By: Edwin Sarmiento | Updated: 2021-10-19 | Comments | Related: > Availability Groups
Problem
In a previous tip on Configure Distributed Availability Groups for SQL Server Disaster Recovery with Failover Clustering, we have seen how to configure a Distributed Availability Group as a disaster recovery strategy for SQL Server failover clustered instances. What do I need to do on the Distributed Availability Group in case I need to perform maintenance on the replicas of the primary Availability Group?
Solution
There are cases when you need to perform a manual failover between the SQL Server failover clustered instances (FCIs) in an Availability Group (AG), for example, replacing or upgrading the shared storage. Keep in mind that only manual failover is supported when SQL Server FCIs are configured as AG replicas.
However, when you have a Distributed AG as part of your disaster recovery strategy, you need to update the configuration whenever you perform a manual failover on the primary or secondary AG. Refer to the diagram below configured in the previous tip.
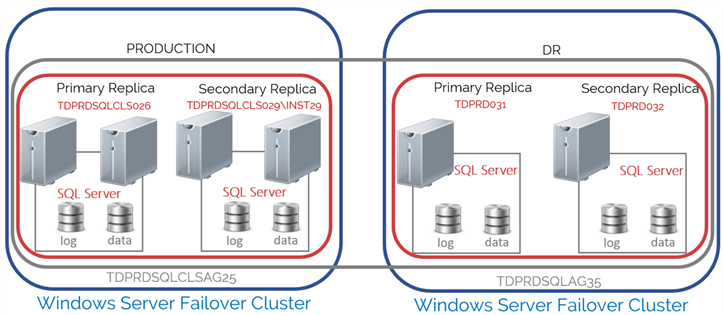
Below are the details of the implementation for the configuration:
| Production | DR | |
| WSFC | OS: Windows Server 2019 | OS: Windows Server 2019 |
| Nodes: TDPRD021, TDPRD022, TDPRD027, and TDPRD028 | Nodes: TDPRD031 and TDPRD032 | |
| Cluster Name Object (CNO): TDPRDCLS024 | Cluster Name Object (CNO): TDPRDCLS034 | |
| IP Subnet: 172.16.0.0/16 | IP Subnet: 192.168.0.0/24 | |
| SQL Server Instance 1 | Virtual Network Name (VNN): TDPRDSQLCLS026 | TDPRD031 |
| SQL Server Instance 2 | Virtual Network Name (VNN) : TDPRDSQLCLS029\INST29 | TDPRD032 |
| SQL Server service account | TESTDOMAIN\sqlservice | TESTDOMAIN\sqlservice |
| Availability Group | Name: TDPRDSQLCLSAG25 | Name: TDPRDSQLAG35 |
| Listener: TDPRDSQLCLSAG25 | Listener: TDPRDSQLAG35 | |
| Distributed Availability Group Name: DistAG_DC1_DC2 | ||
If you need to replace the shared storage (or perform any maintenance) on TDPRDSQLCLS026, you need to move the primary AG (TDPRDSQLCLSAG25) to TDPRDSQLCLS029\INST29 before doing any maintenance. This will make sure that the databases are still highly available while performing maintenance on TDPRDSQLCLS026.
Here’s a high-level overview of the steps for your reference.
- Failover the primary AG (TDPRDSQLCLSAG25) to the secondary replica (TDPRDSQLCLS029\INST29)
- Update the Distributed AG (DistAG_DC1_DC2) on the primary AG (TDPRDSQLCLSAG25)
- Update the Distributed AG (DistAG_DC1_DC2) on the secondary AG (TDPRDSQLAG35)
Step #1: Failover the primary AG (TDPRDSQLCLSAG25) to the secondary replica (TDPRDSQLCLS029\INST29)
Refer to this tip on how to manually failover an AG. Make sure that the secondary replica is failover ready before proceeding to avoid data loss.
Step #2: Update the Distributed AG (DistAG_DC1_DC2) on the primary AG (TDPRDSQLCLSAG25)
Since the SQL Server VNN – not instance name nor AG listener name - is used for the LISTENER_URL parameter when creating the Distributed AG involving the primary AG, the secondary AG (TDPRDSQLAG35) will no longer be able to communicate with the primary AG (TDPRDSQLCLSAG25) after performing a manual failover to the secondary replica (TDPRDSQLCLS029\INST29). That’s because the SQL Server VNN only exists within the context of the SQL Server FCI, not the AG. The secondary AG (TDPRDSQLAG35) will immediately report an error stating that it could not connect to the primary AG (TDPRDSQLCLSAG25). SQL Server will log an error message on the primary replica (TDPRD031) of the secondary AG (TDPRDSQLAG35) similar to the one below.
The dashboard of the secondary AG (TDPRDSQLAG35) will immediately report the same. Don’t be alarmed.
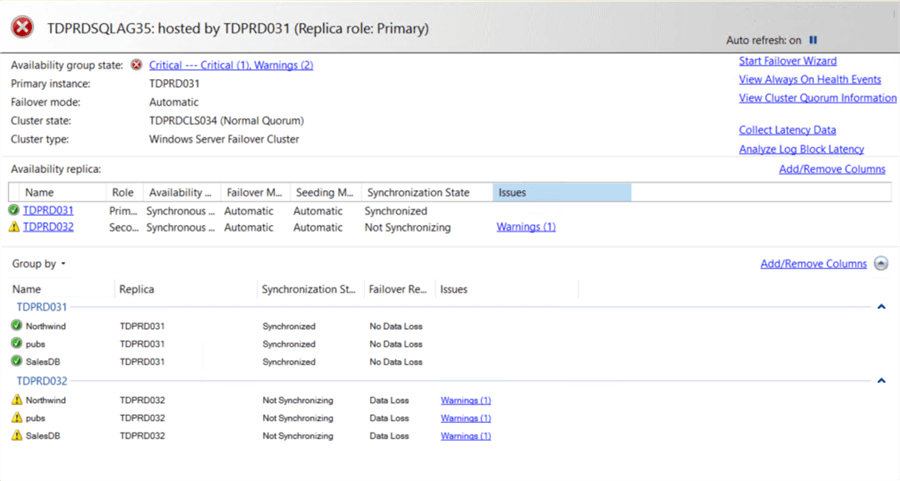
NOTE: A common mistake when you get an alert about the health of an AG is to assume that there is something wrong with it without considering whether or not it is a part of a Distributed AG. I’ve worked on cases where DBAs and sysadmins would troubleshoot an AG for hours – even days - without realizing there’s nothing wrong with it. Start with looking at the bigger picture first before digging deeper. In this case, the AG being a part of a Distributed AG is what caused the error, not the AG itself. This issue resolve itself once the Distributed AG has been updated with the new LISTENER_URL parameter value.
Use the T-SQL script below to update the Distributed AG (DistAG_DC1_DC2) on the primary AG (TDPRDSQLCLSAG25). Be sure you are connected to the primary replica of the primary AG.
NOTE: Use SQLCMD mode when running the T-SQL scripts to make sure you are connected to the correct SQL Server instance.
--Run this on the primary replica of the primary Availability Group
:CONNECT TDPRDSQLCLS029\INST29
USE [master]
GO
ALTER AVAILABILITY GROUP [DistAG_DC1_DC2]
MODIFY AVAILABILITY GROUP ON
'TDPRDSQLCLSAG25' WITH
(
LISTENER_URL = 'TCP://TDPRDSQLCLS029.TESTDOMAIN.COM:5022'
)
I highlighted the new LISTENER_URL parameter value as the SQL Server VNN of TDPRDSQLCLS029\INST29.
Step #3: Update the Distributed AG (DistAG_DC1_DC2) on the secondary AG (TDPRDSQLAG35)
Once the Distributed AG has been updated on the primary AG, you can now proceed to update the Distributed AG on the secondary AG. Use the T-SQL script below to update the Distributed AG (DistAG_DC1_DC2) on the secondary AG (TDPRDSQLAG35). Be sure you are connected to the primary replica of the secondary AG.
--Run this on the primary replica of the secondary Availability Group
:CONNECT TDPRD031
USE [master]
GO
ALTER AVAILABILITY GROUP [DistAG_DC1_DC2]
MODIFY AVAILABILITY GROUP ON
'TDPRDSQLCLSAG25' WITH
(
LISTENER_URL = 'TCP://TDPRDSQLCLS029.TESTDOMAIN.COM:5022'
)
Once the Distributed AG has been updated with the new LISTENER_URL parameter value of the primary AG, the secondary AG will automatically resume connectivity and data replication. SQL Server will log a message on the primary replica (TDPRD031) of the secondary AG (TDPRDSQLAG35) similar to the one below.
The dashboard on the secondary AG will also report a healthy status once the connectivity is resumed. No need to do anything after this.
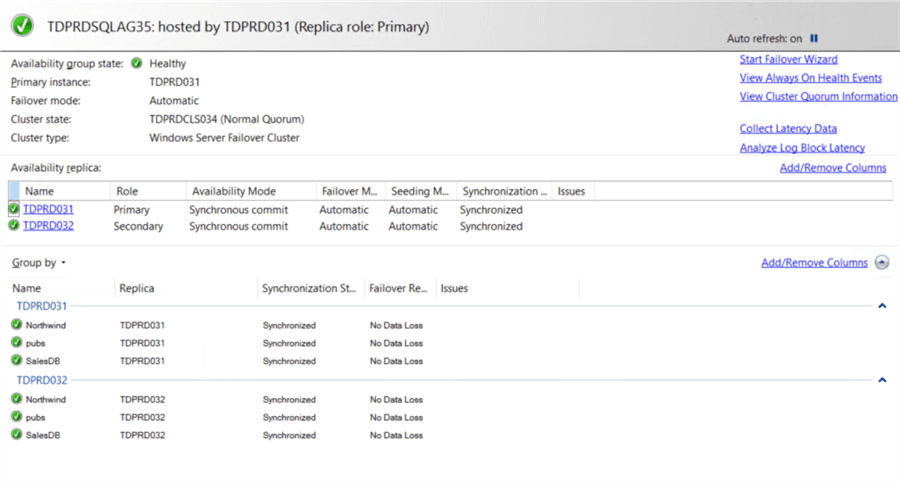
This process needs to be done every time you perform a manual failover between AG replicas involving SQL Server FCIs. Be sure to include this in your change management process to meet your DR recovery objectives.
Next Steps
- Review the previous tips on SQL Server Always On Availability Group Configuration
- SQL Server Always On Availability Groups - Part 1 configuration
- SQL Server Always On Availability Groups - Part 2 Availability Groups Setup
- Multi-Site Multi-Cluster SQL Server Installation with Clustering and Availability Groups
- Setup and Implement SQL Server 2016 Always On Distributed Availability Groups
- Read about the following topics from the Microsoft Documentation






About the author
 Edwin M Sarmiento is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures.
Edwin M Sarmiento is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-10-19
