By: Ron L'Esteve | Updated: 2021-05-19 | Comments | Related: More > Snowflake
Problem
Many large organizations with big data workloads that are interested in migrating their infrastructure and data platform to the cloud are considering Snowflake data warehouse as a strong competitor to Azure Synapse Analytics for a number of reasons including its maturity and service offerings as a big data warehouse solution. While Snowflake has numerous advantages as a modern big data warehouse, since it is not a service offering within the Azure Data Platform, how can Azure Data Services such as Azure Data Lake Storage Gen2, Azure Databricks, Azure Data Factory and more read and write data to Snowflake?
Solution
There are quite a few Azure Data Services such as Databricks, Data Factory, Data Lake, SQL Database and more that may need to connect to Snowflake as part of a modern data platform ETL and Analytics solution.
In this article, we will explore a few scenarios for reading and writing to Snowflake data warehouse including 1) connecting to Snowflake from Databricks and then reading a sample table from the included TPC-DS Snowflake dataset and 2) then extracting a sample TPC-DS dataset into an Azure Data Lake Gen2 Storage Account as parquet format, again using Databricks. Next, we will 3) explore how to write data back to Snowflake using Databricks, and finally, 4) we will explore how to connect, read, and write to Snowflake from Azure Data Factory V2's new Snowflake connector.
Please note that this article is meant to demonstrate the capabilities of connecting to Snowflake, along with reading and writing to Snowflake rather than performance benchmarking the data load speeds using multiple connection options.
Connecting to Snowflake from Databricks
Let's begin the process of connecting to Snowflake from Databricks by creating a new Databricks notebook containing an active cluster and then either mounting or connecting to an Azure Data Lake Storage Gen2 account using an access key by running the following script.
spark.conf.set( "fs.azure.account.key.rl001adls2.dfs.core.windows.net", "ENTER-KEY" )

Once a connecting to an existing ADLS2 account has been established, we can create a dataframe containing the Snowflake connection options by using the following script. Note that Snowflake offers a free trial account with $400 credits which would be sufficient for testing these scenarios in a cost-free manner.
# snowflake connection options
options = {
"sfUrl": "snow.east-us-2.azure.snowflakecomputing.com",
"sfUser": "accountadmin",
"sfPassword": "Admin123!",
"sfDatabase": "snowflake_sample_data",
"sfSchema": "tpcds_sf10tcl",
"sfWarehouse": "COMPUTE_WH"
}

Reading Snowflake from Databricks
Databricks and Snowflake have partnered to create a connector for customers of both Databricks and Snowflake, and to prevent them from having to import and load a number of additional libraries into a cluster. This connector is specified in the .format(“snowflake”) section of the code below, which takes the connection properties of Snowflake and then runs the query specified in the code on the sample datasets included in Snowflake.
For more information on setting configuration options for the Snowflake connector, see the Snowflake connection documentation which is available here.
df = spark.read .format("snowflake") .options(**options) .option("query", """select i_category, i_brand, cc_name, d_year, d_moy,
sum(cs_sales_price) sum_sales,
avg(sum(cs_sales_price)) over
(partition by i_category, i_brand,
cc_name, d_year)
avg_monthly_sales,
rank() over
(partition by i_category, i_brand,
cc_name
order by d_year, d_moy) rn
from snowflake_sample_data.tpcds_sf10tcl.item, snowflake_sample_data.tpcds_sf10tcl.catalog_sales, snowflake_sample_data.tpcds_sf10tcl.date_dim, snowflake_sample_data.tpcds_sf10tcl.call_center
where cs_item_sk = i_item_sk and
cs_sold_date_sk = d_date_sk and
cc_call_center_sk= cs_call_center_sk and
(
d_year = 1999 or
( d_year = 1999-1 and d_moy =12) or
( d_year = 1999+1 and d_moy =1)
)
group by i_category, i_brand,
cc_name , d_year, d_moy
limit 100""") .load()
df.show()


From the displayed dataset above, we can see that the complex query read and returned data directly from the Snowflake datasets.
Next, let's try to read another dataset from Snowflake which contains less joins so that we can then use this dataset to export into ADLS gen2 as parquet format.
df = spark.read .format("snowflake") .options(**options) .option("query", "select * from snowflake_sample_data.tpcds_sf10tcl.item") .load()
df.show()

As expected, the results above indicate that querying Snowflake was successful from Databricks.
Writing Snowflake Data to Azure Data Lake Storage Gen2
Next, we can take the dataframe(df) which we created in the step above when we ran a query against the TPC-DS dataset in Snowflake and then write that dataset to ADLS2 as parquet format. Additionally, we can add partitions and in this case, let's partition by Category ID.
(
df
.write
.format("parquet")
.partitionBy("I_CATEGORY_ID")
.save("abfss://[email protected]/raw/tpc-ds/item")
)
spark.read.parquet("abfss://[email protected]/raw/tpc-ds/item").show()

The results above indicate that the data was written from Snowflake to ADLS2, as expected.
At this point, we could go ahead and create a delta table using the ADLS2 location of the parquet files, using the following code.
(
df
.write
.format("delta")
.partitionBy("I_CATEGORY_ID")
.save("abfss://[email protected]/raw/tpc-ds/delta/item")
)
spark.read.parquet("abfss://[email protected]/raw/tpc-ds/delta/item").show()

Sure enough, from the displayed data above, we can confirm that the delta table has been successfully created.
Next, we can create a Hive / External table within Databricks using the delta location.
spark.sql("CREATE TABLE item USING DELTA LOCATION 'abfss://[email protected]/raw/tpc-ds/delta/item/'")

After running a count of the newly created item table, we can see that the table contains 40200 rows that were extracted from Snowflake. The Snowflake connector took approximately 44 seconds to read the records and write them to ADLS2 as partitioned parquet files.
%sql SELECT COUNT(*) FROM item

Writing to Snowflake from Databricks
Now that we have tested how to read from Snowflake and write data into ADLS2, we can move on with testing how to write data back into Snowflake from Databricks with the snowflake connector.
So once again, we can create a new dataframe with alternate options which reference a difference database and schema.
# snowflake connection options
options2 = {
"sfUrl": "snowid.east-us-2.azure.snowflakecomputing.com",
"sfUser": "accountadmin",
"sfPassword": "Admin123!",
"sfDatabase": "DEMO_DB",
"sfSchema": "PUBLIC",
"sfWarehouse": "COMPUTE_WH"
}

Next, let's write 5 numbers to a new Snowflake table called TEST_DEMO using the dbtable option in Databricks.
spark.range(5).write .format("snowflake") .options(**options2) .option("dbtable", "TEST_DEMO") .save()

After successfully running the code above, let's try to query the newly created table to verify that it contains data.
df = spark.read .format("snowflake") .options(**options2) .option("query", "select * from demo_db.public.test_demo") .load()
df.show()

As expected, from the results above, we can verify that both a new table was created and the specified data was written to the table in Snowflake from Databricks using the Snowflake connector. This code can also be altered to write either parquet, delta, or hive/external table from ADLS2 and Databricks into Snowflake.
We can further verify the contents of the new table by running the following query from Snowflake.

Connecting to Snowflake from Azure Data Factory V2
So far, we have explored how to connect, read and write to Snowflake by using Azure Databricks.
Azure Data Factory V2 also now offers a Snowflake Connector through its ADF UI. This Snowflake connector can be found by creating a new dataset in ADF and then searching for Snowflake.

After adding the same Snowflake connection credentials to the ADF linked service connection details UI, we can test the connection to ensure it is successful. This demonstrated that we can successfully connect to Snowflake from ADF.

Reading & Writing to Snowflake from Azure Data Factory
Once a connection to Snowflake has been established from Azure Data Factory, there are numerous options using Snowflake databases and tables as wither sources or sinks using ADF's copy activity. From the image below, we can easily the sample TPCH data from Snowflake tables.
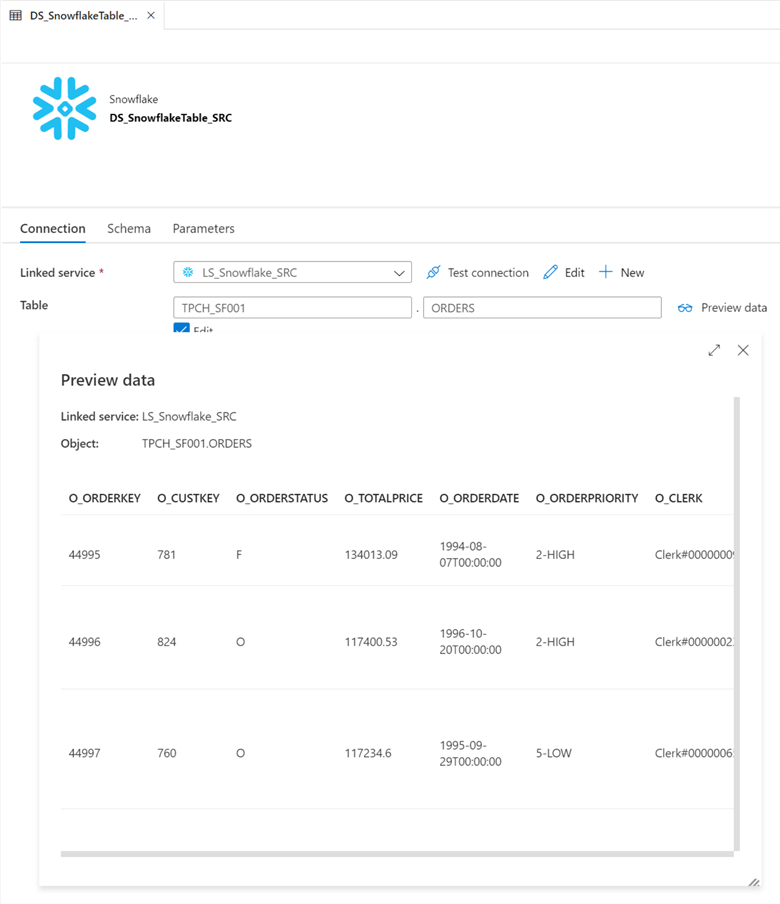
In addition to the regular copy activity in ADF, Mapping Data Flows, which utilizes spark compute much like Databricks can also connect to the Snowflake linked service in ADF. It was be used as both a source and a sink.
In addition to the benefit of leveraging Spark compute within ADF Mapping Data flows, there are other neat options that can be used for reading and writing to Snowflake such as Schema Drift and optimization options through a variety of different partitioning types and options.


Additionally, with ADF Mapping dataflows, there are also options for handling duplicates prior to loading into or out of Snowflake.
Despite the fact that these are all great options, I have not tested the performance of this new Snowflake connector from ADF, but have read the following article, ADF Snowflake Connector: A Bit Underbaked, which talks about some of the tests performed on this connector and why it should have stayed in the oven a little longer. Nevertheless, I think that once some of these features are improved with future version releases, it may be as performant as the Databricks Snowflake connector, with the added benefits of ADF Mapping Data Flows' robust GUI.

Next Steps
- For more information on connecting to Azure SQL Server Sources and Destinations from Databricks, read SQL databases Using JDBC
- For alternative methods of loading data into Snowflake using Snow Pipe, read Introduction to Snow Pipe.
- For more information on getting started with Snowflake, read Snowflake's Getting Started documentation.
- Also read this detailed Snowflake Tutorial from MSSQLTips.com.
- For alternative connectors to Snowflake from Azure Data Factory, read Snowflake Connector for ADF.






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-05-19
