By: Aubrey Love | Updated: 2021-09-09 | Comments (6) | Related: > TSQL
Problem
So, you have a basic understanding of the GROUP BY clause in SQL Server, but you still feel like there is more to this simple clause than you have been taught. Well, you would be right, at least for some people. A majority of us learned the basics but no one ever went any further with explaining the full spectrum of this clause, what it is capable of and how to take advantage of its diversity. I’ve seen plenty of training videos, attended a few classes that attempted to teach the basics of SQL Server / T-SQL, and so far, none of them have delved deep into the full abilities of the GROUP BY clause.
Solution
In this tutorial we will cover the basics of the GROUP BY clause and then we will delve further in and try to expand on all, or at least most, of the abilities of the clause and how you can take advantage of its options. Kind of a GROUP BY on steroids.
We will start with the basics, adding in some features like CUBE, ROLLUP and GROUPING SETS, but we also be discussing other benefits as well as the limitations of the GROUP BY clause.
Getting AdventureWorks Sample Database for Testing
For simplicity’s sake and keeping with a standard test database, we will be working with the AdventureWorks2014 database. If you already have this sample database installed, don’t worry, we will not be changing any of the tables or data. We will, however, create some new tables along with a new schema to work with. Afterwards, we will simply dump the tables as well as any schemas we create. (If you so choose.)
If you do not have the AdventureWorks2014 database installed already, you can get a backup (BAK) version for free at this link: AdventureWorks sample databases
Once it’s downloaded, simply follow the basic steps to restore from a ".BAK" file in your SQL Server Management Studio.
If you don’t want to mess with sifting through the above referenced webpage to find the correct database, you can click this link to initialize a direct download from Microsoft’s GitHub repository.
Now, let’s dive right in and learn about the GROUP BY clause from the ground up.
GROUP BY Statement Basics
In the code block below, you will find the basic syntax of a simple SELECT statement with a GROUP BY clause.
SELECT columnA, columnB FROM tableName GROUP BY columnA, columnB; GO
At the core, the GROUP BY clause defines a group for each distinct combination of values in a grouped element.
In simpler terms, the GROUP BY clause combines rows into groups based on matching data in specified columns of a table. One row will be returned for each group.
For example, if you have a column named "Title" in your table and it has three values (manager, programmer, and clerk), but the table has 20 rows, there will be duplicate entries of the three values in the "Title" column even though you have unique persons assigned to each row in the "Name" column. The GROUP BY clause will break all 20 rows into three groups and return only three rows of data, one for each group.
Important points for the GROUP BY SQL Statement:
- The GROUP BY statement can only be used in a SQL SELECT statement.
- The GROUP BY statement must be after the WHERE clause. (If one exists.)
- The GROUP BY statement must be before the ORDER BY clause. (If one exists.)
- To filter the GROUP BY results, you must use the HAVING clause after the GROUP BY.
- The GROUP BY statement is often used in conjunction with an aggregate function such as COUNT, MIN, MAX, AVG, or SUM.
- All column names listed in the SELECT command must also appear in the GROUP BY statement whether you have an aggregate function or not.
- Except for TEXT, NTEXT, and IMAGE, any column can be called in the GROUP BY statement.
![]() In
2017, Microsoft stated that the data types "TEXT", "NTEXT",
and "IMAGE" would be deprecated in future versions of SQL Server. However,
they are still applicable in SQL Server 2019 with SSMS version 18, although you
still cannot use them in a GROUP BY clause. Of course, there are exceptions to every
rule I suppose. You can read more about this in the section titled "A Work-Around"
at the end of this SQL Tutorial.
In
2017, Microsoft stated that the data types "TEXT", "NTEXT",
and "IMAGE" would be deprecated in future versions of SQL Server. However,
they are still applicable in SQL Server 2019 with SSMS version 18, although you
still cannot use them in a GROUP BY clause. Of course, there are exceptions to every
rule I suppose. You can read more about this in the section titled "A Work-Around"
at the end of this SQL Tutorial.
IIt is important to note that using a GROUP BY clause is ineffective if there are no duplicates in the column you are grouping by. When using the AdventureWorks2014 database and referencing the Person.Person table, if you GROUP BY the "BusinessEntityID" column, it will return all 19,972 rows with a count of 1 on each row. A better example would be to group by the "Title" column of that table. The SELECT clause below will return the six unique title types as well as a count of how many times each one is found in the table within the "Title" column. This is the core basics of using a GROUP BY clause.
USE AdventureWorks2014; GO SELECT Title, COUNT(*) AS 'Count' FROM Person.Person WHERE Title IS NOT NULL GROUP BY Title; GO
Results:
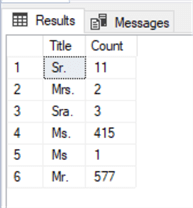
An ORDER BY clause was not used in this sample and as you can see there is no order to the result set. If you need to use an ORDER BY clause, it must follow the GROUP BY clause. The other item you may notice in the above query, is that we used a WHERE filter to cull out any rows that are NULL. This is certainly optional. If you want to include the rows that are NULL, simply remove the WHERE clause from the query.
The following results are given when we allow NULL values by removing the WHERE clause from the code block above.
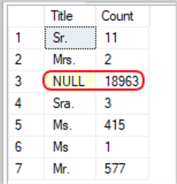
AlAlthough the GROUP BY clause is most commonly used with the COUNT, AVG, MIN, MAX, and SUM functions to return numerical data, for the purpose of charts among other reasons, it can also be used to categorize names, places, regions, etc. without returning, nor relying on, a numeric value. In the sample below, we will return a list of the "CountryRegionName" column and the "StateProvinceName" from the "Sales.vSalesPerson" view in the AdventureWorks2014 sample database. In the first SELECT statement, we will not do a GROUP BY, but instead, we will simply use the ORDER BY clause to make our results more readable sorted as either ASC (default) or DESC.
In the second SELECT statement, we will GROUP BY the "CountryRegionName" followed by the "StateProvinceName" columns. The first SELECT statement will return all 17 rows in the table. However, the second SELECT statement will only return 14 rows. Since "Washington, United States" is listed four times in the table, the GROUP BY clause will "group" those four entries into one entry for Washington.p>
USE AdventureWorks2014; GO SELECT StateProvinceName, CountryRegionName FROM Sales.vSalesPerson ORDER BY CountryRegionName, StateProvinceName; GO SELECT StateProvinceName, CountryRegionName FROM Sales.vSalesPerson GROUP BY CountryRegionName, StateProvinceName; GO
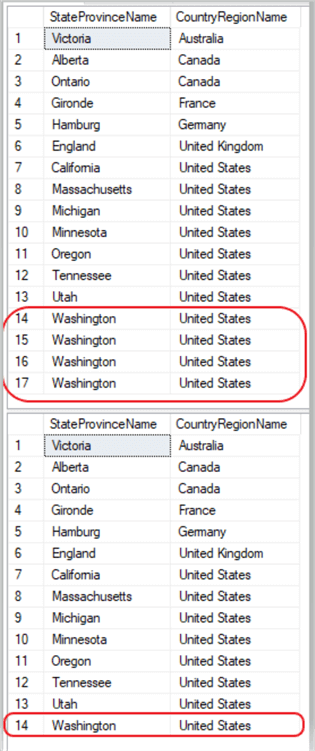
It’s not often you will need to return results like the sample above, most of the time you will be working with an aggregate function. But, it’s nice to know that you can do this as well as how to do this, should the need arise.
Now, moving forward to some more common methods of using the GROUP BY clause.
Aggregates with the SQL GROUP BY Clause
T-SQL (Transact SQL) offers nine aggregate functions, all of which can be used with the GROUP BY clause. The five most common aggregate functions that will be discussed in this article are the, COUNT(), AVG(), MIN(), MAX(), and SUM(). The four remaining aggregate functions; STDDEV(), STDDEVP(), VAR(), and VARP() functions are specifically related to financial and statistical calculations.
The STDDEV() and STDDEVP() functions calculate sample standard deviation and population standard deviation respectively. The VAR() and VARP() functions calculate the sample variance and population variance respectively. An easy way to remember what these four do, is to remember that the DEV named functions provide deviation statistics, while the VAR named functions provide the variance statistics. You can read more about these four aggregate functions on Microsoft Docs.
COUNT()
In its simplest form, the COUNT() function can be used in one of two ways. Within the parenthesis you can call the column name that you want to count by, or you can use an * (asterisk) between the parenthesis.
- Using the * (asterisk) will count and return all rows even if they contain a NULL value.
- Specifying the column name will not count or return any rows that have a NULL value.
So, it really depends on whether or not you need the data from the associated columns/rows where the focused column contains a NULL value.
Now, let’s use the COUNT() aggregate in the following query. Using the "Sales.vSalesPerson" view in the AdventureWorks2014 sample database, we will count how many times each country or region appears in that view.
USE AdventureWorks2014; GO SELECT CountryRegionName, COUNT(*) AS 'Count' FROM Sales.vSalesPerson GROUP BY CountryRegionName; GO
Results:
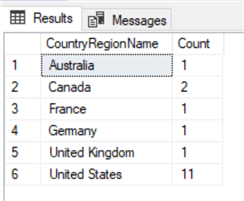
As you can see, the query returned a count of 11 for the United States, 2 for Canada, and 1 for each of the remaining countries. These represent how times, or how many rows, these places are found in the "Sales.vSalesPerson" view.
In this context, the GROUP BY works similarly to the DISTINCT clause by returning only one entry per country/region. However, unlike the DISTINCT clause, when we added the COUNT() function, the results displayed how many times each country/region is found in the table.
AVG()
The AVG() function sums all the non-null values in a set, then divides that number by the amount of non-null values in that set to return the average value as the result. Unlike the COUNT() function, the AVG() function will not accept the wild card * (asterisk) as a value within the parenthesis. You must specify which column you want to return an averaged value on. Since the AVG() function is adding and dividing, (doing arithmetic on the column values), the columns must contain a numeric value. For example, you cannot return an average on a column that contains character (CHAR, VARCHAR, NVARCHAR) data types.
In the sample below, we are returning the average sales bonus value for each territory in the Sales.SalesPerson column from the AdventureWorks2014 database.
SELECT TerritoryID , AVG(Bonus) AS 'Avg Bonus' FROM Sales.SalesPerson WHERE TerritoryID IS NOT NULL GROUP BY TerritoryID; GO
Results:
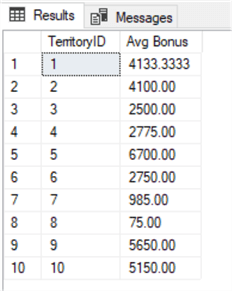
WeWe added a "WHERE" clause to cull out any NULL valued rows. This was just for clarity's sake. Since T-SQL ignores any NULL valued rows, it makes this WHERE clause purely cosmetic in nature. Had we left out the WHERE clause, the returned values would remain the same for all rows, except for the additional row representing the NULL values. The sample below shows the results without the WHERE clause.
SELECT TerritoryID , AVG(Bonus) AS 'Avg Bonus' FROM Sales.SalesPerson GROUP BY TerritoryID; GO
Results:
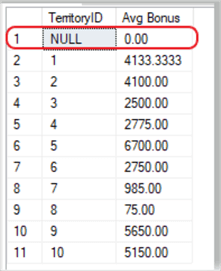
For the three following aggregates, use this link as a starting point: Max, Min, and Avg SQL Server Functions
MIN()
The MIN() function (as its name implies) returns the smallest value in the column specified. MIN() is not restricted to numeric values only as some people believe, it can also be used to return the lowest values of CHAR(), VARCHAR(), NVARCHAR(), UNIQUEIDENTIFIER, or datetime data types as well. However, it cannot be used with the BIT data type.
With the character data types CHAR(), VARCHAR(), and NVARCHAR(), the MIN() function sorts the string values alphabetically and returns the first (lowest) value in the alphabetized list.
Using the same Sales.SalePerson table as we did in the AVG() function example above, we will return the minimum value from the "Bonus" column instead of the average value.
USE AdventureWorks2014; GO SELECT TerritoryID , MIN(Bonus) AS 'MinBonus' FROM Sales.SalesPerson WHERE TerritoryID IS NOT NULL GROUP BY TerritoryID; GO
Results:
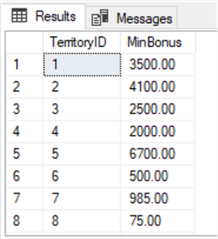
MAX()
In contrast to the MIN() function, the MAX() function returns the largest value of the specified column. It does this by utilizing a collating sequence allowing it to work as efficiently on character columns and datetime columns as it does on numeric columns. Keeping consistency, we again will be working with the Sales.SalesPerson table and return the maximum, or highest amount, paid in a bonus for each territory.
USE AdventureWorks2014; GO SELECT TerritoryID , MAX(Bonus) AS 'MAX Bonus' FROM Sales.SalesPerson WHERE TerritoryID IS NOT NULL GROUP BY TerritoryID; GO
Results:
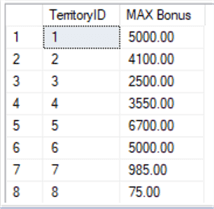
SUM()
The SUM() function returns the total value of all non-null values in a specified column. Since this is a mathematical process, it cannot be used on string values such as the CHAR, VARCHAR, and NVARCHAR data types. When used with a GROUP BY clause, the SUM() function will return the total for each category in the specified table.
Using the Sales.SalesPerson table in the AdventureWorks2014 database, we will return the sum (total) of all bonuses paid out to each territory found in the GROUP BY clause.
USE AdventureWorks2014; GO SELECT TerritoryID , SUM(Bonus) AS 'SUM Bonus' FROM Sales.SalesPerson WHERE TerritoryID IS NOT NULL GROUP BY TerritoryID; GO
Results:
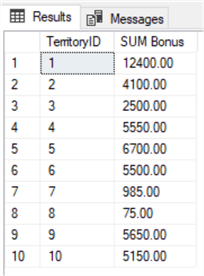
For the three following aggregates, use this link as a starting point: Group By in SQL Server with CUBE, ROLLUP and GROUPING SETS Examples.
GROUP BY ROLLUP
ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on. Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set.
The GROUP BY ROLLUP can be written in one of two ways. You can declare the ROLLUP extension before you call the column names or after. Both will return the same results. This is another one of those "personal preference" options of writing your SQL code.
Option 1: (Calling the ROLLUP extension before the column names)
GROUP BY ROLLUP(Country, RegionState);
Option 2: (Calling the ROLLUP extension after the column names)
GROUP BY Country, RegionState WITH ROLLUP;
Notice the parenthesis surrounding the column names in option 1 that are not present in option 2. Option 1 must have the parenthesis, option 2 must NOT have them.
Moving on. For this sample, we are going to create a new table in the AdventureWorks2014 database under the default "dbo" schema.
USE AdventureWorks2014;
GO
CREATE TABLE salesTest( Country VARCHAR(30), RegionState VARCHAR(30), Sales INT );
INSERT INTO salesTest VALUES('United States', 'Washington', 100);
INSERT INTO salesTest VALUES('United States', 'Main', 200);
INSERT INTO salesTest VALUES('United States', 'Oregon', 300);
INSERT INTO salesTest VALUES('Canada', 'Alberta', 100);
INSERT INTO salesTest VALUES('Canada', 'Ontario', 200);
GO
In the next block of code, we will generate a "rollup" of all the "summed" values from Canada, a rollup of all the "summed" values from the United States, and finally a "total summed" value on the two countries listed.
SELECT Country , RegionState , SUM(Sales) AS 'Total Sales' FROM salesTest GROUP BY ROLLUP(Country, RegionState); GO
Results:
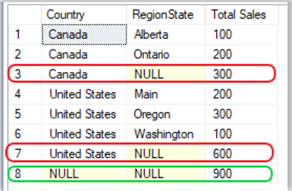
From the result set above, we see that line 3 is the total of lines 1 and 2 (the two regions from Canada), line 7 is the total from lines 4 – 6 (the three states from the United States) and line 8 is the grand (rollup) total of lines 3 and 7.
 You
can replace the NULL values in the table with descriptive values by altering the
SQL code block with the ISNULL constraint as shown in the sample below.
You
can replace the NULL values in the table with descriptive values by altering the
SQL code block with the ISNULL constraint as shown in the sample below.
SELECT ISNULL(Country, 'Rollup') AS 'Country' , ISNULL(RegionState, 'Total') AS 'RegionState' , SUM(Sales) AS 'Total Sales' FROM salesTest GROUP BY ROLLUP(Country, RegionState); GO
Results:
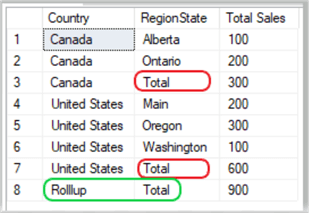
Again, line 3 is the rollup total for Canada, line 7 is the rollup total for the United States and line 8 is the "Grand" rollup total for lines 3 and 7.
GROUP BY CUBE
Another extension, or sub-clause, of the GROUP BY clause is the CUBE. The CUBE generates multiple grouping sets on your specified columns and aggregates them. In short, it creates unique groups for all possible combinations of the columns you specify. For example, if you use GROUP BY CUBE on (column1, column2) of your table, SQL returns groups for all unique values (column1, column2), (NULL, column2), (column1, NULL) and (NULL, NULL).
Perhaps the best way to understand this, is to see it action. Here we will continue using the table we created in the previous section "GROUP BY ROLLUP".
USE AdventureWorks2014; GO SELECT Country , RegionState , SUM(Sales) AS 'Total Sales' FROM salesTest GROUP BY ROLLUP(Country, RegionState); GO
Results:
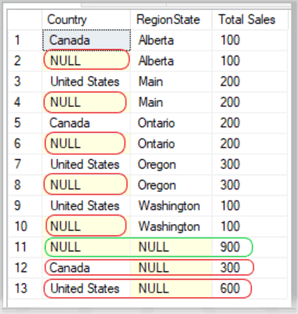
As you can see in the result set above, the query has returned all groups with unique values of (column1, column2), (NULL, column2), (column1, NULL) and (NULL, NULL). The NULL NULL result set on line 11 represents the total rollup of all the cubed roll up values, much like it did in the GROUP BY ROLLUP section from above.
GROUP BY GROUPING SETS()
The GROUPING SETS option gives you the ability to combine multiple GROUP BY clauses into one GROUP BY clause. The GROUP BY GROUPING SETS() clause produces the same results as a UNION ALL that is applied to the specified groups. In other words, if I used a UNION ALL to group two elements or groups into one, it would look something like the code block below.
USE AdventureWorks2014; GO SELECT Country , RegionState , SUM(Sales) AS TotalSales FROM salesTest GROUP BY ROLLUP(Country, RegionState) UNION ALL SELECT Country , RegionState , SUM(Sales) AS TotalSales FROM salesTest GROUP BY CUBE(Country, RegionState); GO
Results:
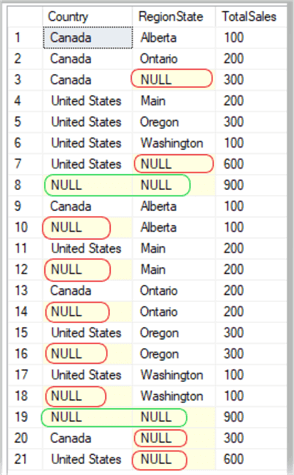
A way to condense that UNION ALL code would be to utilize the GROUPING SETS() sub-clause as in the sample below.
SELECT Country , RegionState , SUM(Sales) AS TotalSales FROM salesTest GROUP BY GROUPING SETS ( ROLLUP (Country, RegionState), CUBE (Country, RegionState) ); GO
Results:
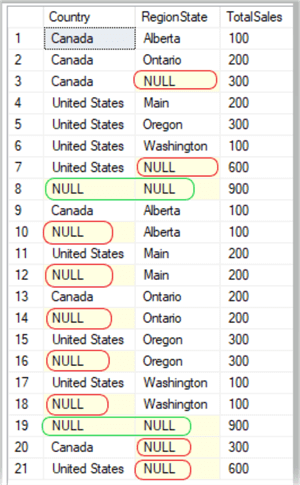
Don’t be surprised if your results do not return in the same order each time; the ORDER BY clause will assist with that.
As you can see, we are returning the same results as the UNION ALL, but with a bit less code.
But Wait, There’s More
I told you this was going to be GROUP BY on steroids. Here are some additional tricks for using the GROUP BY clause that those books and free videos wouldn’t tell you about.
GROUP BY with Multiple Tables
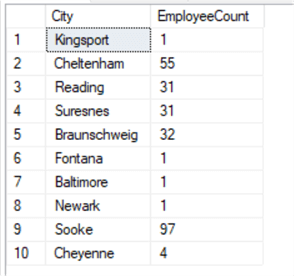
Like most things in SQL/T-SQL, you can always pull your data from multiple tables. Performing this task while including a GROUP BY clause is no different than any other SELECT statement with a GROUP BY clause. The fact that you’re pulling the data from two or more tables has no bearing on how this works. In the sample below, we will be working in the AdventureWorks2014 once again as we join the "Person.Address" table with the "Person.BusinessEntityAddress" table. I have also restricted the sample code to return only the top 10 results for clarity sake in the result set.
USE AdventureWorks2014; GO SELECT TOP(10) a.City , COUNT(b.AddressID) AS EmployeeCount FROM Person.Address AS a INNER JOIN Person.BusinessEntityAddress AS b ON a.AddressID = b.AddressID GROUP BY a.City; GO
Results:
GROUP BY with an Expression
Using a GROUP BY clause on a SELECT statement that contains an expression or built-in function reference, requires that you also include the same expression in both the SELECT statement as well as the GROUP BY clause. In the sample below, we will use the DATEPART function to return only the year from the "ModifiedDate" column of the "Sales.SalesTerritory" table along with the average amount due from the same table.
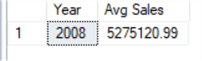
SELECT DATEPART(yyyy, ModifiedDate) AS 'Year'
,CAST(AVG(ROUND(SalesYTD, 2, 1)) AS numeric(9,2)) AS 'Avg Sales'
FROM Sales.SalesTerritory
GROUP BY DATEPART(yyyy, ModifiedDate);
GO
You may have noticed that I added a little extra code to this one on the second line. We are performing a ROUND() function on the "SalesYTD" column to return the results in a dollar format with two decimal places. Without the ROUND() function, our output would have been either 5275120.9953 (if we would have used the "money" datatype) or 5275121.00 (if we would have used the "numeric" data type) without the ROUND() function.
Results:
GROUP BY with a HAVING clause
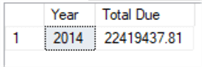
Adding a HAVING clause after your GROUP BY clause requires that you include any special conditions in both clauses. If the SELECT statement contains an expression, then it follows suit that the GROUP BY and HAVING clauses must contain matching expressions. It is similar in nature to the "GROUP BY with an EXCEPTION" sample from above. In the next sample code block, we are (still using the AdventureWorks2014 database) now referencing the "Sales.SalesOrderHeader" table to return the total (sum) from the "TotalDue" column, but only for a particular year. That year will be referenced within the HAVING clause.
SELECT
DATEPART(yyyy,OrderDate) AS 'Year'
,CAST(SUM(ROUND(TotalDue, 2, 1)) AS numeric(12,2)) AS 'Total Due'
FROM Sales.SalesOrderHeader
GROUP BY DATEPART(yyyy,OrderDate)
HAVING DATEPART(yyyy,OrderDate) = '2014';
GO
Results:
Limitations when using GROUP BY
As you would expect, there are a few limitations when using the GROUP BY clause in your SELECT statement. Below is a list of the main limitations that you will need to be familiar with.
For GROUP BY clauses that contain ROLLUP, CUBE or GROUPING SETS:
- The maximum number of expressions is 32.
- The maximum number of groups is 4096.
For GROUP BY clauses that do not contain ROLLUP, CUBE or GROUPING SETS:
- The number of GROUP BY items is limited by the GROUP BY column size, aggregate values, and aggregated columns.
A Work-Around for Text, NText and Image Data Types
If, for some reason, you are stilling using "TEXT", "Ntext", and/or "Image" datatypes in your database, it is highly recommended that you change them to an appropriate "current" datatype. If your situation prevents you from updating these antiquated data types but you still need to GROUP BY using one or more of these data types, there is a work-around for that.
For this sample, we must create a new table, since the AdventureWorks database samples do not come preloaded with any tables that contain any "TEXT", "NTEXT", or "IMAGE" data type columns.
USE AdventureWorks2014;
GO
CREATE TABLE textTest1(
colID INT IDENTITY NOT NULL
, fName VARCHAR(20)
, Title TEXT
);
GO
INSERT INTO textTest1(fName, Title)
VALUES('Bob', 'Programmer')
,('John', 'Manager')
,('Sarah', 'Clerk')
,('Melissa', 'Programmer')
,('Jeff', 'Manager')
,('Sam', 'Programmer')
,('Eliot', 'Programmer');
GO
Now that we have a table that contains a "TEXT" data type, let’s trying to run a standard SELECT – COUNT() query with a GROUP BY clause.
SELECT Title, COUNT(*) AS 'Count' FROM textTest1 GROUP BY Title; GO
This will produce a "level 16, State 2" error.
Msg 306, Level 16, State 2, Line xx The text, ntext, and image data types cannot be compared or sorted, except when using IS NULL or LIKE operator.
To work around this issue, we can use the CAST function to convert the TEXT data type to a VARCHAR data type and get the desired results returned without an error.
SELECT CAST(Title AS varchar) AS Title, COUNT(*) AS 'Count' FROM textTest1 GROUP BY CAST(Title AS varchar); GO
Note: you must use CAST() in both the SELECT statement as well as the GROUP BY clause. As mentioned earlier, in the "GROUP BY with an Expression" section, the GROUP BY clause parameter must be called exactly as it is in the SELECT statement.
Results:
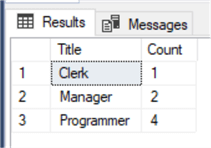
Here, we have returned the appropriate count for each of the three unique values in the Title column.
Just for future reference, if you are still using the TEXT, NTEXT, and IMAGE data types, you can use the CAST function to convert them to VARCHAR, NVARCHAR, and VARBINARY respectively.
A best practice would be to create a view from the above SELECT statement to save time and provide a more efficient way of grouping on the table(s) that have these deprecated data types.
Summary
The primary function of the GROUP BY clause is to divide the rows within a table into groups. Consider that a table is in itself a group, the GROUP BY clause simply breaks that large group into smaller groups, like mini tables. From there you can manipulate the data within those mini tables (groups) in just about any way you can imagine.
Contrary to what most books and classes teach you, there are actually 9 aggregate functions, all of which can be used with a GROUP BY clause in your code. As we have seen in the samples above, you can have a GROUP BY clause without an aggregate function as well. As we demonstrated earlier in this article, the GROUP BY clause can group string values also, so it doesn’t always have to be a numeric or date value.
To sum it all up, there is a lot more to the GROUP BY clause than you would normally learn in an introductory SQL class.
Next Steps
- Group By in SQL Sever with CUBE, ROLLUP and GROUPING SETS Examples
- GROUP BY in SQL Server
- Aggregate Functions
- CUBE and ROLLUP in SQL Server
- HAVING clause in SQL Server






About the author
 Aubrey Love is a self-taught DBA with more than six years of experience designing, creating, and monitoring SQL Server databases as a DBA/Business Intelligence Specialist. Certificates include MCSA, A+, Linux+, and Google Map Tools with 40+ years in the computer industry. Aubrey first started working on PC’s when they were introduced to the public in the late 70's.
Aubrey Love is a self-taught DBA with more than six years of experience designing, creating, and monitoring SQL Server databases as a DBA/Business Intelligence Specialist. Certificates include MCSA, A+, Linux+, and Google Map Tools with 40+ years in the computer industry. Aubrey first started working on PC’s when they were introduced to the public in the late 70's.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-09-09
