By: Koen Verbeeck | Updated: 2021-03-01 | Comments | Related: More > Integration Services Development
Problem
SQL Server Integration Services (SSIS) is a data integration tool part of the Microsoft Data Platform Business Intelligence stack. This ETL tool allows you to create efficient data pipelines to integrate data from various data sources. In this tip, I cover a couple of interesting and good-to-know features of this Microsoft SQL Server product.
Solution
For an introduction to the Microsoft SQL Server Integration Services product, please check out the SSIS 2016 tutorial. This tutorial walks through creating your first SSIS Package with the graphical tools, Control Flow (where you set precedence constraints, capture errors, etc.) and Data Flow transformations, Event Handlers, deploying, scheduling packages and more.
SSIS Data Flow Performance
The data flow is the task in SSIS responsible for extracting data from relational and non-relational sources (SQL Server database, Oracle, flat file connector, Excel, CSV, XML, OLE DB, etc.), transforming it and writing it to a destination. It is a basic workflow used for a data warehouse load then users can run SSAS, SSRS or Power BI based reports as well as data transmissions and data migrations performed by DBAs. Because the transformations are all done in-memory, SSIS can be really fast. Back in the day, SSIS even broke a world record for loading 1TB in 30 minutes.
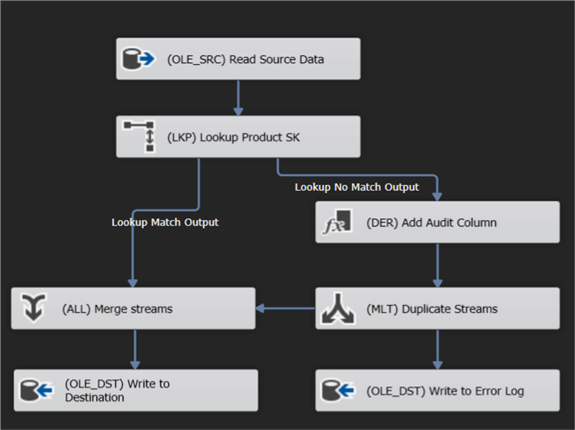
However, to get fast performance, there are some ground rules you need to consider:
Don't use any blocking and/or asynchronous components
Blocking components – like the aggregation or sort component – read all data in memory first before outputting any rows. If there's not enough RAM, SSIS starts spilling to disk and that's when things start to get really slow. Most blocking components are asynchronous, which means the size of the memory buffer is changed by the component. But there are also non-blocking asynchronous components as well, such as the UNION ALL. More info can be found in the tip Semi-blocking Transformations in SQL Server Integration Services SSIS.
Change the default buffer size
Data is "transported" through the data flow using memory buffers during package execution. The size of such a buffer is determined by the sum of the maximum size of each column. But there are limits, which are defined by the properties DefaultBufferMaxRows and DefaultBufferSize. The defaults for these properties are 10,000 rows and 10MB. Nowadays, servers tend to have much more RAM available then back in 2005, so you might want to change those settings to some bigger values. The tips Improve SSIS data flow buffer performance and Improving data flow performance with SSIS AutoAdjustBufferSize property go into more detail.

Sort or Group Data in Source Query
If you need to sort or group data, it's preferred to do this in the source query, if possible. A database engine is more suited to do this type of operations.
Do you need a data flow at all?
When you use the SSIS data flow, you're implementing an ETL pattern: Extract – Transform – Load. However, in the age of data engineering, ELT patterns are becoming more popular: Extract – Load – Transform. You can extract the data from the source and dump it in a SQL Server staging table for example in a data warehousing project. Then you use T-SQL to do the transformation with the data flow components. In doing so, you're using the compute power of the SQL Server to efficiently run the SQL statement.
Downside to Data Flow Tasks
There's one downside to the excellent performance of the SSIS data flow: metadata is fixed. If a column changes data type, or if columns are removed or added, the data flow crashes. It doesn't support schema drift.
.NET extensibility in SQL Server Integration Services
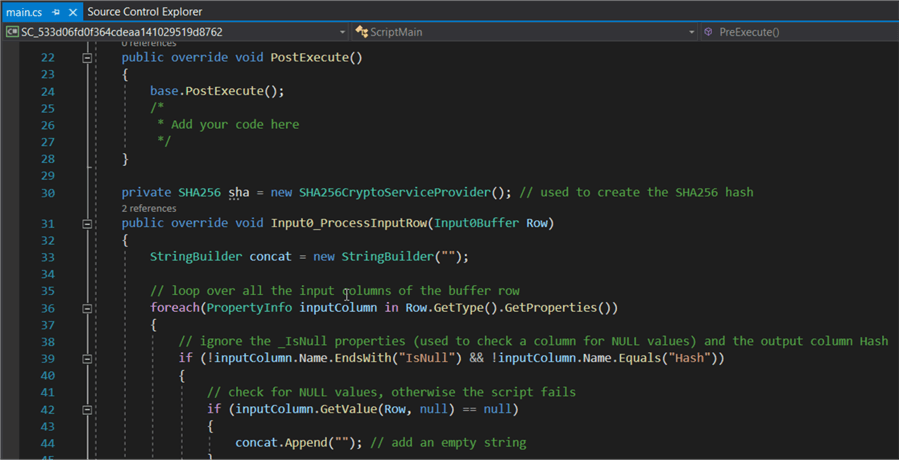
A source or destination not present in SSIS? You need some functionality not provided by the standard transformations, such as regular expressions? Not a problem! With the script task (control flow) or script component (data flow) you can extend SSIS with the full power of the .NET platform. You can write C# or VB code and implement any missing functionality in Visual Studio. You can import extra libraries if you need them. All you need to do is make sure the necessary DLLs are also present on the machine that will run your SSIS package.
The script task/component is an excellent way to extend your SSIS package, but if you want more reusability, you have two options:
- Create your own DLL and import it each time in the script task/component. This way you only need to write the code once.
- Or you can create your own SSIS task or transformations! It's more work, but you can specify a user interface so users don't have to dabble with .NET code.
For more information, check out the tip Getting started with the SSIS Script Task. The following book is also an excellent resource for .NET scripting in SSIS, and it contains many practical examples: Extending SSIS with .NET Scripting: A Toolkit for SQL Server Integration Services.
The tip Using hash values in SSIS to determine when to insert or update rows gives an example of how to add a hash column to the data using a script component.
Integration in Azure
SSIS was introduced in SQL Server 2005, as the replacement of DTS (Data Transformation Services). At the time, there was no Azure cloud which made SSIS an on-premises solution. When Azure got released, the only way to "run SSIS in the cloud" was installing SQL Server and SSIS on a virtual machine in Azure. Luckily, a few years back SSIS support was added in Azure Data Factory (ADF).
In ADF, you can configure an Azure-SSIS Integration Runtime, which is a cluster of virtual machines managed by ADF. You also link an SSIS catalog (either installed in Azure SQL DB or Azure SQL Managed Instance) to this IR. With this solution, you can lift-and-shift existing SSIS project to the SSIS catalog in Azure. When you run a package, it will be executed on the IR cluster.
There are a couple of tips to help you get started with the Azure-SSIS IR:
- Configure an Azure SQL Server Integration Services Integration Runtime
- Customized Setup for the Azure-SSIS Integration Runtime
- Executing Integration Services Packages in the Azure-SSIS Integration Runtime
- SSIS Catalog Maintenance in the Azure Cloud
The following blog post by Microsoft gives a good overview of the journey made to get SSIS in Azure: Blast to The Future: Accelerating Legacy SSIS Migrations into Azure Data Factory.

Parameters and Expressions in SQL Server Integration Services
With expressions you can dynamically change the behavior of an SSIS package during runtime. Typically, expressions contain variables or parameters. A typical example: a ForEach loop iterates over a folder with flat files. The filename of the current flat file is stored in a variable. Using an expression, the flat file connection manager is dynamically updated to the current file. This pattern is explained in the tip Loop through Flat Files in SQL Server Integration Services.
In SSIS 2005 and SSIS 2008, the only way to change behavior dynamically was using variables. In SSIS 2012, parameters were introduced; package and project parameters. At first glance, parameters and variables are very similar. There's one difference: variables can change value during runtime, while parameters get their value at the start of the execution and it doesn't change. You can look at parameters as interface of the SSIS package.
The SSIS Catalog
With the introduction of the project deployment model in SSIS 2012, the SSIS catalog came into the picture as a centralized database where you can store, manage and execute your SSIS packages as opposed to the file system. Some of the advantages:
- Logging is now been take care of the SSIS catalog. No need to roll your own logging framework or use the package log providers (which log everything to one single table). You can also create your own custom logging level to control the granularity of the logging.
- An SSIS project is now an object of its own in the catalog. Previous versions of the project are stored in the catalog. If something goes wrong during a deployment, you can just roll back to a previous version.
- The catalog comes with built-in reporting. You can find more info in the tip Reporting with the SQL Server Integration Services Catalog.
- You can create multiple "environments". An environment is a collection of variables. When you execute a package, you can choose the environment. All of the variable values are then applied to the package. This means you can easily switch the behavior of a package.

The tip SQL Server Integration Services Catalog Best Practices gives you some pointers in how to manage the SSIS catalog, especially on how to make sure its size doesn't grow out of control.
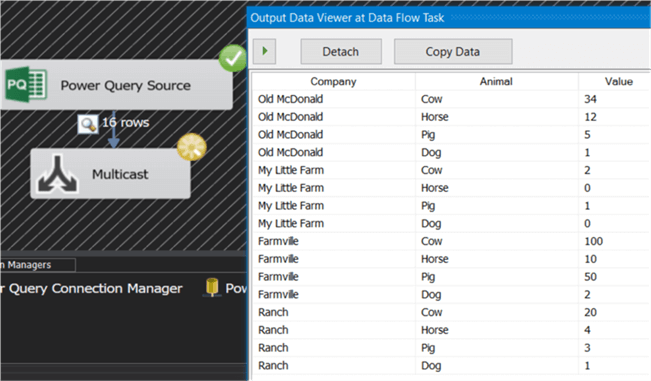
Power Query Source
To conclude, one of the latest additions to SSIS: the Power Query source. It's still a bit rough around the edges, but this source component is very promising; it allows you to execute an M-query (the language behind Power Query, also known as the Power Query formula language). The advantage is that you can do some transformations effortlessly in Power Query, such as unpivoting data, which are harder to do in SSIS. Hopefully this source component is improved over time.
In the tip SQL Server Integration Services Power Query Source you can find an introduction and some examples.
Conclusion
This tip only covers a subset of the awesome features Microsoft SQL Server Integration Services has to offer; it is by no means an exhaustive list. What are your favorite features of SSIS? Please let us know in the comments!
Next Steps
- To get started with SSIS, check out the tutorial or this webinar.
- You can find more SSIS tips in this overview.
- Learn more about the Top Features of SQL Server Data Tools (SSDT).






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-03-01
