By: Fikrat Azizov | Updated: 2021-03-02 | Comments | Related: > Azure Synapse Analytics
Problem
Azure Synapse Analytics has introduced Spark support for data engineering needs. This support opens the possibility of processing real-time streaming data, using popular languages, like Python, Scala, SQL. There are multiple ways to process streaming data in Synapse. In this tip, I will show how real-time data can be ingested and processed, using the Spark Structured Streaming functionality in Azure Synapse Analytics. I will also compare this functionality to Spark Structured Streaming functionality in Databricks, wherever it is applicable.
Solution
What is the Spark Structured Streaming?
Spark Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine (see Structured Streaming Programming Guide for more details). It allows ingesting real-time data from various data sources, including the storage files, Azure Event Hubs, Azure IoT Hubs.
One of the advantages of Spark Structured Streaming is that it keeps track of changes in its data source, by maintaining logs. This feature makes Spark Streaming a very attractive choice because it allows building incremental ETL pipelines for various data warehousing scenarios, with minimal coding.
Spark Structured Streaming uses micro-batches under the hood, to handle continuous data streams. The duration of these batches is customizable - users can set either a fixed duration or choose a continuous option, which allows achieving as low as 1ms latency.
Another advantage of Spark Streaming is that it is based on the data frame APIs, previously available for static data sources. This allows applying traditional SQL transformations to the data frames.
Besides traditional file formats (like CSV, Parquet), the Spark Streaming allows reading/writing in Delta format, which brings additional benefits, like row versioning, ACID transactions (you can read more about Delta formats here).
I’ll assume here that you are already familiar with the basics of Azure Synapse Analytics and its Spark capabilities (see Azure Synapse Analytics Overview and Explore your Spark databases in Azure Synapse Analytics for more info).
Prepare the sample data
As mentioned above, Spark Streaming allows reading the storage files continuously as a stream. So, for the purpose of this demo, I will generate some data, save it in the storage and build a streaming pipeline to read that data, transform and write it into another storage location. I’ll use open-source New York Taxi data from Microsoft (see NYC Taxi & Limousine Commission - yellow taxi trip records for more details), which can be extracted using the Python libraries.
Let us open the Synapse Studio, navigate to the Develop tab and create a PySpark notebook:

Figure 1
Add the below code, to create the data from the library NycTlcGreen and display the schema of the data:
from pyspark.sql.functions import * from azureml.opendatasets import NycTlcGreen data = NycTlcGreen() data_df = data.to_spark_dataframe() data_df.printSchema()
Here is the query output:

Figure 2
This data has about 59 million rows, enough data to ensure that the streams, writing into another location would run for some time. Let us store this data in the blob storage in Delta format, using the below code:
deltaPath='/Synapse/Streaming/NYTaxiRaw'
data_df.write.format('delta').save(deltaPath)
Notice that we have used a delta format for the target data.
Build a streaming pipeline
I am interested in a few columns of this data, namely pick-up time, drop-off time, fare amount and tip amount columns. Let us run the following code, to read the data from the storage location in a streaming mode, calculate a trip duration in minutes and store the results in another storage folder:
deltaProcessedPath='/Synapse/Streaming/NYTaxiSilver' deltaCheckpointPath='/Synapse/Streaming/NYTaxiCheckpointSilver' dfProcStream=(spark.readStream.format('delta').load(deltaPath) .withColumn('TripDuration_Min',round((col('lpepDropoffDatetime').cast('long')-col('lpepPickupDatetime').cast('long'))/60)) .selectExpr('lpepPickupDatetime as PickupTime','lpepDropoffDatetime as DropoffTime','TripDuration_Min','fareAmount','tipAmount') .writeStream.format('delta') .option('mode','overwrite') .option('checkpointLocation',deltaCheckpointPath) .start(deltaProcessedPath))
A few observations regarding above code:
- The streaming read/write methods are like the static data methods.
- We need to specify a checkpoint location, where Spark stores the logs, to track the progress of the ingestion.
Although the data source is quite large, the execution of this code is very fast (4 seconds) and this is because Spark runs this command asynchronously - i.e. continue running this stream in the background. However, we can use the streaming handle (dfProcStream in this example) to verify the streaming status. You can run the following code to check if the stream is still active:
print(dfProcStream.isActive)
And this code will allow you to see at what stage the streaming is, at this point:
print(dfProcStream.status)
Here is the query output:
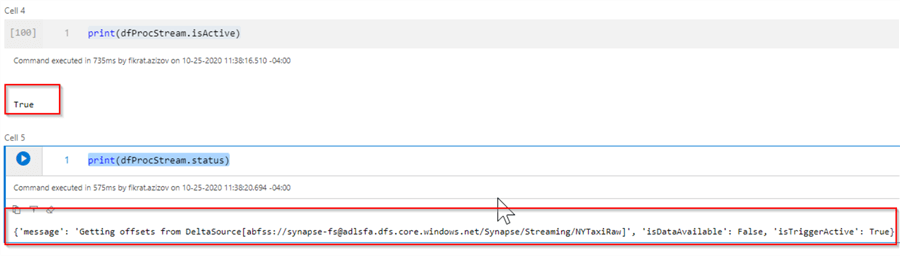
Figure 3
Here are some observations for those who are familiar with Databrick’s Structured Streaming:
- Unlike Databricks, the Synapse streaming data frames cannot be examined using a simple Display command.
- With Databricks, the progress of the running streams and their essential stats can be tracked using nice charts. Unfortunately, that is not the case for Synapse streaming at this point.
Meanwhile, we can create a Delta Lake table on top of the streaming data, using the below code:
%%sql CREATE TABLE NYTaxi USING DELTA LOCATION '/Synapse/Streaming/NYTaxiSilver/'
And now we can use SQL commands to examine the content of the target data:
%%sql select * from NYTaxi limit 100
Here is the query output:

Figure 4
Next Steps
- Read: Azure Synapse Analytics Overview
- Read: Analyze with Apache Spark
- Read: Structured Streaming Programming Guide
- Read: Delta Lake






About the author
 Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.
Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-03-02
