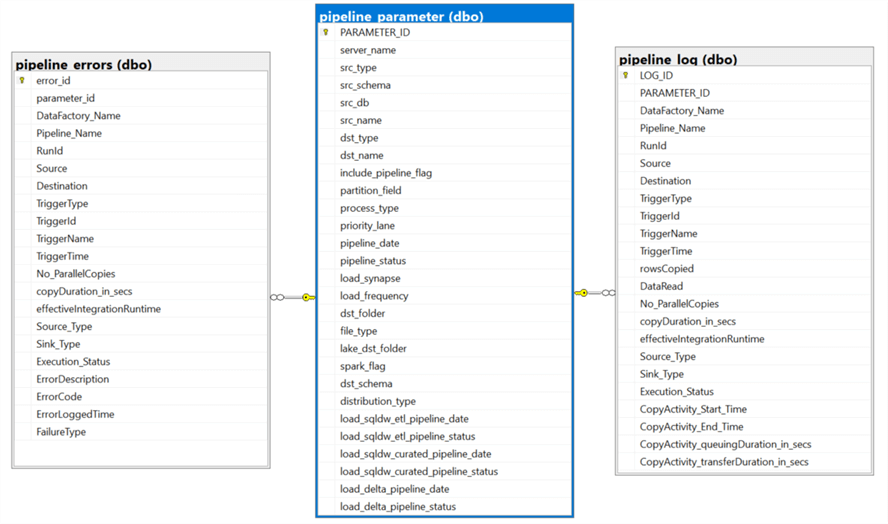
To re-cap the tables needed for this process, I have included the diagram below which illustrates how the pipeline_parameter, pipeline_log, and pipeline_error tables are interconnected with each other.
Create a Parameter Table
The following script will create the pipeline_parameter table with column parameter_id as the primary key. Note that this table drives the meta-data ETL approach.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_parameter]( [PARAMETER_ID] [int] IDENTITY(1,1) NOT NULL, [server_name] [nvarchar](500) NULL, [src_type] [nvarchar](500) NULL, [src_schema] [nvarchar](500) NULL, [src_db] [nvarchar](500) NULL, [src_name] [nvarchar](500) NULL, [dst_type] [nvarchar](500) NULL, [dst_name] [nvarchar](500) NULL, [include_pipeline_flag] [nvarchar](500) NULL, [partition_field] [nvarchar](500) NULL, [process_type] [nvarchar](500) NULL, [priority_lane] [nvarchar](500) NULL, [pipeline_date] [nvarchar](500) NULL, [pipeline_status] [nvarchar](500) NULL, [load_synapse] [nvarchar](500) NULL, [load_frequency] [nvarchar](500) NULL, [dst_folder] [nvarchar](500) NULL, [file_type] [nvarchar](500) NULL, [lake_dst_folder] [nvarchar](500) NULL, [spark_flag] [nvarchar](500) NULL, [dst_schema] [nvarchar](500) NULL, [distribution_type] [nvarchar](500) NULL, [load_sqldw_etl_pipeline_date] [datetime] NULL, [load_sqldw_etl_pipeline_status] [nvarchar](500) NULL, [load_sqldw_curated_pipeline_date] [datetime] NULL, [load_sqldw_curated_pipeline_status] [nvarchar](500) NULL, [load_delta_pipeline_date] [datetime] NULL, [load_delta_pipeline_status] [nvarchar](500) NULL, PRIMARY KEY CLUSTERED ( [PARAMETER_ID] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO
Create a Log Table
This next script will create the pipeline_log table for capturing the Data Factory success logs. In this table, column log_id is the primary key and column parameter_id is a foreign key with a reference to column parameter_id from the pipeline_parameter table.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_log]( [LOG_ID] [int] IDENTITY(1,1) NOT NULL, [PARAMETER_ID] [int] NULL, [DataFactory_Name] [nvarchar](500) NULL, [Pipeline_Name] [nvarchar](500) NULL, [RunId] [nvarchar](500) NULL, [Source] [nvarchar](500) NULL, [Destination] [nvarchar](500) NULL, [TriggerType] [nvarchar](500) NULL, [TriggerId] [nvarchar](500) NULL, [TriggerName] [nvarchar](500) NULL, [TriggerTime] [nvarchar](500) NULL, [rowsCopied] [nvarchar](500) NULL, [DataRead] [int] NULL, [No_ParallelCopies] [int] NULL, [copyDuration_in_secs] [nvarchar](500) NULL, [effectiveIntegrationRuntime] [nvarchar](500) NULL, [Source_Type] [nvarchar](500) NULL, [Sink_Type] [nvarchar](500) NULL, [Execution_Status] [nvarchar](500) NULL, [CopyActivity_Start_Time] [nvarchar](500) NULL, [CopyActivity_End_Time] [nvarchar](500) NULL, [CopyActivity_queuingDuration_in_secs] [nvarchar](500) NULL, [CopyActivity_transferDuration_in_secs] [nvarchar](500) NULL, CONSTRAINT [PK_pipeline_log] PRIMARY KEY CLUSTERED ( [LOG_ID] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[pipeline_log] WITH CHECK ADD FOREIGN KEY([PARAMETER_ID]) REFERENCES [dbo].[pipeline_parameter] ([PARAMETER_ID]) ON UPDATE CASCADE GO
Create an Error Table
This next script will create a pipeline_errors table which will be used to capture the Data Factory error details from failed pipeline activities. In this table, column error_id is the primary key and column parameter_id is a foreign key with a reference to column parameter_id from the pipeline_parameter table.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_errors]( [error_id] [int] IDENTITY(1,1) NOT NULL, [parameter_id] [int] NULL, [DataFactory_Name] [nvarchar](500) NULL, [Pipeline_Name] [nvarchar](500) NULL, [RunId] [nvarchar](500) NULL, [Source] [nvarchar](500) NULL, [Destination] [nvarchar](500) NULL, [TriggerType] [nvarchar](500) NULL, [TriggerId] [nvarchar](500) NULL, [TriggerName] [nvarchar](500) NULL, [TriggerTime] [nvarchar](500) NULL, [No_ParallelCopies] [int] NULL, [copyDuration_in_secs] [nvarchar](500) NULL, [effectiveIntegrationRuntime] [nvarchar](500) NULL, [Source_Type] [nvarchar](500) NULL, [Sink_Type] [nvarchar](500) NULL, [Execution_Status] [nvarchar](500) NULL, [ErrorDescription] [nvarchar](max) NULL, [ErrorCode] [nvarchar](500) NULL, [ErrorLoggedTime] [nvarchar](500) NULL, [FailureType] [nvarchar](500) NULL, CONSTRAINT [PK_pipeline_error] PRIMARY KEY CLUSTERED ( [error_id] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [dbo].[pipeline_errors] WITH CHECK ADD FOREIGN KEY([parameter_id]) REFERENCES [dbo].[pipeline_parameter] ([PARAMETER_ID]) ON UPDATE CASCADE GO
Create a Stored Procedure to Update the Log Table
Now that we have all the necessary SQL Tables in place, we can begin creating a few necessary stored procedures. Let’s begin with the following script which will create a stored procedure to update the pipeline_log table with data from the successful pipeline run. Note that this stored procedure will be called from the Data Factory pipeline at run-time.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[sp_UpdateLogTable]
@DataFactory_Name VARCHAR(250),
@Pipeline_Name VARCHAR(250),
@RunID VARCHAR(250),
@Source VARCHAR(300),
@Destination VARCHAR(300),
@TriggerType VARCHAR(300),
@TriggerId VARCHAR(300),
@TriggerName VARCHAR(300),
@TriggerTime VARCHAR(500),
@rowsCopied VARCHAR(300),
@DataRead INT,
@No_ParallelCopies INT,
@copyDuration_in_secs VARCHAR(300),
@effectiveIntegrationRuntime VARCHAR(300),
@Source_Type VARCHAR(300),
@Sink_Type VARCHAR(300),
@Execution_Status VARCHAR(300),
@CopyActivity_Start_Time VARCHAR(500),
@CopyActivity_End_Time VARCHAR(500),
@CopyActivity_queuingDuration_in_secs VARCHAR(500),
@CopyActivity_transferDuration_in_secs VARCHAR(500)
AS
INSERT INTO [pipeline_log]
(
[DataFactory_Name]
,[Pipeline_Name]
,[RunId]
,[Source]
,[Destination]
,[TriggerType]
,[TriggerId]
,[TriggerName]
,[TriggerTime]
,[rowsCopied]
,[DataRead]
,[No_ParallelCopies]
,[copyDuration_in_secs]
,[effectiveIntegrationRuntime]
,[Source_Type]
,[Sink_Type]
,[Execution_Status]
,[CopyActivity_Start_Time]
,[CopyActivity_End_Time]
,[CopyActivity_queuingDuration_in_secs]
,[CopyActivity_transferDuration_in_secs]
)
VALUES
(
@DataFactory_Name
,@Pipeline_Name
,@RunId
,@Source
,@Destination
,@TriggerType
,@TriggerId
,@TriggerName
,@TriggerTime
,@rowsCopied
,@DataRead
,@No_ParallelCopies
,@copyDuration_in_secs
,@effectiveIntegrationRuntime
,@Source_Type
,@Sink_Type
,@Execution_Status
,@CopyActivity_Start_Time
,@CopyActivity_End_Time
,@CopyActivity_queuingDuration_in_secs
,@CopyActivity_transferDuration_in_secs
)
GO
Create a Stored Procedure to Update the Errors Table
Next, lets run the following script which will create a stored procedure to update the pipeline_errors table with detailed error data from the failed pipeline run. Note that this stored procedure will be called from the Data Factory pipeline at run-time.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[sp_UpdateErrorTable]
@DataFactory_Name [nvarchar](500) NULL,
@Pipeline_Name [nvarchar](500) NULL,
@RunId [nvarchar](500) NULL,
@Source [nvarchar](500) NULL,
@Destination [nvarchar](500) NULL,
@TriggerType [nvarchar](500) NULL,
@TriggerId [nvarchar](500) NULL,
@TriggerName [nvarchar](500) NULL,
@TriggerTime [nvarchar](500) NULL,
@No_ParallelCopies [int] NULL,
@copyDuration_in_secs [nvarchar](500) NULL,
@effectiveIntegrationRuntime [nvarchar](500) NULL,
@Source_Type [nvarchar](500) NULL,
@Sink_Type [nvarchar](500) NULL,
@Execution_Status [nvarchar](500) NULL,
@ErrorDescription [nvarchar](max) NULL,
@ErrorCode [nvarchar](500) NULL,
@ErrorLoggedTime [nvarchar](500) NULL,
@FailureType [nvarchar](500) NULL
AS
INSERT INTO [pipeline_errors]
(
[DataFactory_Name],
[Pipeline_Name],
[RunId],
[Source],
[Destination],
[TriggerType],
[TriggerId],
[TriggerName],
[TriggerTime],
[No_ParallelCopies],
[copyDuration_in_secs],
[effectiveIntegrationRuntime],
[Source_Type],
[Sink_Type],
[Execution_Status],
[ErrorDescription],
[ErrorCode],
[ErrorLoggedTime],
[FailureType]
)
VALUES
(
@DataFactory_Name,
@Pipeline_Name,
@RunId,
@Source,
@Destination,
@TriggerType,
@TriggerId,
@TriggerName,
@TriggerTime,
@No_ParallelCopies,
@copyDuration_in_secs,
@effectiveIntegrationRuntime,
@Source_Type,
@Sink_Type,
@Execution_Status,
@ErrorDescription,
@ErrorCode,
@ErrorLoggedTime,
@FailureType
)
GO
Create a Source Error SQL Table
Recall from my previous article, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2, that we used a source SQL Server Table that we then moved to the Data Lake Storage Gen2 and ultimately into Synapse DW. Based on this process, we will need to test a known error within the Data Factory pipeline and process. It is known that generally a varchar(max) datatype containing at least 8000+ characters will fail when being loaded into Synapse DW since varchar(max) is an unsupported data type. This seems like a good use case for an error test.
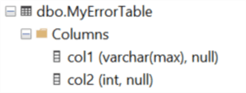
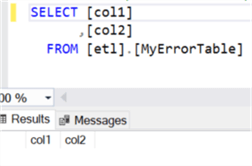
The following table dbo.MyErrorTable contains two columns with col1 being the varchar(max) datatype.
Within dbo.MyErrorTable I have added a large block of text and decided to randomly choose Sample text for Roma : the novel of ancient Rome by Steven Saylor. After doing some editing of the text, I confirmed that col1 contains 8001 words, which is sure to fail my Azure Data Factory pipeline and trigger a record to be created in the pipeline_errors table.

Add Records to Parameter Table
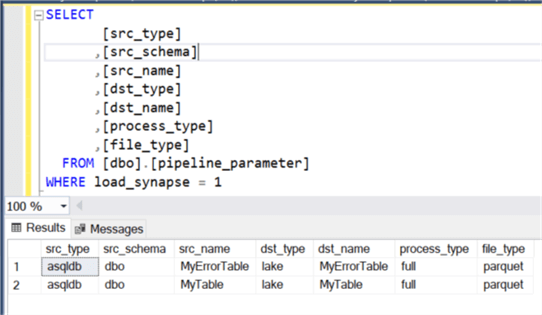
Now that we’ve identified the source SQL tables to run through the process, I’ll add them to the pipeline_parameter table. For this demonstration I have added the Error table that we created in the previous step along with a regular table that we would expect to succeed to demonstrate both a success and failure end to end logging process.
Verify the Azure Data Lake Storage Gen2 Folders and Files
After running the pipeline to load my SQL tables to Azure Data Lake Storage Gen2, we can see that the destination ADLS2 container now has both of the tables in snappy compressed parquet format.
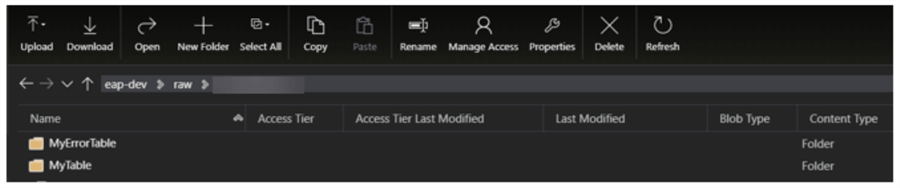
As an additional verification step, we can see that the folder contains the expected parquet file.
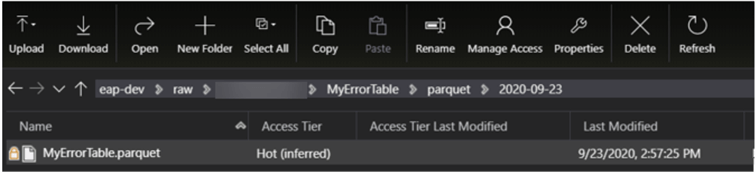
Configure the Pipeline Lookup Activity
It’s now time to build and configure the ADF pipeline. My previous article, Load Data Lake files into Azure Synapse Analytics Using Azure Data Factory, covers the details on how to build this pipeline. To recap the process, the select query within the lookup gets the list of parquet files that need to be loaded to Synapse DW and then passes them on to each loop which will load the parquet files to Synapse DW.
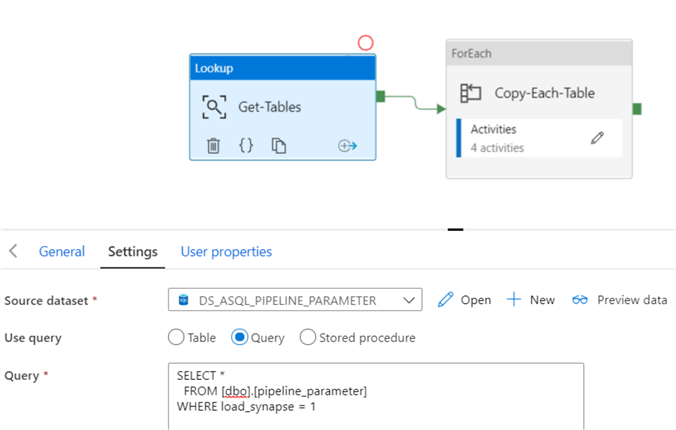
Configure the Pipeline Foreach Loop Activity
The Foreach loop contains the Copy Table activity with takes the parquet files and loads them to Synapse DW while auto-creating the tables. If the Copy-Table activity succeeds, it will log the pipeline run data to the pipeline_log table. However, if the Copy-Table activity fails, it will log the pipeline error details to the pipeline_errors table.
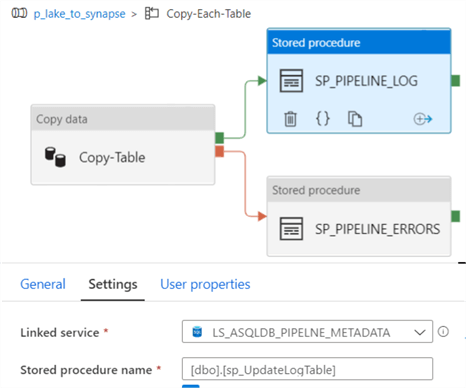
Configure Stored Procedure to Update the Log Table
Notice that the UpdateLogTable Stored procedure that we created earlier will be called by the success stored procedure activity.
Below are the stored procedure parameters that will Update the pipeline_log table and can be imported directly from the Stored Procedure.
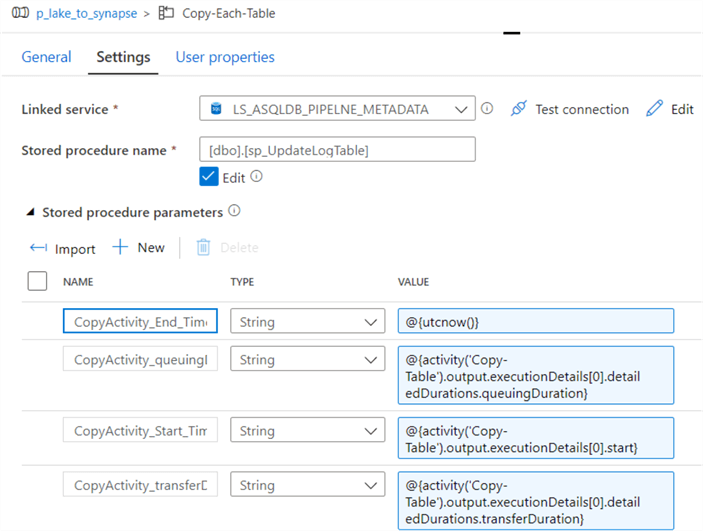
The following values will need to be entered into the stored procedure parameter values.
| Name | Values |
|---|---|
| DataFactory_Name | @{pipeline().DataFactory} |
| Pipeline_Name | @{pipeline().Pipeline} |
| RunId | @{pipeline().RunId} |
| Source | @{item().src_name} |
| Destination | @{item().dst_name} |
| TriggerType | @{pipeline().TriggerType} |
| TriggerId | @{pipeline().TriggerId} |
| TriggerName | @{pipeline().TriggerName} |
| TriggerTime | @{pipeline().TriggerTime} |
| rowsCopied | @{activity('Copy-Table').output.rowsCopied} |
| RowsRead | @{activity('Copy-Table').output.rowsRead} |
| No_ParallelCopies | @{activity('Copy-Table').output.usedParallelCopies} |
| copyDuration_in_secs | @{activity('Copy-Table').output.copyDuration} |
| effectiveIntegrationRuntime | @{activity('Copy-Table').output.effectiveIntegrationRuntime} |
| Source_Type | @{activity('Copy-Table').output.executionDetails[0].source.type} |
| Sink_Type | @{activity('Copy-Table').output.executionDetails[0].sink.type} |
| Execution_Status | @{activity('Copy-Table').output.executionDetails[0].status} |
| CopyActivity_Start_Time | @{activity('Copy-Table').output.executionDetails[0].start} |
| CopyActivity_End_Time | @{utcnow()} |
| CopyActivity_queuingDuration_in_secs | @{activity('Copy-Table').output.executionDetails[0]. detailedDurations.queuingDuration} |
| CopyActivity_transferDuration_in_secs | @{activity('Copy-Table').output.executionDetails[0]. detailedDurations.transferDuration} |
Configure Stored Procedure to Update the Error Table
The last stored procedure within the Foreach loop activity is the UpdateErrorTable Stored procedure that we created earlier and will be called by the failure stored procedure activity.
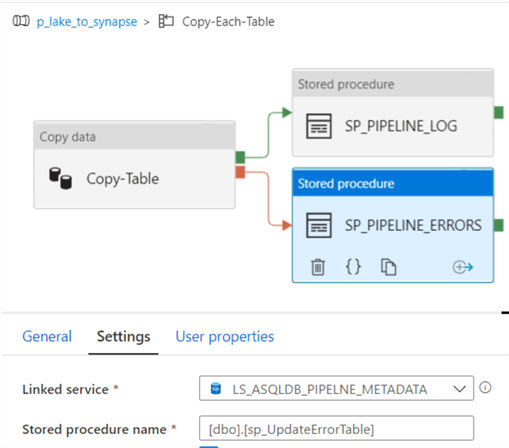
Below are the stored procedure parameters that will Update the pipeline_errors table and can be imported directly from the Stored Procedure.
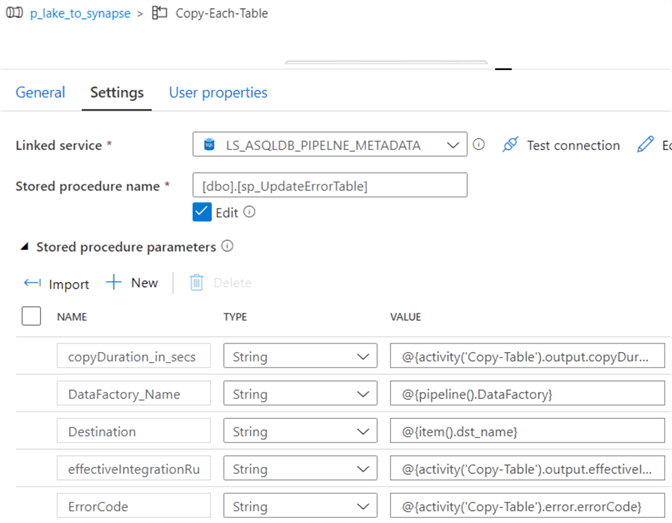
The following values will need to be entered into the stored procedure parameter values.
| Description | Source |
|---|---|
| DataFactory_Name | @{pipeline().DataFactory} |
| Pipeline_Name | @{pipeline().Pipeline} |
| RunId | @{pipeline().RunId} |
| Source | @{item().src_name} |
| Destination | @{item().dst_name} |
| TriggerType | @{pipeline().TriggerType} |
| TriggerId | @{pipeline().TriggerId} |
| TriggerName | @{pipeline().TriggerName} |
| TriggerTime | @{pipeline().TriggerTime} |
| No_ParallelCopies | @{activity('Copy-Table').output.usedParallelCopies} |
| copyDuration_in_secs | @{activity('Copy-Table').output.copyDuration} |
| effectiveIntegrationRuntime | @{activity('Copy-Table').output.effectiveIntegrationRuntime} |
| Source_Type | @{activity('Copy-Table').output.executionDetails[0].source.type} |
| Sink_Type | @{activity('Copy-Table').output.executionDetails[0].sink.type} |
| Execution_Status | @{activity('Copy-Table').output.executionDetails[0].status} |
| ErrorCode | @{activity('Copy-Table').error.errorCode} |
| ErrorDescription | @{activity('Copy-Table').error.message} |
| ErrorLoggedTIme | @utcnow() |
| FailureType | @concat(activity('Copy-Table').error.message,'failureType:',activity('Copy-Table').error.failureType) |
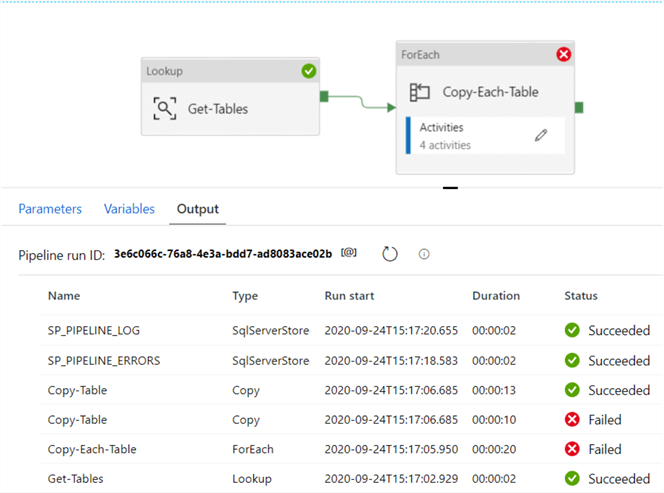
Run the Pipeline
Now that we have configured the pipeline, it is time to run the pipeline. As we can see from the debug mode Output log, one table succeeded and the other failed, as expected.
Verify the Results
Finally, lets verify the results in the pipeline_log table. As we can see, the pipeline_log table has captured one log containing the source, MyTable.

And the pipeline_errors table now has one record for MyErrorTable, along with detailed error codes, descriptions, messages and more.

As a final check, when I navigate to the Synapse DW, I can see that both tables have been auto-created, despite the fact that one failed and one succeeded.

However, data was only loaded in MyTable since MyErrorTable contains no data.
Next Steps
- For alternative methods of capturing logs, read Monitor and Alert Data Factory by using Azure Monitor
- For alternative methods of capturing errors, read Get Any Azure Data Factory Pipeline Activity Error details with Azure Functions.






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-01-20
