By: Andrea Gnemmi | Updated: 2021-10-12 | Comments | Related: > SQL Server vs Oracle vs PostgreSQL Comparison
Problem
SQL string functions are widely used to manipulate, extract, format and search text for char, nchar (unicode), varchar, nvarchar (unicode), etc. data types. Unfortunately, there are some differences with the SQL functions between SQL Server, Oracle and PostgreSQL which we will cover in this article.
Solution
In this tip we will review some of the basic string functions, the various possibilities, best practices and differences on doing operations with strings in SQL Server, Oracle and PostgreSQL.
As always, we will use the github freely downloadable database sample Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for the data structure and inserts statements for the data.
SQL String Functions to Concatenate Strings
The first, easiest and most common operation, in my opinion, is the concatenation of two (or more) strings, so let's see various methods to do so!
SQL Server
In order to concatenate strings with T-SQL in SQL Server there are basically two methods, the first is to use the concatenate operator + as in this example we want to have First Name and Last Name of our customers returned in one column:
select FirstName + ' ' + LastName as CustomerName from Customer
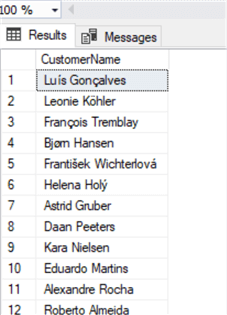
Easily done, along with adding a space in the middle.
The same result can be obtained using the function CONCAT using a comma separator between each string value:
select concat(FirstName,' ',LastName) as CustomerName from Customer
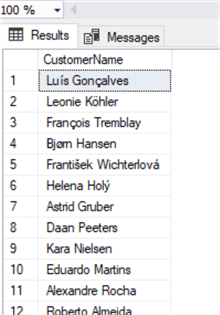
Note that in the CONCAT syntax you separate the strings with a comma. Very easy.
Check out these related tutorials:
- Multiple Ways to Concatenate Values Together in SQL Server
- Concatenation of Different SQL Server Data Types
- Concatenate SQL Server Columns into a String with CONCAT()
- New FORMAT and CONCAT Functions in SQL Server 2012
- SQL CONCAT_WS Function
Oracle
In Oracle the concatenation operator is a double pipe ||:
select Firstname||' '||LastName as CustomerName from chinook.customer;
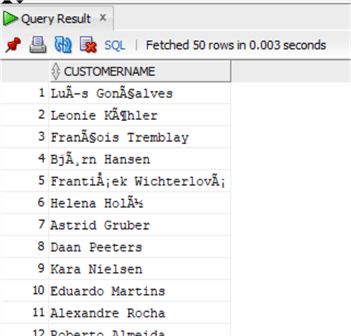
In Oracle the function CONCAT can only be used with two strings, so the following does not work:
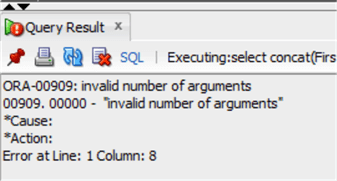
select concat(FirstName,' ',LastName) as CustomerName from chinook.customer;
We end up with an error:
But this will work:
select concat(FirstName,LastName) as CustomerName from chinook.customer;
And this is the result:
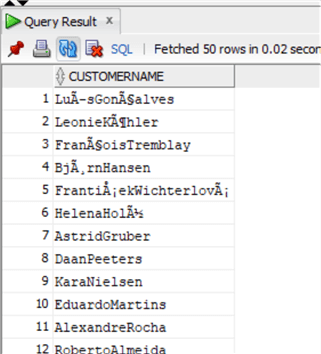
PostgreSQL
In PostgreSQL the concatenation operator is the same as in Oracle:
select "FirstName"||' '||"LastName" as "CustomerName" from "Customer"
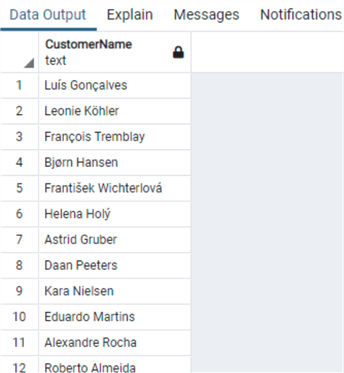
And in PostgreSQL, CONCAT works as in SQL Server:
select concat("FirstName",' ',"LastName") as "CustomerName"
from "Customer"
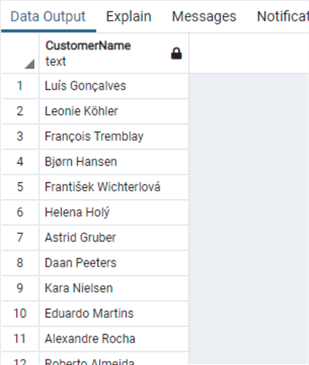
SQL String Functions for Substring
Another typical operation is to extract some part of a string. For example, let's imagine that we need to extract the initial of every Firstname and combine it with '.' and Lastname for every customer:
SQL Server
In SQL Server we use the function SUBSTRING:
select substring(FirstName,1,1) + '. ' + LastName as CustomerName from Customer
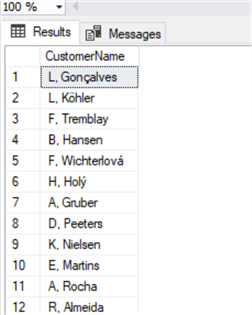
Quite easy, the SUBSTRING function accepts the string as the first parameter, the starting point of the string as the second and the third is how many characters we need to extract.
The same results above can be achieved using the LEFT function as follows:
select left(FirstName,1) + '. ' + LastName as CustomerName from Customer
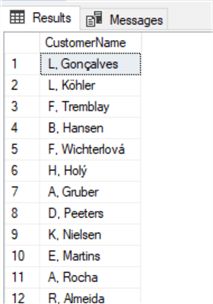
The LEFT function starts at the left of the string for X amount of characters of the string.
Obviously, there is also a RIGHT function. Let's suppose that we need to extract all the customers with names ending with a vowel:
select customerid, FirstName + ' ' + LastName as CustomerName
from Customer
where right(FirstName,1) in ('a','e','i','o','u')
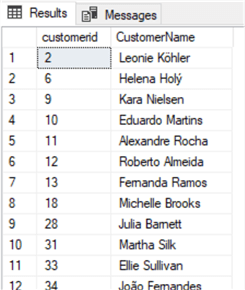
Oracle
In Oracle, the function is similar, although with a slightly different name, SUBSTR:
select substr(FirstName,1,1)||'. '||LastName as CustomerName from chinook.Customer;
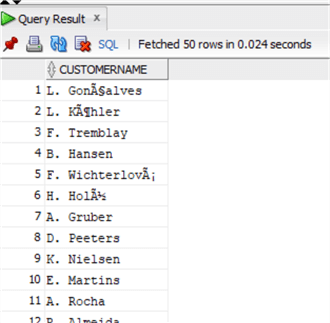
The syntax is exactly the same as in SQL Server, just the name of the function is slightly different.
Unfortunately, in Oracle PL/SQL there is no LEFT or RIGHT functions so we will end up always using SUBSTR to extract strings.
PostgreSQL
In PostrgeSQL the function is SUBSTRING like in SQL Server:
select substring("FirstName",1,1)||'. '||"LastName" as "CustomerName"
from "Customer"
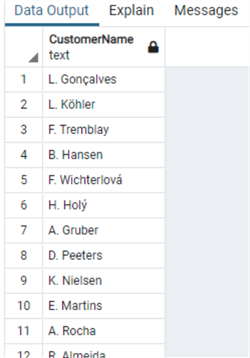
We can also use the LEFT function:
select left("FirstName",1)||'. '||"LastName" as "CustomerName"
from "Customer"
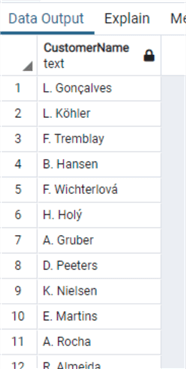
And use the RIGHT function:
select "CustomerId", "FirstName"||' '||"LastName" as "CustomerName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')
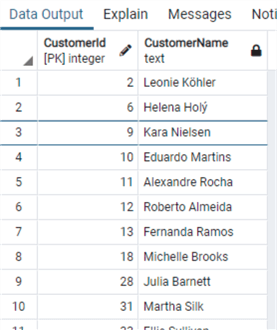
Trim Leading and Trailing Spaces from a String
A similar feature to LEFT and RIGHT function are LTRIM and RTRIM, these are used to delete all spaces from the left or right of the given string. These are often used in data cleansing, so in data warehouse ETL I encountered it a lot.
SQL Server
First, we'll mess up the data by adding some spaces at the beginning of the FirstName column in all some rows:
update Customer
set FirstName = ' ' + FirstName
where right(FirstName,1) in ('a','e','i','o','u')
Let's see how the data looks now:
select FirstName
from Customer
where right(FirstName,1) in ('a','e','i','o','u')
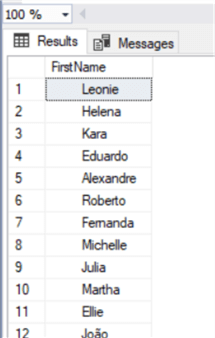
As expected, there are some spaces at the beginning of each FirstName.
So now we'll clean the data:
update Customer
set FirstName = ltrim(FirstName)
where right(Firstname,1) in ('a','e','i','o','u')
Now we can check the data again:
select FirstName
from Customer
where right(FirstName,1) in ('a','e','i','o','u')
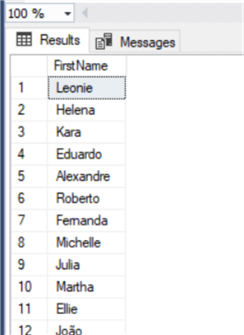
We can do the same thing with RTRIM to remove the space on the right of the string.
In SQL Server 2017 and onwards, we can remove spaces from the left and right at the same time using the TRIM function.
So, let's mess up the data again and add some spaces, this time to all rows in the table:
update Customer set FirstName= ' ' + FirstName + ' '
Let's see our data now:
select FirstName from Customer
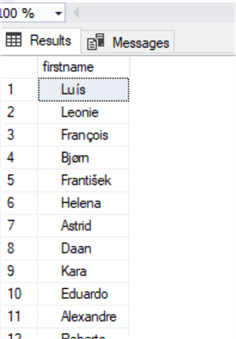
Let's clean it up using TRIM:
update Customer set FirstName = trim(FirstName)
And let's take a look now:
select firstName from Customer
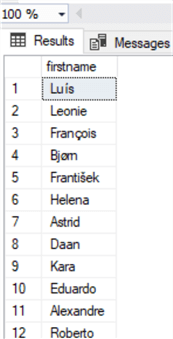
Oracle
In Oracle we have the exact same functions, so let's first mess up our data:
update chinook.Customer
set FirstName=' '||FirstName
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
You notice that since we do not have the RIGHT function in Oracle, we must use a little workaround with the help of the LENGTH function that, guess what, returns the length value in number of characters of the string. This same function also exists in SQL Server and PostgreSQL, although in SQL Server is called LEN. Then using this number as the start point for the SUBSTR we are able to retrieve the last character of the string.
Let's take a look to the data:
select firstname from chinook.Customer;
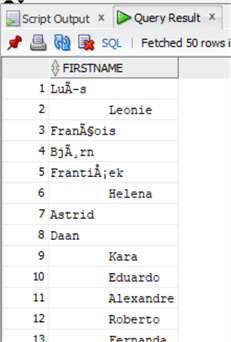
Now let's clean it up with LTRIM:
update chinook.Customer
set FirstName=ltrim(FirstName)
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
And we'll take a look to the data again:
select FirstName from chinook.Customer;
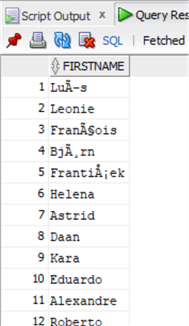
Now let's mess up the data again for the TRIM function:
update chinook.Customer set FirstName=' '||FirstName||' '; commit;
Then we'll take a look:
select FirstName from chinook.Customer;
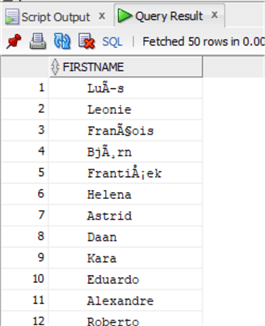
And now let's clean it up:
update chinook.Customer set FirstName=trim(FirstName); commit;
and the data are now fine again:
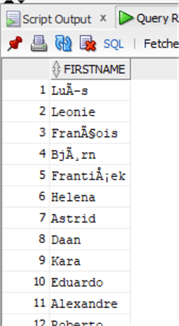
Note that in Oracle there is a difference as the TRIM, LTRIM and RTRIM functions can be used to remove other specified characters, not only spaces as in SQL Server. Let's do an example adding some characters at the beginning of the column first name:
update chinook.Customer
set FirstName='... '||FirstName
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
Let's take a look at the data now:
select FirstName
from chinook.Customer
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
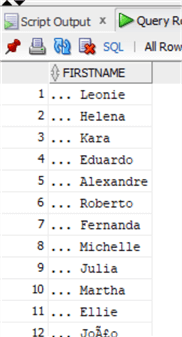
And now we clean it up using the LTRIM function:
update chinook.Customer
set FirstName=ltrim(FirstName,'. ')
where substr(FirstName,length(FirstName),1) in ('a','e','i','o','u');
commit;
Our data are back to the previous look:
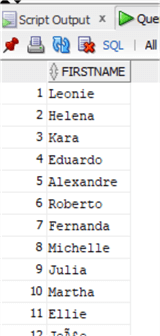
Pay attention that all the TRIM functions, for every character in the set, remove the right-most or left-most occurrences of each from the string. That is why if you noticed I put just one dot in the LTRIM:
set FirstName=ltrim(FirstName,'. ')
PostgreSQL
In PostgreSQL we have the same functions with the same syntax and meaning.
Let's start with messing our data:
update "Customer"
set "FirstName"=' '||"FirstName"
where right("FirstName",1) in ('a','e','i','o','u')
Taking a look at what we have now inside the table:
select "FirstName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')
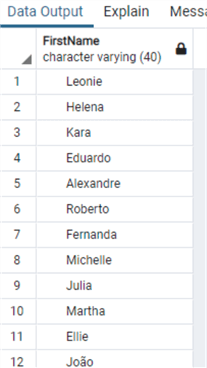
And now we clean it up with LTRIM:
update "Customer"
set "FirstName"=ltrim("FirstName")
where right("FirstName",1) in ('a','e','i','o','u')
Let's take a look again at the data now:
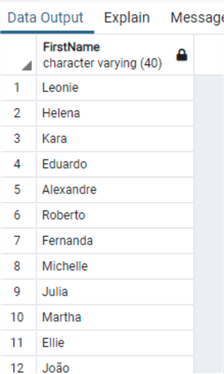
LTRIM and RTRIM work exactly the same way, but here we have the possibility like in Oracle to remove other characters instead of the default space, let's do the same test we did in Oracle:
update "Customer"
set "FirstName"='... '||("FirstName")
where right("FirstName",1) in ('a','e','i','o','u')
and see the data:
select "FirstName"
from "Customer"
where right("FirstName",1) in ('a','e','i','o','u')
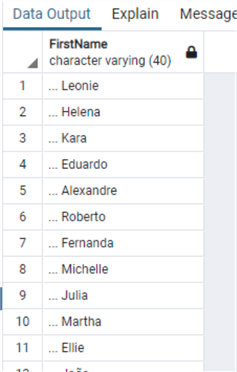
Now let's clean it up:
update "Customer"
set "FirstName"=ltrim("FirstName", '. ')
where right("FirstName",1) in ('a','e','i','o','u')
and see how they are now:
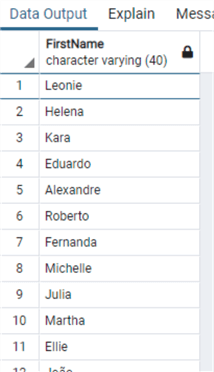
Replacing Text in a String
Another useful function in manipulating strings is REPLACE, as the name suggests it can be used to replace a specified string with another.
Let's do an example: let's imagine that we need to replace, in column Company, the word "Inc." with "Co.".
SQL Server
This task can be easily done using the function REPLACE, let's take a look to the data first:
SELECT customerid, Company FROM Customer where Company is not null
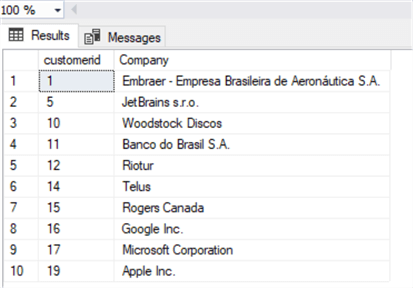
Now let's update it:
update Customer set Company = replace(Company, 'Inc.','Co.') where Company is not null
And we can see the modifications:
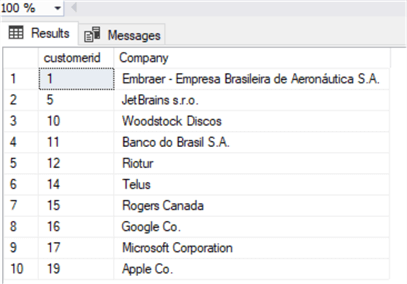
Easily done!
Oracle
The same functionality is in Oracle, let's check the data first:
SELECT customerid, Company FROM chinook.Customer where Company is not null;
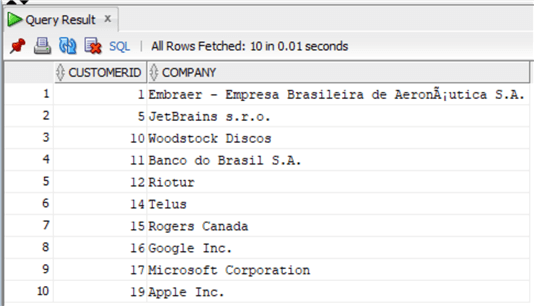
And now the REPLACE:
update chinook.customer set Company=replace(Company, 'Inc.','Co.') where Company is not null; commit;
Then we can look at the data again:
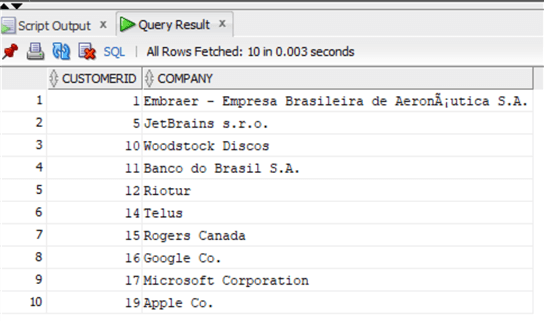
PostgreSQL
Now PostgreSQL:
SELECT "CustomerId", "Company" FROM "Customer" where "Company" is not null order by "CustomerId"
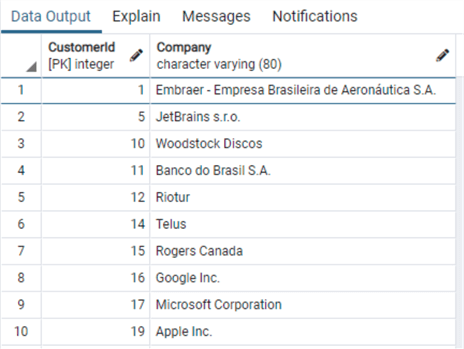
Please note that I needed to add an order by to have the customers in the same order as in the other two RDBMS.
Let's use REPLACE:
update "Customer"
set "Company"=replace("Company", 'Inc.','Co.')
where "Company" is not null
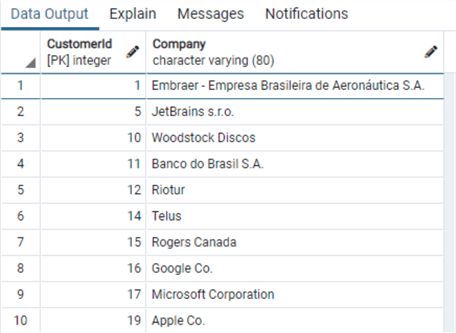
And a final look at the data:
Next Steps
- We have learned in this tip some of the functions related with manipulating strings in all 3 RDBMS, there are more functions, but these are by far the most used and the ones that you'll absolutely need to know.
- As usual links to the official documentation:
- SQL Server: String Functions (Transact-SQL)
- Oracle: String Functions
- PostgreSQL: String Functions and Operators
- Some links to other tips regarding string functions:
- SQL Server Split String Replacement Code with STRING_SPLIT
- Concatenate SQL Server Columns into a String with CONCAT()
- Split Delimited String into Columns in SQL Server with PARSENAME
- SQL Server Text Data Manipulation for charindex, soundex, lowercase, uppercase, rtrim, ltrim, replace, right, reverse and more functions






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-10-12
