By: Andrea Gnemmi | Updated: 2021-07-29 | Comments (2) | Related: > SQL Server vs Oracle vs PostgreSQL Comparison
Problem
One of the most useful, and sometimes misused, feature in RDBMS are SQL views. In this tutorial we will take a look at how to create and use views in SQL Server, Oracle and PostgreSQL.
Solution
Views are an important part of an RDBMS. They are very convenient if used correctly, but with some caveats and differences between SQL Server, Oracle and PostgreSQL. We will explore the different possibilities that we have and see how to avoid potential performance problems.
We will not talk about system views in this tip as it is a much bigger topic. Each RDBMS has special system views with a lot of useful info about statistics, waits, I/O, memory and all sorts of data from the data dictionary. All these are readable and sometimes require elevated privileges, but they can be a great help to address performance problems and to understand the architecture of the database system.
SQL Views Overview
First of all, let’s see the definition of a database view: "A view is a subset of a database that is generated from a query and stored as a permanent object. Although the definition of a view is permanent, the data contained therein is dynamic depending on the point in time at which the view is accessed."
So, a view is like a virtual table in which we have a query extracting data from one or more joined tables and with the possibility including aggregations. Since the view definition is just a SELECT statement from base tables and not another set of data, it does not occupy much storage space except for the view definition. The exception to this is materialized views which I will explain more on this subject further down.
Now let’s create some examples, as always we will use the Github freely downloadable sample database Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for data structure and all the inserts for the data.
SQL Server Views
We will start with SQL Server. A basic view is quite easy to build, using the CREATE VIEW statement for a single table or multiple tables in a SQL database. Suppose we always query together album, artist, track and genre to obtain all the songs in each album as well as the artist and genre. So, we decide to create a view in order to have this subset of data available for queries. Note the OR ALTER option that gives us the possibility to alter a view if already existing or create if it does not exist, this T-SQL syntax was introduced in SQL Server 2016.
CREATE OR ALTER view view_Album as SELECT TITLE, track.name as song_title, Artist.name as Artist, composer, genre.Name as Genre FROM album INNER JOIN Track on Album.AlbumId=Track.AlbumId INNER JOIN Artist on Album.ArtistId=Artist.ArtistId INNER JOIN Genre on Track.GenreId=Genre.GenreId

At this point we can easily query the view as follows with this SQL statement and see the result set in the image below:
SELECT * FROM dbo.view_Album WHERE Genre='Rock' AND composer LIKE '%glover%'

Oracle View
Let’s try to do create the same view in Oracle now. Please notice the syntax CREATE OR REPLACE. This enables us to create an object or replace it if exists.
CREATE OR REPLACE view chinook.view_Album as SELECT TITLE, track.name as song_title, Artist.name as Artist, composer, genre.Name as Genre FROM chinook.album INNER JOIN chinook.Track on Album.AlbumId=Track.AlbumId INNER JOIN chinook.Artist on Album.ArtistId=Artist.ArtistId INNER JOIN chinook.Genre on Track.GenreId=Genre.GenreId;

Now we can run this SQL query:
SELECT * FROM chinook.view_Album WHERE Genre='Rock' AND composer LIKE '%glover%';

We have a different result from Oracle since it is a case sensitive environment. Thus the LIKE '%glover%' only returns data where the G in glover is lower case and not an upper case G.
PostgreSQL View
Now let's look at PostgreSQL:
CREATE OR REPLACE view view_Album as SELECT "Title", "Track"."Name" as song_title, "Artist"."Name" as Artist, "Composer", "Genre"."Name" as Genre FROM "Album" INNER JOIN "Track" on "Album"."AlbumId"="Track"."AlbumId" INNER JOIN "Artist" on "Album"."ArtistId"="Artist"."ArtistId" INNER JOIN "Genre" on "Track"."GenreId"="Genre"."GenreId";

We see again the same syntax with the OR REPLACE as in Oracle and we get the same result as Oracle:
SELECT * FROM view_Album WHERE genre='Rock' AND "Composer" LIKE '%glover%';

So far this has been a simple and useful concept, where each RDMBS works basically the same.
Performance Issues
When using a view, there is a potential for performance issue. With our simple example above, we do not have problems, but imagine having multiple left joins, group by or even order by in the view. That will impact performances of the view and it should be avoided if possible, especially with big tables and views queried frequently. To improve performance, it should be optimized like any other query, with proper indexing on the tables and keeping it as simple as possible. Another issue you can run into is when you use views in views. It can be done, but can create performance issues and it is much harder to optimize.
Materialized or Indexed Views
This is an approach to address some of the performance problems with views and a way to speed up queries when used frequently.
SQL Server Indexed View
So, let’s create an example in SQL Server which is called an indexed view. Creating a clustered index on a view is a way to greatly improve view performance in SQL Server because the index is stored in the database in the same way a clustered index on a table is stored. This also means it stores the data as well which takes up additional storage space.
However, in order to create an index on a view, it needs to schema bound which is achieved by creating the view using WITH SCHEMADINDING. There is another catch: the first index created on the view must be a unique index.
So, let’s create a new view in order to demonstrate these features:
CREATE VIEW view_Invoice_Genre with schemabinding AS SELECT Invoice.InvoiceId, InvoiceDate, SUM(InvoiceLine.UnitPrice*Quantity) AS Total_by_Genre, Genre.Name AS Genre, COUNT_BIG(*) AS Id_index FROM dbo.Invoice INNER JOIN dbo.InvoiceLine ON InvoiceLine.InvoiceId = Invoice.InvoiceId INNER JOIN dbo.Track ON Track.TrackId = InvoiceLine.TrackId INNER JOIN dbo.Genre ON Genre.GenreId = Track.GenreId GROUP BY Invoice.InvoiceId,InvoiceDate, Genre.Name

Notice that in order for the schemabinding option to work, all tables must be referenced using two part naming notation (schema.tablename). There is another little caveat here, in order to create an index on a view containing a GROUP BY we must add a COUNT_BIG(*) as a way for the optimizer to recognize rows.
Finally, let’s create a unique clustered index on the view:
CREATE UNIQUE CLUSTERED INDEX idx_view_invoice_genre ON view_Invoice_Genre (InvoiceId,InvoiceDate,Genre)

Now we have our indexed view and we can easily query it as follows:
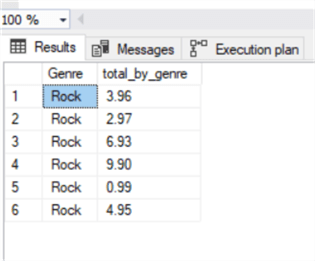
SELECT Genre, total_by_genre FROM view_Invoice_Genre WHERE invoicedate>='01/01/2013' AND invoicedate<'04/01/2013' AND genre='rock'
I’ve included the actual execution plan, so we can take a look at the query plan made by the optimizer:

From the query plan above, we have a surprise as it seems that even if we have an index covering the exact filters used in the WHERE clause, this has not been taken in account the query plan. This is because I’m not using the Enterprise edition of SQL Server, so the indexed view in all other editions of SQL Server is not automatically taken in account by the optimizer. In order to do that we must add the option WITH (NOEXPAND) that actually tells the optimizer to not expand the view:
SELECT Genre, total_by_genre FROM view_Invoice_Genre WITH (NOEXPAND) WHERE invoicedate>='01/01/2013' AND invoicedate<'04/01/2013' AND genre='rock'
In this way the optimizer actually uses the clustered index on the view, greatly improving the performances of the query. We can see the improved query plan below.

And here are the results:
Oracle Materialized View
In Oracle the concept is quite different as we use Materialized Views which are more like a data warehouse table that is periodically refreshed with new data, based in this case on the view query. This is not like SQL Server where the materialized part is the clustered index.
Let’s create the same view, you can see here that the OR REPLACE part is not available for materialized views:
CREATE materialized VIEW chinook.view_Invoice_Genre as SELECT Invoice.InvoiceId, InvoiceDate,SUM(InvoiceLine.UnitPrice*Quantity) AS Total_by_Genre, Genre.Name AS Genre FROM chinook.Invoice INNER JOIN chinook.InvoiceLine ON InvoiceLine.InvoiceId = Invoice.InvoiceId INNER JOIN chinook.Track ON Track.TrackId = InvoiceLine.TrackId INNER JOIN chinook.Genre ON Genre.GenreId = Track.GenreId GROUP BY Invoice.InvoiceId, InvoiceDate, Genre.Name;

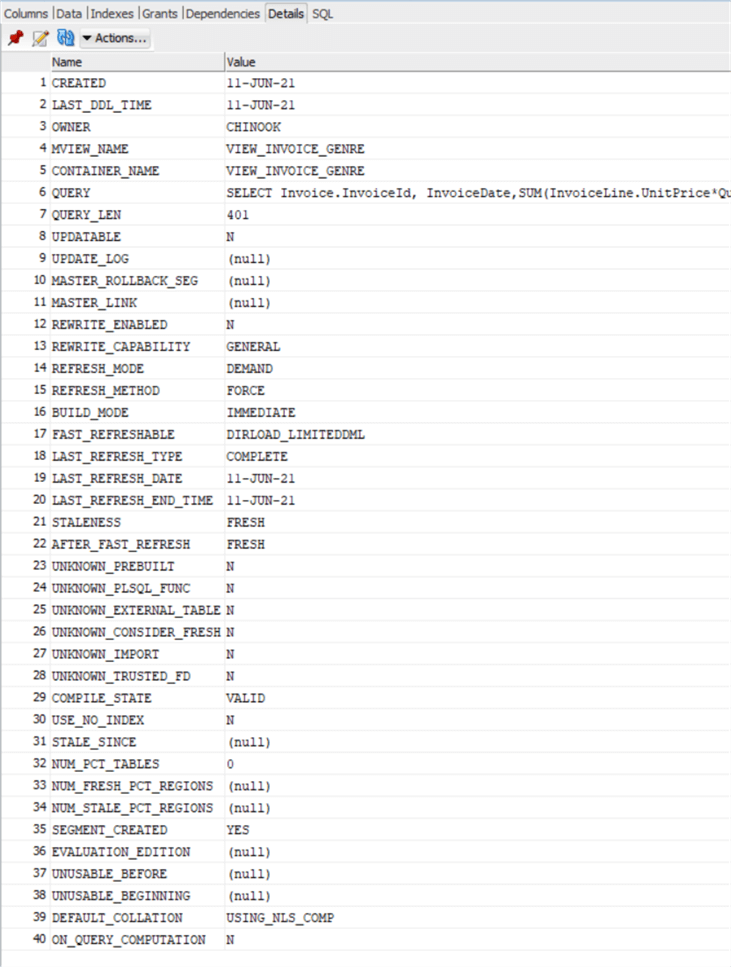
One interesting thing is that Materialized Views are treated like tables, in fact you can see this below:

We can see clicking on the view and going into the Details Tab a lot of information about this MV. Take a look at the REFRESH_MODE that says DEMAND. This means that the MV is not refreshed until we manually do it, in fact you see last refresh date coincides with the creation date. Please notice the STALENESS, STALE_SINCE and AFTER_FAST_REFRESH values that indicate also if an MV needs to be refreshed.
Now there are various methods to refresh MVs and there is also the possibility to make them refresh automatically any time there is a DML on the tables involved. Let’s see the most used/useful ways to do that.
Normally the best way to refresh an MV in Oracle is to set up a scheduler job to do that, using the DBMS_MVIEW package (REFRESH, REFRESH_ALL_MVIEWS, REFRESH_DEPENDENT). So that is what we’ll do first:
begin
DBMS_MVIEW.REFRESH(
LIST => 'CHINOOK.VIEW_INVOICE_GENRE'
,METHOD => '?'
,REFRESH_AFTER_ERRORS => FALSE
,PARALLELISM => 0
,ATOMIC_REFRESH => FALSE
,NESTED => TRUE);
END;
Some explanations on the parameters:
- LIST is obviously the list of materialized views that we want to refresh, if we would like to refresh all MVs owned by the user we can directly use REFRESH_ALL_MVIEWS instead of REFRESH.
- METHOD is the refresh method, it can be F for Fast, C for Complete, P for FAST_PCT or ? for Force. The Fast method, as the word says is the fastest as it tries to incrementally apply changes to the MV, it chooses the most efficient method between log-based and FAST_PCT. The FAST_PCT as per Oracle doc "Refreshes by recomputing the rows in the materialized view affected by changed partitions in the detail tables". Complete recreates the whole MV based on the view query and finally Force method tries first a fast and if it is not possible then does a complete.
- REFRESH_AFTER_ERRORS can be true or false, if set to true then an updatable MV continues to refresh even with conflicts logged.
- PARALLELISM if set to 0 no parallelism
- ATOMIC_REFRESH is interesting as if set to true "then the list of materialized views is refreshed in a single transaction. All of the refreshed materialized views are updated to a single point in time. If the refresh fails for any of the materialized views, none of the materialized views are updated." If False then each of the materialized views is refreshed non-atomically in separate transactions. The interesting thing and one of the reasons I always set this parameter to False is that with atomic refresh you make an extensive use of the undo TABLESPACE in order to have the possibility to rollback the whole transaction, then if you are dealing with a lot of data (millions of rows) and complex queries you can end up completely filling the UNDOTABLESPACE! Since ATOMIC_REFRESH is almost 99% of the cases is not needed it is better to avoid this and use it only if really needed.
- NESTED again true or false if set to true performs nested refresh operations for the MV.
For a complete and exhaustive list of all the parameters and the meanings, here’s the link to official Oracle doc.
We can manually run the above Procedure and then check with a simple query on the system view DBA_MVIEWS (or USER_MVIEW if we are connected with the owner of the MV and do not have DBA privileges) and see what has happened:
select owner, mview_name, last_refresh_type, last_refresh_date, staleness,stale_since from DBA_MVIEWS;

Now we can setup a job in order to schedule the refresh. In order to do this, in Oracle SQL Developer under the tab Scheduler, jobs, right click on it and choose new job:

We then copy the above procedure in the PL/SQL Block, give the job a name and then setup a repeat interval:


Finally, we can setup also a notification in case the job fails, in this case we need to have db mail setup in order for Oracle to send email:

Now we can click on the Apply button and we have our refresh job setup.

The other method of refresh is to modify this MV and make it refreshable on commit, that means that every modification on any of the tables taken by the MV query are immediately reflected on the MV at the commit. That obviously comes at a cost, because it will inevitably increase commit time on all the involved tables.
Let’s modify our MV:
ALTER MATERIALIZED VIEW CHINOOK.VIEW_INVOICE_GENRE REFRESH ON COMMIT FORCE;
We can check this by adding a couple of columns to the query on the system view that we used above:
select owner, mview_name, last_refresh_type, to_char(last_refresh_date,'dd/mm/yyyy hh:mm') as last_refresh_date
,staleness,stale_since, refresh_method, refresh_mode
from DBA_MVIEWS;

Let’s check for one invoice:
SELECT * FROM CHINOOK.view_invoice_genre WHERE invoiceid=227;

And if we try to update or insert into one of the tables:
UPDATE chinook.invoiceline SET unitprice=1.00 WHERE invoiceid=227; commit;
We check the same invoice in the materialized view:
SELECT * FROM CHINOOK.view_invoice_genre WHERE invoiceid=227;
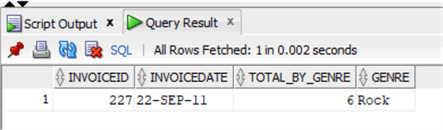
So, we see that we have now successfully updated the data in the Materialized View, without actually having to manually refresh it.
PostgreSQL Materialized View
In PostgreSQL there is a similar concept of materialized views as in Oracle, let’s do the same MV:
CREATE materialized VIEW view_Invoice_Genre
AS
SELECT "Invoice"."InvoiceId", "InvoiceDate", SUM("InvoiceLine"."UnitPrice"*"Quantity") AS Total_by_Genre, "Genre"."Name" AS Genre
FROM "Invoice"
INNER JOIN "InvoiceLine" ON "InvoiceLine"."InvoiceId" = "Invoice"."InvoiceId"
INNER JOIN "Track" ON "Track"."TrackId" = "InvoiceLine"."TrackId"
INNER JOIN "Genre" ON "Genre"."GenreId" = "Track"."GenreId"
GROUP BY "Invoice"."InvoiceId",
"InvoiceDate",
"Genre"."Name"
with data;
Please notice the option with [no] data that specifies if the MV should be created with all data or not, if not the materialized view is unscannable and cannot be queried until a REFRESH MATERIALIZED VIEW is issued.


Also please notice that since it is a MV there is the possibility to apply an index on it like on a table, this is different from SQL Server as I explained above.
In PostgreSQL in order to refresh the materialized view, there is only one possibility using the REFRESH MATERIALIZED VIEW command and manually refreshing the view, and eventually scheduling it like in Oracle. Unfortunately, in PostgreSQL there is not a job scheduler as part of the RDBMS installation such as SQL Server Agent or Oracle Scheduler. For that reason, you would need to use a third party application such as cron which is part of Linux or pg_agent. I will not follow the installation and setup of these products as it is out of scope for this tip.
Refreshing the MV in PostgreSQL means however completely locking the entire table until the refresh is finished, so if we need to be able to access the MV during the refresh we need to specify the option CONCURRENTLY. Anyway, this can be done only if we have a UNIQUE index on the MV. Let’s do an example and modify the InvoiceLine table as we’ve done in Oracle, checking first the values in the materialized view:
SELECT * FROM CHINOOK.view_invoice_genre WHERE invoiceid=227;

UPDATE "InvoiceLine" SET "UnitPrice"=1.00 WHERE "InvoiceId"=227;

Now let’s refresh the MV:
REFRESH MATERIALIZED VIEW view_invoice_genre;

And see the values in the MV:
SELECT * FROM CHINOOK.view_invoice_genre WHERE invoiceid=227;

Now let’s try the option CONCURRENTLY:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_invoice_genre;

Since we do not have a Unique index, the above error is thrown, you see that the hint is very helpful! Let’s create the index:
CREATE UNIQUE INDEX idx_invoiceid_genre ON view_invoice_genre ("InvoiceId",genre)

And let’s see the concurrently option now:
REFRESH MATERIALIZED VIEW CONCURRENTLY view_invoice_genre;

Updatable Views
Another interesting point is the possibility to use a view to do DML on a table (UPDATE, INSERT or DELETE). Obviously, there are some restrictions in order to have this possibility, let’s do a quick example:
SQL Server Updatable View
Let’s take the first view we did at the beginning of this tip as it has no aggregations and no set based computations which are the main limitation for Updatable Views, the other is that all the columns involved must reference only one table:
UPDATE dbo.view_Album SET composer = REPLACE(composer,'roger glover','Roger Glover') WHERE Genre = 'Rock' AND composer LIKE '%glover%'

Let’s check the underlying table:
SELECT * FROM Track WHERE Composer like '%glover%'

We can see that now the rows where Roger Glover was listed as a composer, but without capital letters has been corrected.
For a complete list of all the restrictions on updatable views please refer to official documentation here, under section Updatable Views: CREATE VIEW (Transact-SQL)
Oracle Updatable View
The concept and restrictions are very similar in Oracle, so let’s perform the same update:
UPDATE chinook.view_Album SET composer = REPLACE(composer,'roger glover','Roger Glover') WHERE Genre = 'Rock' AND composer LIKE '%glover%';

And check the underlying table after commit:
SELECT * FROM chinook.track WHERE composer LIKE '%Glover%';

We see the table has been updated.
A complete list of restrictions on Oracle updatable views is under CREATE VIEW documentation in the Notes on Updatable Views section: CREATE VIEW
PostgreSQL Updatable View
Finally, let’s try the same concept in PostgreSQL:
UPDATE view_Album
SET "Composer" = REPLACE("Composer",'roger glover','Roger Glover')
WHERE genre = 'Rock' AND "Composer" LIKE '%glover%'

Unfortunately, in PostgreSQL we have one another limitation compared with SQL Server and Oracle. In order for the view to be updatable it must have just one entry in the FROM clause, so views with JOINs are not updatable!
Official Documentation for PostgreSQL in CREATE VIEW under Updatable Views section: CREATE VIEW
Next Steps
- We have learned in this tip some of the features, possibilities and limitations associated with views in SQL Server, Oracle and PostgreSQL. This it is by far not an exhaustive list of what is possible to do with views, but more an introduction on this topic, albeit a long introduction! We have also seen that PostgreSQL has some more limitations regarding materialized and updatable views.
- Reference the official documentation:
- SQL Server
- Oracle
- PostgreSQL and the CREATE VIEW above mentioned
- Official Documentation on Indexed Views and Materialized Views:
- Interesting tip on view limitations: Limitations When Working with SQL Server Views
- More articles on views: SQL Server Views Tips






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-07-29
