By: Aaron Bertrand | Updated: 2021-11-08 | Comments (9) | Related: > TSQL
Problem
Last year, I wrote about
replacing all your CLR or custom string splitting functions with native calls
to STRING_SPLIT. As I work on a project migrating
several Microsoft SQL Server instances to Linux, I am encountering one of the roadblocks I
mentioned last time: the need to provide an element in the output to indicate the
order of the elements in the input string. This means STRING_SPLIT
in its current form is out, because 1) it offers no such column; and, 2) the results
are not guaranteed to be returned in any specific order. Are there other ways to
achieve this functionality at scale and without CLR?
Solution
In my previous article, I mentioned a table-valued function as a potential workaround to provide an ordinal marker for each element in a string. But before we start, let's create a new database with a T-SQL command, before a bunch of these functions get accidentally created in master. Here is the syntax:
CREATE DATABASE ABStrings;
GO USE ABStrings;
GO
And let's review some notes about the functions we'll be creating today:
- We're limiting the input to 4,000 characters to avoid any performance skew or code changes required due to LOBs; if you need to support strings exceeding 4,000 characters, you'll have to change the functions accordingly and test them thoroughly.
- We're only creating strings with a maximum number of 100 elements,
so we don't have to worry about recursion exhaustion in the recursive
CTE solution. We can't avoid this inside an inline TVF using an
OPTION (MAXRECURSION)hint so, if we have strings containing more than 100 elements and decide for some reason to use a recursive CTE solution, we will need to apply aMAXRECURSIONhint on the outer query that references the function (or create a wrapper multi-statement table-valued function whose only job is to apply the hint). - We're also restricting the delimiter length to 1, both to match
STRING_SPLIT's limitation (and, conveniently, my current requirements), and in some cases this also avoids calculations that require checking the delimiter length. In a couple of spots, it will be non-trivial to support longer delimiters without significant refactoring.
Now, the first function, which uses STRING_SPLIT,
needs ROW_NUMBER() to generate the
seq output. It would be nice if we only had to sort
by pointer, but we need to support picking, say, the
4th element – so we need
a true, gapless sequence:
CREATE OR ALTER FUNCTION dbo.SplitOrdered_Native
(
@List nvarchar(4000),
@Delimiter nchar(1)
)
RETURNS table WITH SCHEMABINDING
AS
RETURN
(
SELECT seq = ROW_NUMBER() OVER (ORDER BY pointer), value
FROM
(
SELECT value,
pointer = CHARINDEX(@Delimiter + value + @Delimiter,
@Delimiter + @List + @Delimiter)
FROM STRING_SPLIT(@List, @Delimiter)
) AS s
);
GO
The problem here is that CHARINDEX will always
evaluate the first instance of the element, and only the first instance,
so it can't handle duplicates accurately. This query:
DECLARE @List nvarchar(4000) = N'one,two,three,two,three';
SELECT seq, value FROM dbo.SplitOrdered_Native(@List, N',') ORDER BY seq;
Produces these (unexpected) results, because the pointers for identical values
end up being the same, so ROW_NUMBER() is just applied
to those two values sequentially before any subsequent row numbers are applied:
seq value
---- -----
1 one
2 two
3 two
4 three
5 three
To get around this, we can make this recursive version instead:
CREATE OR ALTER FUNCTION dbo.SplitOrdered_RecursiveCTE
(
@List nvarchar(4000),
@Delimiter nchar(1)
)
RETURNS table WITH SCHEMABINDING
AS
RETURN
(
WITH a(f,t) AS
(
SELECT 1, CHARINDEX(@Delimiter, @List + @Delimiter)
UNION ALL
SELECT t + 1, CHARINDEX(@Delimiter, @List + @Delimiter, t + 1)
FROM a WHERE CHARINDEX(@Delimiter, @List + @Delimiter, t + 1) > 0
)
SELECT seq = t, value = SUBSTRING(@List, f, t - f) FROM a
);
GO
For the same query:
DECLARE @List nvarchar(4000) = N'one,two,three,two,three';
SELECT seq, value FROM dbo.SplitOrdered_RecursiveCTE(@List, N',') ORDER BY seq;
Results:
seq value
---- -----
4 one
8 two
14 three
18 two
24 three
This produces the correct order, even for the duplicates, though the numbers
aren't contiguous. Since we need the seq value
to represent the explicit ordinal position without gaps, we can change the function
to add a row number over a.t – just keep in
mind that this is not free:
CREATE OR ALTER FUNCTION dbo.SplitOrdered_RecursiveCTE
(
@List nvarchar(4000),
@Delimiter nchar(1)
)
RETURNS table WITH SCHEMABINDING
AS
RETURN
(
WITH a(f,t) AS
(
SELECT 1, CHARINDEX(@Delimiter, @List + @Delimiter)
UNION ALL
SELECT t + 1, CHARINDEX(@Delimiter, @List + @Delimiter, t + 1)
FROM a WHERE CHARINDEX(@Delimiter, @List + @Delimiter, t + 1) > 0
)
SELECT seq = ROW_NUMBER() OVER (ORDER BY t),
value = SUBSTRING(@List, f, t - f) FROM a
);
GO
Results:
seq value
---- -----
1 one
2 two
3 three
4 two
5 three
Problem solved, right?
Well, this solution from Jonathan Roberts certainly looks promising. There are some tweaks here from the original; most notably I removed the multi-character delimiter, as I mentioned above. I just want to be very clear that any performance results should not reflect on the original function or its author, but only on my derivative:
CREATE OR ALTER FUNCTION dbo.SplitOrdered_StackedCTE
(
@List nvarchar(4000),
@Delimiter nchar(1)
)
RETURNS table WITH SCHEMABINDING
AS
RETURN
(
WITH w(n) AS (SELECT 0 FROM (VALUES (0),(0),(0),(0)) w(n)),
k(n) AS (SELECT 0 FROM w a, w b),
r(n) AS (SELECT 0 FROM k a, k b, k c, k d, k e, k f, k g, k h),
p(n) AS (SELECT TOP (COALESCE(LEN(@list), 0))
ROW_NUMBER() OVER (ORDER BY @@SPID) -1 FROM r),
spots(p) AS
(
SELECT n FROM p
WHERE (SUBSTRING(@list, n, 1) LIKE @delim OR n = 0)
),
parts(p,value) AS
(
SELECT p, SUBSTRING(@list, p + 1,
LEAD(p, 1, 2147483647) OVER (ORDER BY p) - p - 1)
FROM spots AS s
)
SELECT seq = ROW_NUMBER() OVER (ORDER BY p),
value
FROM parts
);
GO
Usage:
DECLARE @List nvarchar(4000) = N'one,two,three,two,three';
SELECT seq, value FROM dbo.SplitOrdered_StackedCTE(@List, N',') ORDER BY seq;
Results:
seq value
---- -----
1 one
2 two
3 three
4 two
5 three
And then, just when I thought I had collected all my candidates to put through
performance testing, I saw
a comment by Martin Smith and
an answer by
Zhorov (that has been subsequently removed) that made me want to explore a different way to approach the problem:
we extract the elements from the string by pretending it's JSON (to treat
it like an array), then we can use OPENJSON's
key to indicate order. For example:
CREATE OR ALTER FUNCTION dbo.SplitOrdered_JSON
(
@List nvarchar(4000),
@Delimiter nchar(1)
)
RETURNS table WITH SCHEMABINDING
AS
RETURN
(
SELECT seq = [key], value
FROM OPENJSON(N'["' + REPLACE(@List, @Delimiter, N'","') + N'"]') AS x
);
GO
This function is certainly simpler than the others. Example usage:
DECLARE @List nvarchar(4000) = N'one,two,three,two,three';
SELECT seq, value FROM dbo.SplitOrdered_JSON(@List, N',') ORDER BY seq;
Results:
seq value
---- -----
1 one
2 two
3 three
4 two
5 three
So, we'll put the JSON approach to the test against the other methods. Note
that this is different from a technique I discussed in a recent tip, "Handling
an unknown number of parameters in SQL Server,"
where I use OPENJSON() to break apart an incoming
string already formatted as JSON. An important difference: that solution disregards
order entirely, as it is primarily used to provide join or filter functionality
(e.g. IN, EXISTS).
Tests
We'll create tables with the following row counts:
- 1,000
- 10,000
- 100,000
In those tables, in a column called List, we'll
store comma-separated strings of varying sizes. We can plot the max number of items
that a single comma-separated list can contain, and the max length any of those
items can be, to determine the maximum size any string can be. If there are exactly
that number of elements and they're all the max length, then the maximum size
in characters is (length) * (number of elements) + (a comma for every element except
the last one). This is shown in the following table:
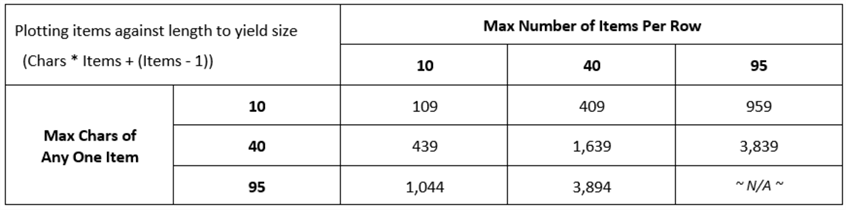
The key is keeping all the potential values within the stated 4,000-character limit to avoid any LOB handling or data truncation.
We'll create a table for each of those possible combinations (for each
of the three sizes), making for 24 tables total. We'll populate them with
arbitrary data from sys.all_columns, then we can run
queries against each table with each of the functions.
Here is some dynamic SQL we can use to create the 24 tables – it's a little much, I agree. But coming up with these scripts are, for me, the most fun part of writing articles like this:
DECLARE @CreateSQL nvarchar(max), @PopulationSQL nvarchar(max); ;WITH n(n) AS
(
SELECT n FROM (VALUES(10),(40),(95)) AS n(n)
),
NumRows(n) AS
(
SELECT n FROM (VALUES(1000),(10000),(100000)) AS r(n)
)
SELECT @CreateSQL = STRING_AGG(N'CREATE TABLE dbo.Str_' + RTRIM(NumRows.n)
+ '_MaxLen' + RTRIM(nLen.n)
+ '_MaxNum' + RTRIM(nNum.n)
+ N'(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar('
+ RTRIM(nLen.n * nNum.n + (nNum.n - 1)) + '));',
char(13) + char(10)) WITHIN GROUP (ORDER BY NumRows.n, nLen.n, nNum.n), @PopulationSQL = STRING_AGG(CONVERT(nvarchar(max), N'
;WITH x(List) AS
(
SELECT STRING_AGG(LEFT(name, ' + RTRIM(nLen.n) + '), N'','')
FROM sys.all_columns
GROUP BY object_id HAVING COUNT(*) BETWEEN 2 AND ' + RTRIM(nNum.n) + '
)
INSERT INTO dbo.Str_' + RTRIM(NumRows.n)
+ '_MaxLen' + RTRIM(nLen.n)
+ '_MaxNum' + RTRIM(nNum.n) + N'(List)
SELECT TOP (' + RTRIM(NumRows.n) + ') LEFT(x.List, '
+ RTRIM(nLen.n * nNum.n + (nNum.n - 1)) + N')
FROM x CROSS JOIN x AS x2
ORDER BY NEWID();'),
char(13) + char(10))
FROM n AS nLen
CROSS JOIN n AS nNum
CROSS JOIN NumRows
WHERE nLen.n < 95 OR nNum.n < 95; -- 95 items + 95 length exceeds nvarchar(4000); EXEC sys.sp_executesql @CreateSQL;
EXEC sys.sp_executesql @PopulationSQL;
This results in these 24 CREATE TABLE commands:
CREATE TABLE dbo.Str_1000_MaxLen10_MaxNum10(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(109)); CREATE TABLE dbo.Str_1000_MaxLen10_MaxNum40(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(439)); CREATE TABLE dbo.Str_1000_MaxLen10_MaxNum95(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(1044)); CREATE TABLE dbo.Str_1000_MaxLen40_MaxNum10(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(409)); CREATE TABLE dbo.Str_1000_MaxLen40_MaxNum40(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(1639)); CREATE TABLE dbo.Str_1000_MaxLen40_MaxNum95(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(3894)); CREATE TABLE dbo.Str_1000_MaxLen95_MaxNum10(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(959)); CREATE TABLE dbo.Str_1000_MaxLen95_MaxNum40(i int IDENTITY(1,1) PRIMARY KEY, List nvarchar(3839)); … repeat for 10000 and 100000
And 24 population commands that look like this:
;WITH x(List) AS
(
SELECT STRING_AGG(LEFT(name, 10), N',')
FROM sys.all_columns
GROUP BY object_id HAVING COUNT(*) BETWEEN 2 AND 10
)
INSERT INTO dbo.Str_1000_MaxLen10_MaxNum10(List)
SELECT TOP (1000) LEFT(x.List, 109)
FROM x CROSS JOIN x AS x2
ORDER BY NEWID();
;WITH x(List) AS
(
SELECT STRING_AGG(LEFT(name, 10), N',')
FROM sys.all_columns
GROUP BY object_id HAVING COUNT(*) BETWEEN 2 AND 40
)
INSERT INTO dbo.Str_1000_MaxLen10_MaxNum10(List)
SELECT TOP (1000) LEFT(x.List, 439)
FROM x CROSS JOIN x AS x2
ORDER BY NEWID(); … 22 more …
Next, we'll set up Query Store:
ALTER DATABASE ABStrings SET QUERY_STORE
(
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 1),
DATA_FLUSH_INTERVAL_SECONDS = 60,
INTERVAL_LENGTH_MINUTES = 1,
SIZE_BASED_CLEANUP_MODE = AUTO,
QUERY_CAPTURE_MODE = ALL /* NOTE: not recommended in production! */
);
We'll run these functions 1,000 times each against the three tables with Erik Ejlskov Jensen's SqlQueryStress, and then review metrics from Query Store. To generate the tests we need, we can run this code:
;WITH fn AS
(
SELECT name FROM sys.objects
WHERE type = N'IF'
AND name LIKE N'SplitOrdered[_]%'),
t AS
(
SELECT name FROM sys.tables
WHERE name LIKE N'Str[_]100%'
)
SELECT N'SELECT /* test:' + t.name + ',' + fn.name + '*/ *
FROM dbo.' + t.name + ' AS t
CROSS APPLY dbo.' + fn.name + N'(t.List,'','') AS f;'
FROM fn CROSS JOIN t;
Note that I embed a comment into the generated queries so that we can identify the test when we parse the query text captured by Query Store.
Then we paste the output into SqlQueryStress, set iterations to 100 and threads to 10, hit GO, and go to bed. In the morning, we'll likely find that we didn't get as many test results as we'd like, since some of the functions will be very slow indeed. And CPU-heavy – this is a great test to run if you ever want to feel like you're getting your money's worth out of per-core licensing, or you want to justify that beefy machine you bought before the supply chain got hosed by the pandemic:
Results
Well, I initially thought the JSON looked really promising; then, I tested with Plan Explorer. Here we can see that, when using the source table with 1,000 rows, the native function has two additional sort operators and a much higher estimated cost. But it was only a little bit slower than the JSON function:

If we switch to the source table with 100,000 rows, things flip a little bit. Now the native variation is the fastest, even though it does close to 200X more reads than the JSON function, and still has those two pesky sorts. And it used less CPU than the others, even though it shows the highest estimated cost in the group:

As is often the case, we can chuck the estimated costs out the window. We can also concede that, on a fast machine with enough memory to never have to go to disk, reads don't necessarily mean all that much either. If we just looked at estimated costs, we certainly would not have been able to predict that JSON would be slower against larger data sets or that the recursive CTE would be so slow in comparison (though reads would help with the latter).
But one run in Plan Explorer is hardly a true test. We can take a closer look at aggregate metrics across more than one execution for all three table sizes to get a better idea.
Query Store
If we step back and look at data from Query Store, JSON doesn't look quite so bad. We can use this ugly query to generate the data needed for the charts that follow:
;WITH step1 AS
(
SELECT q = REPLACE(qt.query_sql_text, N'SplitOrdered_', N''),
avg_duration = AVG(rs.avg_duration/1000)
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON p.plan_id = rs.plan_id
WHERE qt.query_sql_text LIKE N'%test:Str[_]1000%Num%Len%dbo.SplitOrdered%'
AND qt.query_sql_text NOT LIKE N'%sys.query_store_runtime_stats%'
GROUP BY REPLACE(qt.query_sql_text, N'SplitOrdered_', N'')
),
step2 AS
(
SELECT Table_Size = REPLACE(REPLACE(
SUBSTRING(q, CHARINDEX('100', q),6),'_',''),'M',''),
Num_Items = SUBSTRING(q, CHARINDEX('Num', q)+3, 2),
Max_Len = SUBSTRING(q, CHARINDEX('Len', q)+3, 2),
[Function] = SUBSTRING(q, CHARINDEX(',', q)+1, 25),
avg_duration
FROM step1
)
SELECT Table_Size,
Num_Items,
Max_Len,
[Function] = LEFT([Function], CHARINDEX(N'*', [Function])-1),
avg_duration
FROM step2
ORDER BY Table_Size, Num_Items, Max_Len, [Function];
Now we can take that output, paste it into Excel, merge a few header cells, and make some pretty pictures.
1,000 Rows
At 1,000 rows, JSON is the clear winner in terms of duration, while the recursive CTE solution is a dog. (Spoiler: it's not going to get any better as we scale up.)

10,000 rows
As we get larger, JSON starts to lose out very slightly to the native and stacked CTE solutions, but the stacked CTE gets worse when the string contains more elements (and recursive is still terrible across the board):
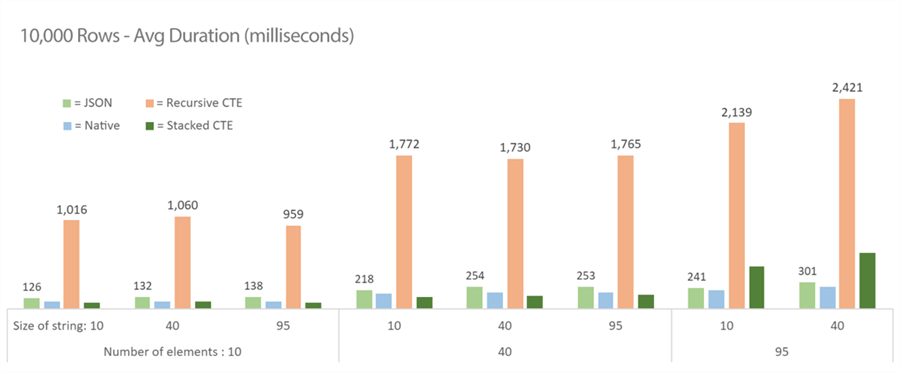
100,000 rows
At this size, JSON is still losing to the CTE options, and recursive is still (now predictably) bad – though, interestingly, it performs worst on the strings with the smallest number of elements:
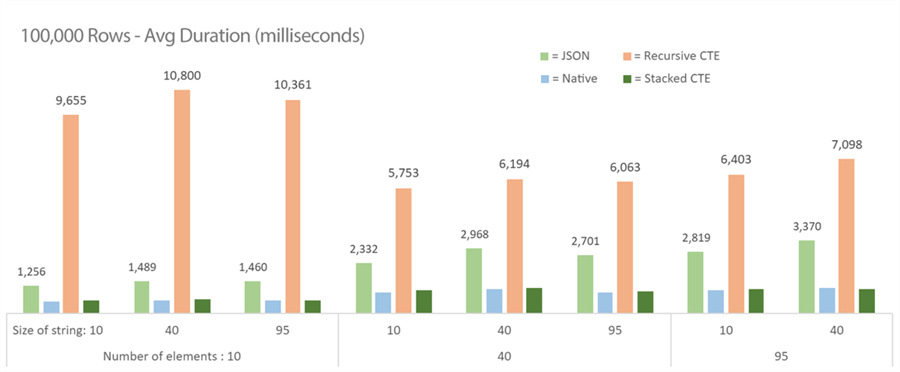
Analysis
After all that, my take:
- The recursive CTE solution is out, as it performed the absolute worst in all 96 tests.
- The native solution seems best at all three scales tested here, but remember,
you can't trust the ordering if your data is vulnerable to duplicates. And
it is still limited by the single-character delimiter support of
STRING_SPLIT(); you could probably implement your ownREPLACE()with some obscure Unicode character that can't possibly appear in the data, but that character is going to be tough to choose, and adding aREPLACE()to longer strings will certainly cut into the efficiency. - I want to love Jonathan's solution using stacked CTEs, but the code
is admittedly cryptic and the most complex in this set, and it is not the best performer
in one of our most common use cases (splitting a single list or small strings across
few rows). Also, to support multi-character delimiters again, we would need to revert
some of the changes I made (removing
LEN()calls against the delimiter). - While we may lose a little speed at the extreme end, the JSON function is
brain-dead simple to implement, and is my choice going forward if I must pick a
single function to handle all ordered string splitting. We're talking about
3+ seconds for splitting the extreme case of 100,000 strings into half a million
values, which is very atypical in our environment. And I believe it is possible
to get some of that speed back in the case where the incoming string is already
valid JSON; this could potentially eliminate the
REPLACE()call that probably didn't help our CPU time at the high end.
Conclusion
While I'd love to convince everyone to
stop splitting strings in SQL Server, or even stop having any kind of comma-separated
list anywhere near the database in the first place, those decisions are not always
in the control of the people I can influence. Until then, we can continue to come
up with the best way to deal with the hand we've been given. If you need to
split strings and return a column to indicate ordinal position,
OPENJSON() seems to be a promising approach, depending
on your data and workload, and worth including in your performance tests. Hopefully
this article also provides a framework you can use to set up your own tests of this
or any other type of function.
Next Steps
See these tips, tutorials and other resources relating to splitting strings in SQL Server:
- Handling an unknown number of parameters in SQL Server
- A way to improve STRING_SPLIT in SQL Server - and you can help
- SQL Server Split String Replacement Code with STRING_SPLIT
- SQL Server STRING SPLIT Limitations
- Solve old problems with SQL Server's new STRING_AGG and STRING_SPLIT functions
- Dealing with the single-character delimiter in SQL Server's STRING_SPLIT function
- Use Table-Valued Parameters Instead of Splitting Strings
- SQL Server 2016 STRING_SPLIT Function






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-11-08
