By: Eric Blinn | Updated: 2021-02-16 | Comments | Related: > Functions System
Problem
I've heard that SQL Server window functions can help improve certain types of queries. Can you show me some examples of this and how to make queries run faster?
Solution
Window functions have several use cases when writing TSQL statements. They can help rank the rows of a dataset or they can be used to create aggregations of a column of data across a limited number of rows, such as a sum of the last 30 rows instead of a sum of all the rows.
This tip will show 2 different ways that window functions can help a query run faster when compared to an older methodology that was popular before SQL Server added these functions. Each example we will show the older way to implement the query along with the window function method. It will compare the performance of each to quantify the improvement
This tip assumes a basic knowledge of what STATISTICS IO and STATISTICS TIME are and what query plans are. If unfamiliar with these features, this tip will offer a primer on STATISTICS TIME and IO and this tip will cover query plans. Both will prepare the reader for the information in this tip.
All of the demos in this tip will use the WideWorldImporters sample database which can be downloaded from here and will be run against SQL Server 2019. The images may be different, but the methodology should still work on older versions of SQL Server.
Overview of SQL Window Functions for Ranking Rows
One of the main uses of window ranking functions such as ROW_NUMBER, RANK, and DENSE_RANK is to rank a set of rows based on sorting criteria.
These functions can either rank an entire dataset or it can rank separate partitions. Think of a partition as a GROUP BY for the window function. Where a GROUP BY allows for separate aggregates to be performed on each unique column value set, a PARTITION BY in a window function starts the ranking process with the OVER clause at each change PARTITION BY column change. This will make more sense in the examples below.
Consider this query using window function ROW_NUMBER().
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber, il.ExtendedPrice, ROW_NUMBER() OVER (ORDER BY il.ExtendedPrice DESC) RowRank FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.BillToCustomerID = c.CustomerID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014';
This query window function starts at 1 and counts up as the ExtendedPrice goes down, as shown below in the result set.

Next, a PARTITION BY will be added to the window function on the BillToCustomerID column.
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber, il.ExtendedPrice, ROW_NUMBER() OVER (PARTITION BY i.BillToCustomerID ORDER BY il.ExtendedPrice DESC) RowRank FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.BillToCustomerID = c.CustomerID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014';
Notice how the RowRank column starts at 1 and counts up like before, but now at every change in customer based on BillToCustomerID it resets to 1 and starts counting up again. This feature is the part that often makes this function so powerful.
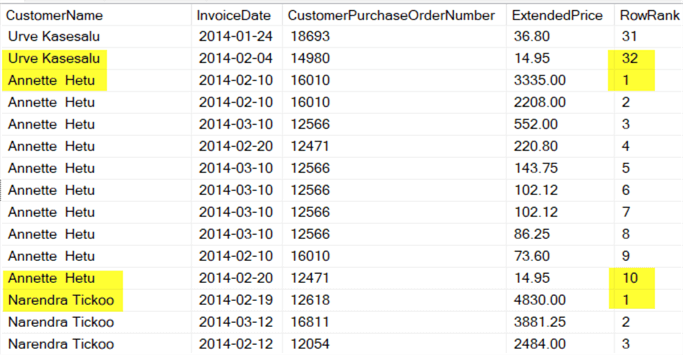
Ranking Rows Tutorial in SQL Server
Ranking rows using a window function and a PARTITION BY is a great way reduce the size and complexity of some queries that require subqueries.
Query Syntax without a Window Function
Consider the query below from this previous tip. A TSQL developer has been tasked with finding the invoice date and purchase order number for each customer's largest individual purchase during the first quarter of 2014. The solution from that tip did not include a window function – but maybe it should have!
The former solution has 2 parts.
- In the first part, the TopPurchase CTE, calculates the amount of the highest purchase for each customer.
- In the second part, a similar query is run to include the details of that query.
-- first query without window function
WITH TopPurchase AS( SELECT BillToCustomerID, MAX(ExtendedPrice) Amt
FROM Sales.Invoices i
INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID
WHERE
InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014'
GROUP BY
BillToCustomerID
)
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber
FROM Sales.Invoices i
INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID
INNER JOIN Sales.Customers c ON i.CustomerID = c.CustomerID
INNER JOIN TopPurchase t ON t.BillToCustomerID = i.BillToCustomerID AND t.Amt = il.ExtendedPrice
WHERE
InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014';
Query Syntax with a Window Function
How can this be accomplished with a window function? Start by implementing the window function that partitions by BillToCustomerID and sorts the amounts descending order.
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber, il.ExtendedPrice, RANK() OVER (PARTITION BY i.BillToCustomerID ORDER BY il.ExtendedPrice DESC) RowRank FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID INNER JOIN Sales.Customers c ON i.BillToCustomerID = c.CustomerID WHERE InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014';
This returns the RowRank for all of the customer records, so to get the largest transaction for each customer we just need to get the records where RowRank has a value of 1.

We could try the following query to just get RowRank = 1 as shown in the last line of the query in the below image. Sadly, it's not quite that simple. The window function can't be used in a WHERE clause as shown in the error message.

The query below is the final version. The first query is placed into a CTE so that the RowRank column can be placed in a WHERE clause in the main query and this will return the results we want.
-- second query with window function
WITH TopPurchase AS (
SELECT C.CustomerName, i.InvoiceDate, i.CustomerPurchaseOrderNumber,
RANK() OVER (PARTITION BY i.BillToCustomerID ORDER BY il.ExtendedPrice DESC) RowRank
FROM Sales.Invoices i
INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID
INNER JOIN Sales.Customers c ON i.BillToCustomerID = c.CustomerID
WHERE
InvoiceDate BETWEEN '1/1/2014' AND '3/31/2014'
)
SELECT CustomerName, InvoiceDate, CustomerPurchaseOrderNumber
FROM TopPurchase
WHERE RowRank = 1;
Performance Comparison Window Function versus No Window Function
The query with the window function is shorter by number of lines and performs better than the query without the window function that uses a larger subquery. If we look at the query without a window function and the query with a window function and include STATISTICS IO, TIME and the query execution plan this makes that very clear.
STATISTICS IO shows the same number of rows returned by each query and reduced reads and scans for both Invoices and InvoiceLines.
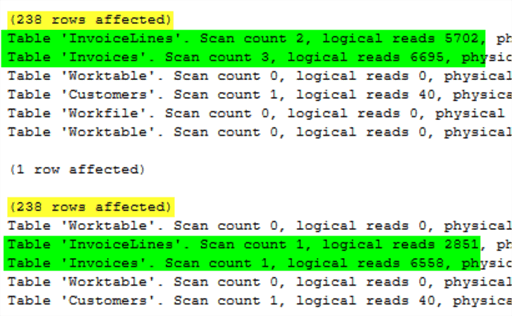
The output of STATISTICS TIME shows a similar story with the first query running over 4x as long as the second, that's significant optimization.

Finally, the query execution plan estimates that the first query costs slightly more than the second.

Consider using window functions in situations like this when looking for the biggest, earliest, or first row per customer, per day, etc. It tends to be much faster than alternative methods.
Rolling Aggregates in SQL Server
A rolling aggregate is a common KPI. These are commonly seen as "To-Date" or "Moving Average" values on reports where the current row value is the average of this row and the prior 30 or the sum of this row and all prior rows. Common examples would be a 30-day or 200-day moving average or Month-To-Date columns.
Query without a Window Function
Before the invention of windowed aggregates these were often accomplished via inline subqueries. The below query is ugly, but it accomplishes the task of calculating a 30 day moving average and a running total for year-to-date sales for 2013.
SELECT i.InvoiceDate, SUM(il.ExtendedPrice) TotalDollars , (SELECT SUM(il2.ExtendedPrice)/ COUNT(DISTINCT i2.InvoiceDate) FROM Sales.Invoices i2 INNER JOIN Sales.InvoiceLines il2 ON i2.InvoiceID = il2.InvoiceID WHERE i2.InvoiceDate BETWEEN DATEADD(dd, -30, i.InvoiceDate) AND i.InvoiceDate) [30BusinessDayMovingAverage] , (SELECT SUM(il3.ExtendedPrice) FROM Sales.Invoices i3 INNER JOIN Sales.InvoiceLines il3 ON i3.InvoiceID = il3.InvoiceID WHERE i3.InvoiceDate BETWEEN '1/1/2013' AND i.InvoiceDate) [2013YearToDate] FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID WHERE i.InvoiceDate BETWEEN '1/1/2013' AND '12/31/2013' GROUP BY i.InvoiceDate ORDER BY i.InvoiceDate;
Query with a Window Function
Accomplishing these same calculations with a windowed aggregate function is much easier.
These queries will start with the CTE below that creates one output row per business day with the revenue for that day.
WITH DollarsPerDay AS ( SELECT i.InvoiceDate, SUM(ExtendedPrice) TotalDollars FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID GROUP BY i.InvoiceDate)
We can combine the main query that reads the CTE and use 2 windowed aggregate functions to calculate the moving average and year-to-date amounts.
- The first averages the TotalDollars column for this row and the 29 preceding following rows when sorted by InvoiceDate to create a 30-day moving average. It is not an average of the entire data set – just those 30 rows per row!
- The second value creates a sum of this row and all previous rows. Only the last row in the data set will perform the aggregate function on every row in the data set.
WITH DollarsPerDay AS ( SELECT i.InvoiceDate, SUM(ExtendedPrice) TotalDollars FROM Sales.Invoices i INNER JOIN Sales.InvoiceLines il ON i.InvoiceID = il.InvoiceID GROUP BY i.InvoiceDate) SELECT InvoiceDate , TotalDollars , AVG(TotalDollars) OVER (ORDER BY InvoiceDate ROWS BETWEEN 29 PRECEDING AND CURRENT ROW) [30BusinessDayMovingAverage] , SUM(TotalDollars) OVER (ORDER BY InvoiceDate ROWS UNBOUNDED PRECEDING) [2013YearToDate] FROM DollarsPerDay WHERE InvoiceDate BETWEEN '1/1/2013' AND '12/31/2013' ORORDER BY InvoiceDate;
Performance Comparison Window Function versus No Window Function
Running both versions in immediate succession reveals some stark differences in performance. First, STATISTICS TIME shows an improvement of over 99% with the window function version.
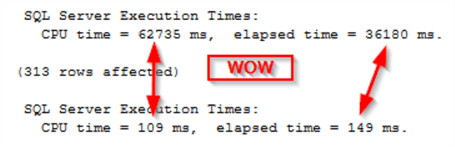
The output from STATISTICS IO agrees showing another 99%+ improvement using the window function version.

Finally, the query plan estimate agrees that the difference in methods is incredibly large and the window function version is much more efficient.

This author has seen enough of the slow non-window function type of query in plenty of TSQL code that it is probably worth reviewing any reports to see if they use the subquery-type of logic. This is especially true if the reports were written before the windowed aggregate code was available. The programmer that can take that 36 second report down to sub-second will surely look like a hero to the end users!
Next Steps
- Using STATISTICS IO and TIME to improve query runtime
- Using query plans to tune queries
- Using STATS IO to compare query performance
- A tutorial on window functions
- Much more detail about the power of Windowed Aggregates






About the author
 Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.
Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-02-16
