By: Aaron Bertrand | Updated: 2021-10-22 | Comments (2) | Related: > TSQL
Problem
I have long advocated avoiding splitting strings by using table-valued parameters (TVPs), but this is not always a valid option; for example, PHP drivers do not handle this feature yet. A new pattern I've seen emerging is to replace splitting comma-separated strings with the new OPENJSON functionality introduced in SQL Server 2016. I wanted to explore why this is not an improvement in the typical case, unless you are using a client application platform that doesn't support TVPs and your application data already happens to be in JSON format.
Solution
To explore the performance characteristics of various approaches, let's
create a database, a table with 10 million rows, a TVP to handle a set of
bigint values, and a custom table-valued function
to split. I used an XML-based splitter for simplicity, but any Table Valued
Function (TVF) you are using
will be suitable for comparison.
This took under a minute on my system:
CREATE DATABASE StringStuff;
GO USE StringStuff;
GO CREATE TABLE dbo.Customers
(
CustomerID bigint IDENTITY(1,1),
CustomerName nvarchar(256),
Filler char(128) NOT NULL DEFAULT '',
CONSTRAINT PK_Customers PRIMARY KEY (CustomerID)
);
GO INSERT dbo.Customers(CustomerName)
SELECT TOP (10000000) o.name
FROM sys.all_objects AS o CROSS JOIN sys.all_columns
ORDER BY NEWID();
GO EXEC sys.sp_spaceused @objname = N'dbo.Customers';
GO CREATE TYPE dbo.BigInts AS TABLE(value bigint PRIMARY KEY);
GO CREATE FUNCTION dbo.SplitBigints(@List varchar(max)) RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT value = CONVERT(bigint, y.i.value(N'(./text())[1]', N'varchar(32)')) FROM ( SELECT x = CONVERT(xml,'<i>'+REPLACE(@List,',','</i><i>')+'</i>').query('.') ) AS a CROSS APPLY x.nodes('i') AS y(i) ); GO
Output:

As a brief review, let's take a quick look at the most common methods you
might use to match all the rows to a list a user has provided. We'll start
with the new OPENJSON approach, then the native
STRING_SPLIT, then a custom table-valued function
that outputs a bigint, then the linear parameters
method an ORM like nHibernate will often generate, and finally the TVP approach.
I'll also show the plans and relevant estimates:
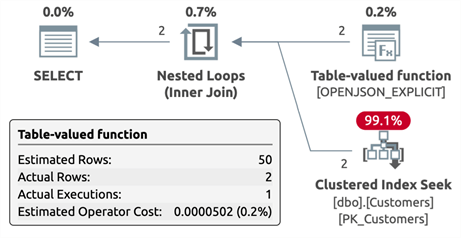
JSON
DECLARE @CustomersJSON varchar(max) = '[{"cust_id": "32"}, {"cust_id": "902954"}]';
SELECT /* json */ c.CustomerID, c.CustomerName
FROM dbo.Customers AS c
INNER JOIN OPENJSON(@CustomersJSON) WITH (value bigint N'$.cust_id') AS j
ON c.CustomerID = j.value;
Plan:
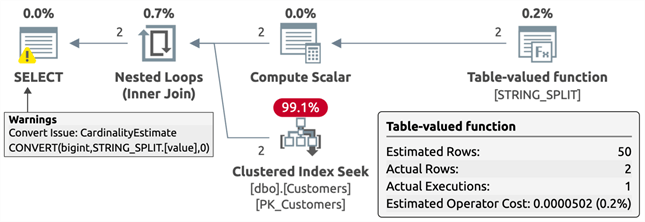
STRING_SPLIT
DECLARE @CustomersCSV varchar(max) = '32, 902954'; SELECT /* split */ CustomerID, CustomerName
FROM dbo.Customers AS c
INNER JOIN STRING_SPLIT(@CustomersCSV, ',') AS s
ON c.CustomerID = CONVERT(bigint, s.value);
Plan:
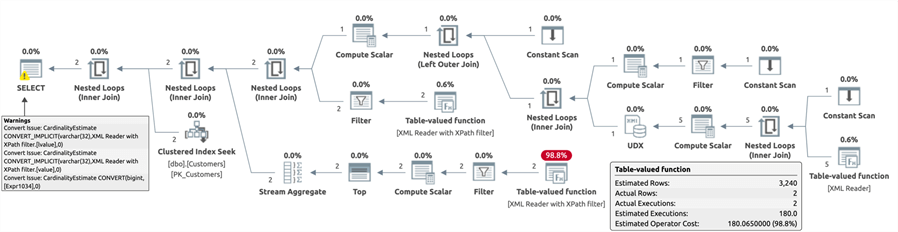
Custom TVF
DECLARE @CustomersCSV varchar(max) = '32, 902954'; SELECT /* TVF */ CustomerID, CustomerName
FROM dbo.Customers AS c
INNER JOIN dbo.SplitBigints(@CustomersCSV) AS s
ON c.CustomerID = s.value;
Plan:
ORM-style
DECLARE @sql nvarchar(max) = N'SELECT /* ORM */ CustomerID, CustomerName
FROM dbo.Customers
WHERE CustomerID IN (@p1, @p2);'; EXEC sys.sp_executesql @sql,
@params = N'@p1 int, @p2 int',
@p1 = 32, @p2 = 902954;
Plan:
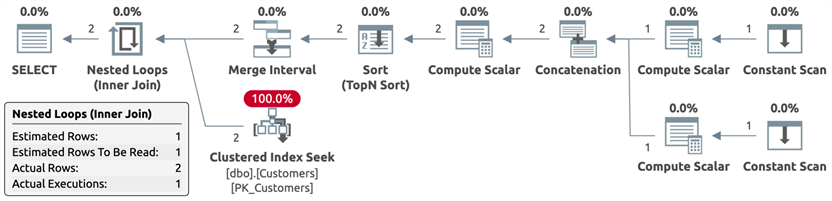
TVP
DECLARE @tvp dbo.BigInts;
INSERT @tvp(value) VALUES(32),(902954); SELECT /* tvp */ c.CustomerID, c.CustomerName
FROM dbo.Customers AS c
INNER JOIN @tvp AS t ON c.CustomerID = t.value;
Plan:
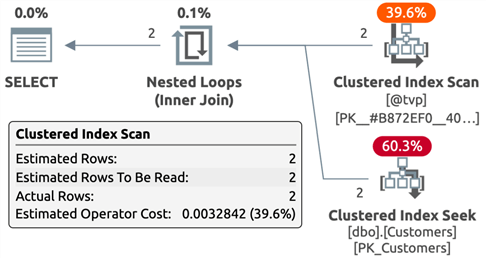
It's useful to note that only the TVP plan estimated the correct number of rows, but that comes at a cost we'll talk about shortly. It's also useful to note that, while a conversion warning is presented in the STRING_SPLIT plan, this same conversion has to happen somewhere in the bowels of the JSON function, too. Finally, the TVF has by far the most complicated plan, partly due to using XML functions, and this leads to terrible estimates. Feel free to experiment with your favorite splitting function(s).
In my case, these all generated the following output (your values will be different,
since the original table population will vary based on NEWID()):
More importantly, the answer is always the same in all four examples. This is fine for manually defining a few specific CustomerID values, but our tests will require more. To generate the type of output we need to set up some queries with, say, 100 identical parameter values, we can do this:
SELECT TOP (100) v = CONVERT(varchar(11), CustomerID)
INTO #x
FROM dbo.Customers ORDER BY NEWID(); SELECT jsonList = N'[' + STRING_AGG('{"cust_id": "' + v + '"}', ',') + N']' FROM #x; SELECT csvList = STRING_AGG(v, ', ') FROM #x; SELECT tokens = STRING_AGG('@p' + p, ', '),
params = STRING_AGG('@p' + p + ' bigint', ', '),
vals = STRING_AGG('@p' + p + ' = ' + v, ', ')
FROM (SELECT v, p = CONVERT(varchar(11), ROW_NUMBER() OVER (ORDER BY @@SPID)) FROM #x) AS x; SELECT tvpList = 'VALUES' + STRING_AGG('(' + v + ')', ',') + ';' FROM #x;
The output will look something like this, and we can copy each of those values into a template that will run all the test queries with the exact same set of parameters:
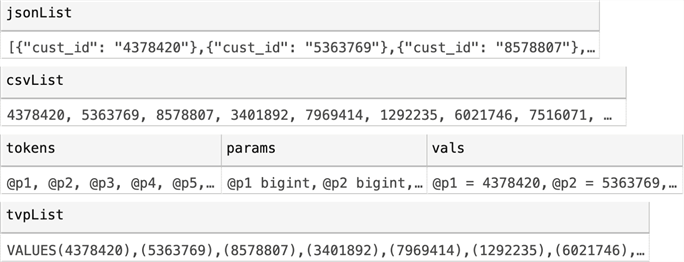
Now, before we start getting serious, let's turn on Query Store to let the system handle measuring the performance of the various queries we'll be generating:
ALTER DATABASE StringStuff SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 1),
DATA_FLUSH_INTERVAL_SECONDS = 60,
INTERVAL_LENGTH_MINUTES = 1,
SIZE_BASED_CLEANUP_MODE = AUTO,
QUERY_CAPTURE_MODE = ALL /* NOTE: not recommended in production! */
);
Note: QUERY_CAPTURE_MODE = ALL is for demo and
testing purposes only; in real scenarios you either want to use
AUTO or the new CUSTOM
added to SQL Server 2019 (Erin Stellato talks about this option
here).
Once Query Store is enabled, we can populate the following template manually with our output from above, and let it rip. The big difference here is I use a variable to assign the value – the queries still read all of the data, but the time a slow applications takes to consume and render the results are taken out of the equation.
SET NOCOUNT ON;
ALTER DATABASE StringStuff SET QUERY_STORE CLEAR;
GO /* ----- JSON ----- */ DECLARE @c nvarchar(256),
@CustomersJSON varchar(max) = '/* jsonList */'; SELECT /* 100 : json */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN OPENJSON(@CustomersJSON) WITH (value bigint N'$.cust_id') AS j
ON c.CustomerID = j.value;
GO 200 /* ----- STRING_SPLIT ----- */ DECLARE @c nvarchar(256),
@CustomersCSV varchar(max) = '/* csvList */'; SELECT /* 100 : split */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN STRING_SPLIT(@CustomersCSV, ',') AS s
ON c.CustomerID = CONVERT(bigint, s.value);
GO 200 /* ----- TVF ----- */ DECLARE @c nvarchar(256),
@CustomersCSV varchar(max) = '/* csvList */'; SELECT /* TVF */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN dbo.SplitBigints(@CustomersCSV) AS s
ON c.CustomerID = s.value;
GO 200 /* ----- ORM-style ----- */ DECLARE @sql nvarchar(max) = N'SELECT /* 100 : ORM */ @c = c.CustomerName
FROM dbo.Customers AS c
WHERE c.CustomerID IN (/* tokens */);'; EXEC sys.sp_executesql @sql,
@params = N'@c nvarchar(256), /* params */',
@c = NULL, /* vals */;
GO 200 /* ----- TVP ----- */ DECLARE @c nvarchar(256), @tvp dbo.BigInts;
INSERT @tvp(value) /* tvpList */; SELECT /* 100 : TVP */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN @tvp AS t ON c.CustomerID = t.value;
GO 200
The end result in my case was (values truncated for readability!):
DECLARE @c nvarchar(256),
@CustomersJSON varchar(max) = '[{"cust_id": "4378420"},{"cust_id": "5363769”}, … 96 more … ,{"cust_id": "7050535"},{"cust_id": "9105909"}]'; SELECT /* 100 : json */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN OPENJSON(@CustomersJSON) WITH (value bigint N'$.cust_id') AS j
ON c.CustomerID = j.value;
GO 200 /* ----- STRING_SPLIT ----- */ DECLARE @c nvarchar(256),
@CustomersCSV varchar(max) = '4378420, 5363769, … 96 more … , 7050535, 9105909'; SELECT /* 100 : split */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN STRING_SPLIT(@CustomersCSV, ',') AS s
ON c.CustomerID = CONVERT(bigint, s.value);
GO 200 /* ----- TVF ----- */ DECLARE @c nvarchar(256),
@CustomersCSV varchar(max) = '4378420, 5363769, … 96 more … , 7050535, 9105909'; SELECT /* 100 : TVF */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN dbo.SplitBigints(@CustomersCSV) AS s
ON c.CustomerID = s.value;
GO /* ----- ORM-style ----- */ DECLARE @sql nvarchar(max) = N'SELECT /* 100 : ORM */ @c = c.CustomerName
FROM dbo.Customers AS c
WHERE c.CustomerID IN (@p1, @p2, … 96 more … , @p99, @p100);'; EXEC sys.sp_executesql @sql,
@params = N'@c nvarchar(256), @p1 bigint, @p2 bigint, … 96 more … , @p99 bigint, @p100 bigint',
@c = NULL, @p1 = 4378420, @p2 = 5363769, … 96 more … , @p99 = 7050535, @p100 = 9105909;
GO /* ----- TVP ----- */ DECLARE @c nvarchar(256), @tvp dbo.BigInts;
INSERT @tvp(value) VALUES(4378420),(5363769), … 96 more … ,(7050535),(9105909); SELECT /* 100 : TVP */ @c = c.CustomerName
FROM dbo.Customers AS c
INNER JOIN @tvp AS t ON c.CustomerID = t.value;
GO
And then I looked at the data in Query Store to see about query duration, memory usage, and compilations:
SELECT
query = SUBSTRING(query_sql_text, CHARINDEX(N'SELECT /*', query_sql_text), 32),
compiles = p.count_compiles,
executions = rs.count_executions,
rs.avg_duration,
avg_memory = rs.avg_query_max_used_memory
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE qt.query_sql_text LIKE N'%/*%*/%'
AND qt.query_sql_text NOT LIKE N'%sys.query_store%'
ORDER BY q.query_text_id;
Results:
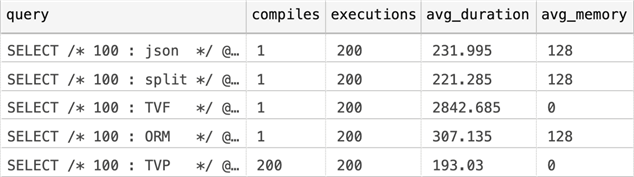
TVP came out on top, both in terms of duration and memory usage, and the cost
I alluded to earlier – high compilations – did not have a measurable
impact. The custom TVF was the worst, to the surprise of nobody, surely. It
was a surprise, though, that JSON was only beat out by
STRING_SPLIT by a little bit, and that the ORM-style
query was not far behind, either.
I repeated with 10, 50, and 200 values, and saw very similar patterns: TVP always the winner, TVF always the dog, and the other three were relatively equal.
Conclusion
If you can't use TVPs, the new OPENJSON pattern
isn't quite as bad as I originally thought. That said, if you are
taking a set (or an existing CSV value) in your application and building a (much
bigger) JSON string only to break it apart using OPENJSON,
you need to keep in mind that extra work your application is doing, and the additional
data being passed over the wire – neither of which Query Store can track.
If your data is already in JSON format, I think that using the new approach is fine,
but if you do have TVP support, it really deserves a look.
Next Steps
See these tips and other resources involving splitting strings and JSON:
- Solve old problems with SQL Server's new STRING_AGG and STRING_SPLIT functions
- SQL Server STRING SPLIT Limitations
- Dealing with the single-character delimiter in SQL Server's STRING_SPLIT function
- SQL Server Split String Replacement Code with STRING_SPLIT
- Splitting Strings : Now with less T-SQL
- Using Table Valued Parameters (TVP) in SQL Server
- JSON Support in SQL Server 2016
- Advanced JSON Techniques in SQL Server – Part 1 | Part 2 | Part 3






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-10-22
