By: Ron L'Esteve | Updated: 2022-03-29 | Comments (2) | Related: > Azure Databricks
Problem
The concept of event driven ETL paradigms has been a long-standing desire in the data engineering ecosystem, and even more so as modern data architectures explore and approach the Lakehouse paradigm, which includes the concept of building out an entire Data warehousing ecosystem in a Data Lake. While there are numerous event driven data ingestion patterns in Azure, managing the changing schemas for streaming data has traditionally been a challenge. Additionally, the set-up and management of event grid subscriptions, topics and more have also been a challenge to seamlessly integrate with Spark. Auto Loader provides a structured streaming source called cloudFiles which offers the capability of incrementally processing new files as they arrive in Azure Data Lake Storage Gen2, while also managing advanced schema evolution of this streaming data, and finally storing this data in a dataframe. How can we get started with Auto Loader and cloudFiles?
Solution
Auto Loader within Databricks runtime versions of 7.2 and above is a designed for event driven structure streaming ELT patterns and is constantly evolving and improving with each new runtime release. With the release of Databricks runtime version 8.2, Auto Loader's cloudFile source now supports advanced schema evolution. With schema inference capabilities, there is no longer the need to identify and define a schema. In this article, I will demonstrate how to get started with using Auto Loader cloudFiles through an end-to-end practical example of ingesting a data stream which has an evolving schema. Within this exercise, you will learn how to setup Auto Loader cloudFiles in Azure, work with evolving streaming data schemas, track changing schemas through captured versions in schema locations, infer schemas and/or define schemas through schema hints.
Pre-requisites
There are a few set up steps that are required for Auto Loader cloudFiles to work effectively. In this section, you will learn how to create these pre-requisites which include generating the JSON files which will be used for this exercise, completing the necessary set-up with Azure portal and configuring Databricks secret scopes.
Prior to continuing this section, ensure that you have created the following Azure resources:
- Azure Databricks
- Azure Key Vault
- Azure Data Lake Storage Gen2
SQL
For the purpose of this exercise, let's use JSON format files for the source files that will be ingested by Auto Loader cloudFiles, since this format demonstrated a semi-structured, complex and evolving format. You can prepare these source files by using the Adventure Works LT2019 database which I have worked with and demonstrated how to import into SSMS in previous articles. Use the Customer table to generate three source files that you will feed into the streaming Auto Loader cloudFiles source.

Begin by writing the following SQL query which takes a handful of columns from the Customer table and returns them as JSON format for each record per line. Save the results of this query as a JSON file which you could call Customer1.json. You will also need to repeat this exercise two more time to create two additional customer JSON files. With each iteration of the code, you will need to add additional columns to the query to truly mimic an evolving schema.

Here is the SQL query which is used for Customer1.json.
SELECT
(
SELECT firstname,
lastname,
middlename,
title,
customerid FOR json path,
without_array_wrapper)
FROM saleslt.customer
Similar to the previous query, here is the SQL query which is used for Customer2.json.
SELECT
(
SELECT firstname,
lastname,
middlename,
title,
customerid,
companyname,
emailaddress,
salesperson,
namestyle FOR json path,
without_array_wrapper)
FROM saleslt.customer
Finally, here is the SQL query which is used for Customer3.json.
SELECT
(
SELECT firstname,
lastname,
middlename,
title,
customerid,
companyname,
emailaddress,
salesperson,
namestyle,
modifieddate,
phone,
rowguid FOR json path,
without_array_wrapper)
FROM saleslt.customer
Now that you have created Customer1.json, Customer2.json, and Customer3.json files by using the source SQL queries within this section, you are ready to upload these JSON files into ADLS gen2.
Azure Data Lake Storage Gen2
Within ADLS gen2, you will need to create a few new folders. Create a Customer folder and load all of the Customer JSON files that you had created in the previous section into this folder.

Also create a Customer_stream folder and load the Cutomer1.json file. All files that will be added to this folder will be processed by the streaming Auto Loader cloudFiles source.

Azure Portal
There are a few configurations that need to be completed in the Azure portal. Begin by navigating to Resource providers in your Azure Subscription and register Microsoft.EventGrid as a resource provider.

Next, navigate to Azure Active Directory and register a new application. You will need the client ID, tenant ID and client secret of this new app and will need to also give this app access to ADLS gen2.

Once you finish registering this new app, navigate to Certificates and secrets and create a new client secret.

Within ADLS gen2, navigate to Access Control (IAM) and add a new role assignment. Give the app that you previously registered contributor access to ADLS gen2.

At this point, begin copying the credentials and keys from the various application so that you can store them in a Key Vault. Databricks will have access to this key vault and Auto Loader will use these credentials to created event grid subscriptions and topics to process the incoming streaming data. Begin by navigating to the App that you registered in the previous section and copy ClientID and TenantID and save them in a notepad.

Next, navigate to the registered App's Certificates and secrets tab and create a new secret. Once created, copy the ClientSecret and paste this into the notepad as well.

You will also need to navigate to the ADLS gen2 Access keys tab, copy the SASKey, and paste it into the notepad.

Within ADLS gen2, navigate to Shared access signature, ensure that the Allowed services, resource types, and permissions are configured accurately. Generate the connection string, copy it and paste in the notepad.

There is one final step in the Azure portal pre-requisites section. Use all of the values that you have previously pasted into notepad as Key Vault secrets. Do this by navigating to Key Vault's Secrets tab, generate a new secret and create the following secrets. You will also need to add your resource group and Subscription ID as secrets. Ensure that the following seven secrets are created and enabled.

Databricks
In Databricks, create a new secret scope by navigating to
https://<DATABRICKS-INSTANCE>#secrets/createScope and replace <DATABRICKS-INSTANCE> with your own Databricks URL instance.
This URL will take you to the UI where you can create your secret scope. Paste the
Key Vault URI and Resource ID from your Key Vault into the respective DNS Name and
Resource ID section.

Create a new Cluster with Databricks Runtime Version of 8.2, which supports the advanced schema evolution capabilities of Auto Loader cloudFiles.

To prevent any errors at run-time, also install the Event Hubs library to the cluster. This Maven library contains the following coordinates.

This concludes all of the required prerequisites in Databricks.
Run Auto Loader in Databricks
In this section, you will learn how to begin working with Auto Loader in a Databricks notebook.
Configuration Properties
To begin the process of configuring and running Auto Loader, set the following configuration, which specifies either the number of bytes or files to read as part of the config size required to infer the schema.

Here is the code shown in the figure above. Note that you could use either the numBytes or numFiles properties.
#spark.conf.set("spark.databricks.cloudfiles.schemaInference.sampleSize.numBytes",10000000000)
spark.conf.set("spark.databricks.cloudfiles.schemaInference.sampleSize.numFiles",10)
This next block of code will obtain the list of secrets that you have created in your Key Vault.

Here is the code that is used in the figure above. Since you have given Databricks access to the Key Vault secret scope, there should be no errors when your run this code.
subscriptionId = dbutils.secrets.get("akv-0011","subscriptionId")
tenantId = dbutils.secrets.get("akv-0011","tenantId")
clientId = dbutils.secrets.get("akv-0011","clientId")
clientSecret = dbutils.secrets.get("akv-0011","clientSecret")
resourceGroup = dbutils.secrets.get("akv-0011","resourceGroup")
queueconnectionString = dbutils.secrets.get("akv-0011","queueconnectionString")
SASKey = dbutils.secrets.get("akv-0011","SASKey")
Rescue Data
This next block of code will build your cloudFiles config. Notice that the format is listed as JSON, but could just as easily be any other format. Define the schema location within your Customer_stream folder and set the schema evolution mode as rescue. There are additional options which have been commented out in this section, however we will cover some of these details in later sections.

Here is the code which is shown in the figure above. Since cloudFiles will automatically create EventGrid topics and subscriptions it will need the credentials in this code to get access to the relevant Azure resources. The _checkpoint folder will store the schema meta-data and will also keep track of multiple versions of the evolved schemas. The partitionColumns config provides the option to read Hive style partition folder structures. The schema evolution mode of 'failOnNewColumns' will simply fail the job when new columns are detected and will require manual intervention to define and update and new schema. We will not be exploring this option.
cloudfile = {
"cloudFiles.subscriptionID": subscriptionId,
"cloudFiles.connectionString": queueconnectionString,
"cloudFiles.format": "json",
"cloudFiles.tenantId": tenantId,
"cloudFiles.clientId": clientId,
"cloudFiles.clientSecret": clientSecret,
"cloudFiles.resourceGroup": resourceGroup,
"cloudFiles.useNotifications": "true",
"cloudFiles.schemaLocation": "/mnt/raw/Customer_stream/_checkpoint/",
"cloudFiles.schemaEvolutionMode": "rescue"
#"cloudFiles.inferColumnTypes": "true"
#"cloudFiles.schemaEvolutionMode": "failOnNewColumns"
#"cloudFiles.schemaEvolutionMode": "addNewColumns"
#"cloudFiles.partitionColumns": ""
}
With the AdditionalOptions properties, you can define schema hints, rescued data columns and more. In this code block, you are specifying which column to add the rescued data into.

Here is the code which is shown in the figure above.
AdditionalOptions = {"rescueDataColumn":"_rescued_data"}
In this next code block, set the ADLS gen2 config by adding the ADLS gen2 account and SAS Key.

Here is the code which is shown in the figure above.
spark.conf.set("fs.azure.account.key.adlsg2v001.dfs.core.windows.net","SASKey")
Run the following code to configure your data frame using the defined configuration properties. Notice that by default, the columns are defaulted to 'string' in this mode. Nevertheless, cloudFiles is able to automatically infer the schema.

Here is the code that is used in the figure above.
df = (spark.readStream.format("cloudFiles")
.options(**cloudfile)
.options(**AdditionalOptions)
.load("abfss://[email protected]/raw/Customer_stream/"))
Upon navigating to the Customer_stream folder in ADLS gen2, notice that there is now a new _checkpoint folder that is created as a result of running the code above.

Within the _schemas folder there is a file named 0. This file contains the initial meta data version of the schema that has been defined.

Upon opening the file, notice how it captures the JSON data frame schema structure as expected.
{"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"FirstName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"LastName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"MiddleName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"Title\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"customerid\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}"}
Schema Hints
Navigate back to the Databricks notebook and to the code block which contains AdditionalOptions. This time, add the following schemaHints. This is particularly useful if you wish to explicitly define the schema of a particular column.

Here is the code that is used in the figure above. Remember to delete your _schemas folder so that the process can infer the schema from scratch once again.
AdditionalOptions = {
"cloudFiles.schemaHints":"customerid int",
"rescueDataColumn":"_rescued_data"}
Re-run the following code and notice that customerid has this time been inferred as an integer rather than a string.

Here is the code that is used in the figure above.
df = (spark.readStream.format("cloudFiles")
.options(**cloudfile)
.options(**AdditionalOptions)
.load("abfss://[email protected]/raw/Customer_stream/"))
Infer Column Types
Navigate to the cloudfile config code block and uncomment "cloudFiles.inferColumnTypes": "true", which provides the capability of automatically inferring the schema of you incoming data.

Additionally, this time, remove the schemHints from the AdditionalOptions code block.

Also, once again, remember to delete the contents of the _checkpoint folder so that you are re-inferring the schema from scratch.

Re-run the following code and notice that this time, without schemaHints, customerid has been inferred as 'long'.

Go ahead and run the following command to initialize the stream and display the data.

As expected, notice that the data from Customer1.json is being displayed. Notice that the _rescued_data column is null since there is no data that needs to be rescued yet. When you begin adding new columns from Customer2 and Customer3 JSON files, these additional columns will be captured in this column since the rescue data config properties is enabled.
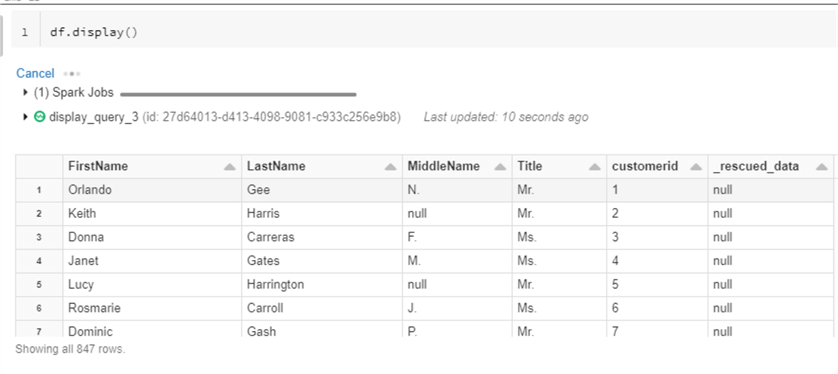
Now it is time to add Customer2.json to our Customer_stream folder. Since Customer2 has more columns it should demonstrate how schema evolution is handled by Auto Loader cloudFiles.

After navigating back to the streaming query, notice that the newly added columns from Customer2.json are all added to the _rescued_data column in the dataframe, as expected. Since Auto Loader is constantly watching for new files, there is no need to re-run this query since the update occurs every 5-10 seconds.

When you check your _schemas folder, you will only see the version 0 schema struct file which contains the original file from Customer1.json. This is because the schema is still fixed and all new columns are added to the _rescued_data column.

Add New Columns
Now that you have seen how rescue data works, lets enable to schema evolution mode of 'addNewColumns' so that we could include the new columns and now simply bucket them into the _rescued_data column. This process should now also create a new version of the schema struct file in the _schemas folder.

Notice how the stream failed this time, which is deliberate since it follows the patterns of failing the job, updating the new schema, and then include the schema when the job is re-started. This is intended to follow the best practices of streaming architecture which contains automatic failures and re-tries.

Re-start the streaming job and notice that this time the new additional columns from Customer2.json are included in the schema.

Re-run the df.display() command and notice that the additional columns are displayed in the data frame.

Upon navigating back to the _schemas folder in ADLS gen2, notice that there is a new version 1 of the schema struct file.
Upon opening this file, notice that it contains the additional columns that were added from Customer2.json.
v1
{"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"FirstName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"LastName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"MiddleName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"Title\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"customerid\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}},{\"name\":\"CompanyName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"EmailAddress\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"SalesPerson\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"namestyle\",\"type\":\"boolean\",\"nullable\":true,\"metadata\":{}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}"}
Similar to the previous demonstration, add the Customer3.json file to the Customer_stream folder in ADLS gen2 and notice once again that the stream will fail, as expected.

Re-start the stream by running the following code and notice that the new columns from Customer3.json are included.

Also, notice that the new columns from Customer3.json are included in the streaming data frame.

Similar to the previous example, there is yet another schema struct file included in the _schemas folder in ADLS gen2 which contains version 3 to include the additional columns from Customer3.json.

Upon opening the version 2 schema struct file, notice that it includes the new columns from Customer3.json.
v1
{"dataSchemaJson":"{\"type\":\"struct\",\"fields\":[{\"name\":\"FirstName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"LastName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"MiddleName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"Title\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"customerid\",\"type\":\"long\",\"nullable\":true,\"metadata\":{}},{\"name\":\"CompanyName\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"EmailAddress\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"SalesPerson\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"namestyle\",\"type\":\"boolean\",\"nullable\":true,\"metadata\":{}},{\"name\":\"ModifiedDate\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"Phone\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"rowguid\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionSchemaJson":"{\"type\":\"struct\",\"fields\":[]}"}
Summary
In this article, I demonstrated how to configure and run Autoloader in Azure Databricks by using the cloudFiles source. Specifically, you learned how to manage advanced schema evolution capabilities for streaming semi-structured JSON data. This modern streaming architectural pattern can be considered while building the Lakehouse architecture since it also supports writing the stream to a Delta format. It can be used for both streaming and batch ELT workload processing paradigms since the cluster will shut down when there are no files in the queue to process and will restart when new files arrive in the queue. Additionally, the ease of management and maintenance of Event grid subscriptions and topics demonstrate Auto Loader's capabilities in the modern Data and Analytics platform, specifically as it relates to the Lakehouse Paradigm.
Next Steps
- Read more about how to incrementally Load Azure Synapse Analytics using Auto Loader within Databricks.
- Read more about how to Format Query Results as JSON with FOR JSON - SQL Server | Microsoft Docs
- To learn more about the Data Lakehouse Paradigm, read What is a Data Lakehouse? - Databricks
- For more information on Auto Loader, read Load files from S3 using Auto Loader | Databricks on AWS






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-03-29
