By: Eric Blinn | Updated: 2021-06-10 | Comments | Related: > Database Design
Problem
SQL Server is a relational database management system or RDBMS. I am new to SQL Server and I need to know more about what a relational database is so that I can better understand my role, database software functionality and the best practices for data management.
Solution
This tip will explain what a relational database is and how it functions. The goal is to help new SQL Server users understand how relational databases are designed to work. This should help explain why there are so many tables, how those tables likely came to be, and how they all work together.
Included at the bottom will be a short glossary of terms that are commonly used in the industry to help those newcomers from being lost. Each will be covered during the tip, but this "cheat sheet" may be useful to refer back to.
While the focus of this tip will be on SQL Server, most -- if not all -- of the information pertained in this tip is platform agnostic and would be equally as accurate for other DBMS including Oracle, IBM DB2, PostgreSQL or MySQL including cloud relational databases from Amazon, Microsoft, IBM, Google, etc.
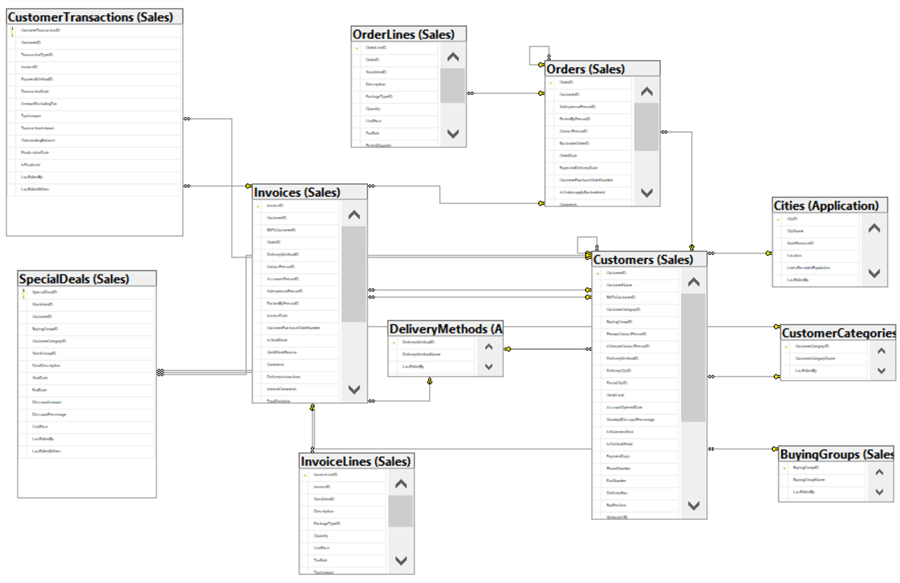
All of the demos in this tip will use WideWorldImporters, a sample SQL database, which can be downloaded for free from Github.
Relational Database Model
The goal of any well-designed relational database is to provide efficient and secure mechanism to store data. This section will cover how data structures for a relational database are logically designed. There won't be any code in this section as it is strictly a logical design process.
The first step is to think about the information that needs to be stored as a group of entities. An entity is something that will be stored in the database. It might be an order, a customer, or an item for sale.
These entities have attributes. An attribute is something that describes an entity. An attribute of an order might be the order number or the date it was entered. An attribute for a customer would be their name, date of birth, or email address. For an item for sale the attributes would surely include a description, unit price, and perhaps a shipping weight.
Finally, these entities have relationships meaning that they are connected to each other i.e. relational data. These relationships are defined during the design process. In this example one would expect an order to belong to a customer. Surely there can't be an order without a customer making that purchase! This means that there is a relationship between the order entity and the customer entity. There would also be a relationship between the order entity and the item for sale entity as there cannot be an order without something being ordered. There would not be a relationship between customer entity and item for sale entity.
In this image below the entities described above are shown logically in the blue boxes. The attributes are highlighted in yellow. The red lines indicate the relationships. This is a very rudimentary Entity-Relationship Diagram. Look lower for a much larger Entity-Relationship Diagram for a part of WideWorldImporters.

When the information that needs to be stored is as simple as this, the design process can be pretty quick and easy. Sadly, this is rarely the case in the real world where relational databases can have 10s or 100s of entities and many thousands of attributes. This necessitates some rules to help define the design process. These rules are commonly referred to as normalization.
TThis tip isn't going to cover normalization, but there are several other tips available on this site that cover the subject in great detail.
- Understanding First Normal Form from E. F. Codd
- Data Modeling: Understanding First Normal Form in SQL Server
- SQL Server Database Design with a One To One Relationship
- SQL Server Data Modeling Tutorial
- How to remodel a poorly designed relational database
- Using SQL Server Management Studio to create Entity-Relationship Diagrams
RRelational Databases from Conceptual to Practice
Entities and Attributes
TThere are many, many rules when normalizing a relational database design and implementing it through a RDMS, but this tip will offer a very basic introduction. When done deciding which entities (i.e. database tables) will need to exist, these entities will become different tables which are responsible for logical data storage. The attributes will be the columns of the tables with various data types - INT, VARCHAR, DATETIME, etc. Every time a new instance of the entity is created a new row (or tuple) is created in the corresponding table. Continuing the prior example there would be 3 tables with several columns each. Every time a new customer signed up to the website there would be one new row in the customer table. Every time something was ordered from the web store, a new row would be placed in the orders table.
One sign of a good design is that there isn't a common scenario where a new column would need to be added to the database. Whenever this author encounters a table where a new column needs to be added every month called "December2021Sales" or any similar situation, this immediately points to relational database that was poorly designed. Reading the above links about normalization will help show ways to resolve such design issues.
Relationships
That covers the entities and attributes, but what about relationships? In order for the entities to be related to each other there first needs to be a way to uniquely identify each instance of an entity. This is accomplished by defining a column (or less commonly a group of columns) as the Primary Key of the table. The primary key column must be unique for every instance of the entity -- meaning no 2 rows in the table can have the same value for the primary key. In a properly designed relational database EVERY table will have a primary key defined.
In the above example the customer entity might choose the EmailAddress column as the primary key since no 2 customers will share an email address. The RDBMS will enforce this by throwing an error if someone attempts to sign up for the website for a second time using an email address that is already in use. It would also throw an error if an existing customer attempted to update their email address to one that is already associated to another customer.
The relationship can now be defined using a Foreign Key. A foreign key is when the primary key column (or columns) for one table is stored again in another table. In this example the customer table is related to the order table. The relationship would be defined by adding a new column to the order table and storing one customer table primary key value in it for each order. The RDBMS would not allow an order to be entered without an email address and, specifically, without an email address that is already in the customer table. Now, when viewing the data in the order table it can be determined EXACTLY which customer placed every order by using the EmailAddress stored in the foreign key column to retrieve exactly 1 row in the customer table. While the primary key value is unique in the customer table it will (hopefully) not be unique in the order table as one customer may place many orders and see their email address on many rows in the order table.
These primary/foreign key relationships often show up in JOINs when writing SQL code within a relational database.
How does all of this lead to efficiency?
A common complaint from someone new to relational databases is that it would be easier if we just stored the customer information right there in the order table rather than have to perform a join to look it up. In our example with only 3 customer attributes that might make some sense, but in practice one can expect many more attributes. Imagine a scenario where there are 100 customer attributes. The order table would become huge and with many customers making many orders the data would be incredibly repetitive with the same names and addresses being stored again and again. Storing that customer information once per customer and sharing it across many orders via a relationship is far more efficient.
Consider a scenario where the customer changes some information about themselves. In a well-designed database that name only needs to be changed once – in the customer table – and all of the orders related to that customer will have essentially been updated as well. If the customer data is not stored in a separate customer table and instead stored on every order, then a name update would need to be applied to every order the customer ever placed and would be a much larger operation.
How does all of this increase security?
By separating duties and enforcing relationships a RDBMS can bring about significant security to a computer system.
IImagine a system designed to write checks to pay vendor invoices. There would likely be a table called "vendor" with a relationship to another table called APChecks based on the primary key of the vendor table. With a proper separation of duties there would be one group allowed to create new vendor rows and a separate group allowed to create rows in the APChecks table to actually generate a payment. Now, no one from the check group can create a new row in the APChecks table without choosing an existing vendor to which to pay the check. They can't make a check out to cash or to themself. While the vendor group could make a phony vendor, they couldn't also generate the check.
If that AP system was all one table with no relationships being enforced it would be much easier to make a check out to whomever.
SQL Programming Language
The SQL (Structured Query Language) Programming Language is defined by the American National Standards Institute (ANSI) which is part of the International Organization for Standards (ISO). Each of the major DBMS vendors (Microsoft, Oracle, IBM, PostgreSQL, etc.) have their own extensions for the SQL language. In SQL Server it is T-SQL (Transact-SQL), Oracle has PL/SQL (Procedure Language Extension to Structured Query Language), etc. which all have some similarities and differences with the SQL syntax.
At a high level, the SQL programming language has two major sets of functionality. First, is to create objects such as tables, stored procedures, views, functions,,, etc. These types of commands are called Data Definition Language (DDL) and consist of CREATE, ALTER or DROP commands. The second set of functionality for the SQL programming language also includes commands to SELECT, INSERT, UPDATE and DELETE data within tables. This can be performed within these SQL statements: stored procedures, triggers, T-SQL scripts, functions, views, SQL queries, etc.
Glossary of terms
- RDBMS – Relational Database Management System. A RDBMS is software that implements a relational database by efficiently storing data and enforcing relationships. Examples would be Microsoft SQL Server, Microsoft Access, Oracle, or MySQL.
- Entity – Something that needs to be stored in a relational database. This could be orders, people, inventory, payables, etc. These generally become tables in a RDBMS. These are usually tables in a RDBMS.
- Attribute – Something that defines an entity. These generally become columns in a RDBMS.
- Relationship – How 2 entities (or tables) connect to each other. A relationship commonly becomes a JOIN when writing SQL code.
- Normalization – The process by which entities, attributes, and relationships are defined in an efficient manner.
- Primary Key – The column (or group of columns) that uniquely identify a row in a table.
- Foreign Key – When the primary key column (or columns) of one table is stored again in another table to initiate a relationship.
Next Steps
- Check out these resources:
- Beyond relational database management systems, keep in mind there are also
other types of databases:
- Graph Databases
- NoSQL Databases \ Non-Relational Databases
- Open Source Databases
- Relational Database Comparison between SQL Server, Oracle databases and PostgreSQL
- Compare SQL Server, MySQL and PostgreSQL Features
- MySQL to SQL Server Conversion Tutorial
- Code Comparison for SQL Server vs. MariaDB
- Compare MariaDB vs SQL Server SQL Commands
- Compare SQL Server and MariaDB Operational Technology
- We will look at covering these in future tutorials.






About the author
 Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.
Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-06-10
