By: Manvendra Singh | Updated: 2021-03-22 | Comments (6) | Related: > Availability Groups
Problem
We had a requirement to setup HA & DR for SQL Server databases to increase availability and protect the data in case of any issue or disaster. We evaluated multiple options like dedicated servers having availability groups, clustering with log shipping, database mirroring, geo-clustering, etc. After brainstorming all possible designs, we came to a decision to go with availability groups between failover cluster instances to fulfill our requirement within our budget.
In this article, I will explain this approach, design and deployment process to configure cluster nodes to achieve high availability and availability groups on top of these cluster instances to achieve DR capabilities. Keep reading if you want to deploy a similar design for your databases.
Solution
II have given a brief detail about our requirement for SQL Server databases in order to fulfill HA & DR capabilities. SQL Server has many options to achieve HA & DR capabilities for databases like clustering, log shipping, replication, mirroring, backups, always on availability groups and some third-party solutions like metro clusters, etc.
Note: I would recommend that you first read about Always On Availability Groups and SQL Server Failover Clustering before reading this article to have a better understanding about the content I am going to discuss here.
We decided to go with availability groups as this is the latest and advanced technology SQL Server is offering for HA & DR. Availability groups have additional benefits to load balance read transactions and database maintenance activities on secondary replicas.
The initial design was to have an availability replica on standalone servers, two replicas in two datacenters. If one goes down another replica will take over from the same datacenter and replicas hosted in another datacenter will work as DR replicas and additional reserved VMs will be there to serve as HA for the DR replicas in case we need to make the DR servers the primary for the business.
We also discussed distributed availability groups to host 2 replicas in one datacenter and another two in another datacenter, but we ended up with having failover cluster instances for HA and availability groups on top of these failover cluster instances for DR.
Below are few scenarios for this design:
- If primary node Node1 from the primary datacenter goes down, then SQL Server will be shifted to Node2 within the same datacenter. It will be a cluster failover and not availability group failover.
- If something happens to both nodes (Node1 & Node2) in the primary datacenter or the whole datacenter goes down at primary site, then availability group failover can be initiated with manual intervention and SQL Server will be failed over to the secondary replica of availability group hosted in another data center on Node3 and Node4.
- Failover will occur at primary node (Node3) of the cluster instance in secondary datacenter and if something happens to this node then the secondary node (Node4) will take over the SQL Server failover cluster instance.
This article will cover details and deployment of this design only. Other designs will not be covered in this article.
Remember, all these configurations require careful planning of quorum voting at each stage. If you are bringing your DR server online as primary, ensure to change the quorum configuration for the right set of quorum voting to function with the available set of nodes.
Understanding the HA and DR Technical Design
I have already described in the above section that we had chosen to deploy Always On Availability Groups between two SQL Server failover cluster instances to fulfill our HA & DR requirements for SQL Server databases. The main reason for choosing this design is to have maximum availability with minimum cost.
Have a look at below points to see the benefits of this configuration:
- We need only 2x storage with FCIs whereas if we choose to go with dedicated replicas on each server then we would need 4x storage. So, we saved 50% on storage cost.
- The second reason to have this configuration was to have a HA solution for our DR server as well, so HA is available for both instances in both datacenters.
- Additionally, this design will work as Active-Active cluster, so you can use both SQL Server instances hosted in both datacenters to run different applications. Be careful in capacity planning if you are choosing this option to ensure all servers can sustain the load in case of a failover between datacenters.
One thing to note in this design is you will not get automatic failover for your availability groups because failover cluster instances do not support automatic failover for availability groups, but the cluster failover for SQL Server instances between their respective nodes will be done automatically. So, in short, our resiliency will work automatically to maximize availability.
Let’s discuss the design of our solution that is shown in the below image.
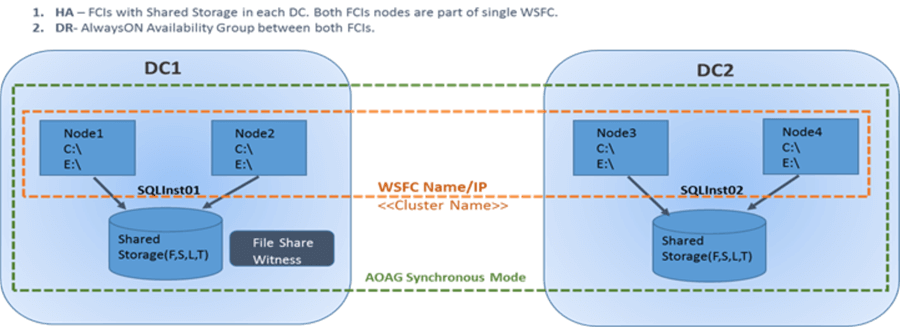
- We have two datacenters DC1 and DC2.
- Two nodes Node1 & Node2 are hosted in DC1 and another two nodes Node3 & Node4 are hosted in DC2.
- All 4 nodes (Node1, Node2, Node3, Node4) are part of one WSFC as its mandatory rule to have an availability group between them.
- We will have 2 SQL Server failover cluster instances on these nodes. One SQL Server FCI (default or named) will be hosted in DC1 between Node1 & Node2 as their primary and secondary nodes with their set of shared storage systems. Another SQL Server FCI (instance name must be different from SQL Server FCI hosted in DC1 because all nodes are part of one WSFC) will be hosted in DC2 between Node3 & Node4 as their primary and secondary nodes of the cluster with their own set of storage.
- Shared storage disks being used in DC1 between Node1 & Node2 will not be visible or accessible from DC2 nodes.
- Configure Always On Availability Group between both SQL Server instances hosted in each datacenter. You can choose synchronization mode as asynchronous if both datacenters are far apart, ours were 40 miles so we decided to keep them as synchronous mode.
- File Share witness will be used as quorum witness for this cluster configuration.
Quorum configuration is very important in such configurations and needs to be managed very carefully considering the number of voting nodes in the WSFC with different scenarios like how quorum should be in normal circumstances and how we could change it in case of DR scenarios. This configuration setting is being managed at WSFC level.
Assigning appropriate node votes plays an important role in the HA & DR design. By default, every node in a failover cluster has a vote, but you can change it as per your design. The total number of votes for the WSFC should be an odd number as per best practice. If there is an even number of voting nodes, then we consider adding a file share witness and then choose the Node and File Share Majority quorum model.
Configure Availability Group between Failover Cluster Instances – High Level Steps
Before going ahead, make sure to read and verify all pre-requisites are met for a successful configuration.
Pre-requisites
- All nodes must have the same version of the Windows Server operating system and software updates installed.
- All nodes must be part of same WSFC.
- Ensure failover is working fine between the respective nodes. Shared storage disks must be transferrable to their secondary nodes during failover. Run the cluster validation report for any issues.
- Choose optimal quorum configuration with proper votes assigned to nodes or quorum witnesses if needed based on your configuration.
- Ensure the account you are has sysadmin rights on these nodes.
- Recommendation is to have identical drive letters in both datacenters between their set of nodes for smooth failover for availability groups, although you can choose different drive letters as well, but ensure to use the MOVE command while restoring databases.
- Ensure possible owners of the both FCIs are set correctly, i.e., possible owners for instance hosted in primary datacenter should be Node1, Node2; and the possible owners for instance hosted in DR or secondary datacenter should be Node3, Node4.
Deployments
At a high level, deployment of this design is a 4 step process, but each step would have multiple low-level tasks to achieve completion:
- Add all 4 nodes to WSFC. Ensure to add shared storage disks between their respective nodes.
- Install SQL Server Cluster Instance in Primary Datacenter between nodes hosted in this datacenter with their set of shared storage (Node1 & Node2).
- Install SQL Server Cluster Instance in Secondary Datacenter between nodes hosted in this datacenter with their set of shared storage (Node3 & Node4).
- Configure Always On Availability Group between both installed SQL Server cluster instances in both datacenters.
I am not covering Windows clustering in this article as I assume you will get all four nodes added to the WSFC along with the shared storage disks between their respective nodes. These activities are generally taken care by the platform or operating system team. You can also do it, but don’t go against your company policy by taking on other teams responsibilities. Ask or engage other groups / resources to deliver the complete solution.
Once you will have first steps completed, the rest of all steps can be done by DBAs. Ensure to validate the cluster health before going ahead with second step.
Install SQL Server Cluster Instance between Node1 & Node2 in Primary Datacenter
- Use sysadmin account to perform this installation.
- Validate both nodes hosted in primary datacenter are configured with failover clustering having their own set of shared storage disks on which SQL Server databases will be hosted. Test failover is working fine between both nodes. Possible owners for shared storage disks must be Node1 & Node2.
- Go ahead and start SQL Server Cluster installation between these two nodes
Node1 & Node2 with their set of shared storage configuration that must be
accessed through these two nodes only.
- Install SQL Server cluster instance on Node1. Ensure to have unused SQL Server network name and IP before starting this installation.
- Once installation completes, add node Node2 to above installation through SQL Server installation window.
- Test the failover after installation on both nodes.
Install SQL Server Cluster Instance between Node3 & Node4 in Secondary Datacenter
This section is very much like the above under where we installed SQL Server cluster instance between Node1 & Node2 in the primary datacenter. You just need to perform exact steps in secondary datacenter for Node3 & Node4.
- Ensure you are using sysadmin account to perform this installation.
- Validate both nodes Node3 & Node4 hosted in secondary datacenter is configured with failover clustering having their own separate set of shared storage disks on which SQL Server databases will be hosted. Test failover should be working fine between both nodes.
- Possible owners for shared storage disks must be Node3 & Node4.
- Ensure you have appropriate quorum settings configured. Recommendation is to have odd number of voting in cluster. Also, DR nodes must not have any voting elements so assigned vote for Node3 & Node4 should be zero.
- Go ahead and start SQL Server Cluster installation between these two nodes
Node3 & Node4 with their set of shared storage configuration that must be
accessed through these two nodes only.
- You need to choose a different name for SQL Server cluster instance as compared to the instance running between Node1 & Node2. Ensure you have another set of unused SQL Server Network name and IP.
- Start installation of SQL Server cluster instance on Node3. Once installation completes, add node Node4 to this installation through SQL Server installation window.
- Test the failover after installation on both nodes as well.
Configure Always On Availability Group between Both Cluster Instances
Now, we will perform the last step that is configuring SQL Server Availability Group between the two installed SQL Server failover clusters.
- Enable Always On Availability Groups feature on both cluster instances hosted in both datacenters. Remember, you must restart the instance for this feature to be enabled.
- Create your database on the SQL Server cluster instance hosted in the primary datacenter or take a backup of your database from source machine and restore it to primary FCI. You can do this step post configuration of AOAG by just adding the restored database to the availability group as well. Migrate all objects that are needed for your application like jobs, logins and permissions, etc. As migration is not in scope of this article, I am not exploring the steps you need to follow for a migration.
- Take a backup of the database hosted on the primary replica in the primary datacenter between Node1 and Node2 (if you have performed any transactions on this database) and restore it to secondary replica FCI in NORECOVERY mode. Apply subsequent log backup restore as well in secondary FCI.
- Use SQL Server Network names of both cluster installations to configure AOAG.
- Get the Listener IP before creating the availability group. Once you have all details, start creating AOAG between both cluster instances. You can set the availability mode to asynchronous or synchronous, depending upon the design of your environment. Select manual failover for the availability groups.
- Once the AOAG is created, you can add your database(s) if you have not done it during the AOAG configuration.
Next Steps
Stay tuned for the next part of this article in which I will show you the steps with screenshots to deploy this design.
- Read more articles on SQL Server Clustering & SQL Server Availability group in attached links.
- You can also read more article on SQL Server Management Studio
- Explore more knowledge on SQL Server Database Administration Tips






About the author
 Manvendra Singh has over 5 years of experience with SQL Server and has focused on Database Mirroring, Replication, Log Shipping, etc.
Manvendra Singh has over 5 years of experience with SQL Server and has focused on Database Mirroring, Replication, Log Shipping, etc.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-03-22
