By: Ron L'Esteve | Updated: 2021-11-09 | Comments (2) | Related: > Azure
Problem
Ingesting and processing large varieties, velocities, and volumes of data is a key requirement of the Data Lakehouse architecture. There are a variety of Azure out of the box as well as custom technologies that support batch, streaming, and event-driven ingestion and processing workloads. These technologies include Databricks, Data Factory, Messaging Hubs, and more. Apache Spark is also a major compute resource that is heavily used for big data workloads within the Lakehouse. These many data management technologies can become overwhelming to compare and determine when to use one over this other, and customers are seeking to understand the ingestion and processing layer options within the Lakehouse.
Solution
The Data Lakehouse paradigm on Azure, which leverages Apache Spark for compute and Delta Lake for storage heavily, has become a popular choice for big data engineering, ELT, AI/ML, real-time data processing, reporting, and querying use cases. In this article, you will learn more about the various options for ingestion and processing within the Lakehouse and when to possibly use one over the other. The technologies that you will learn about in this article include Data Factory, Databricks, Functions, Logic Apps, Synapse Analytics Serverless Pools, Stream Analytics, and Messaging Hubs.
Architecture
From a compute perspective, Apache Spark is the gold standard for all things Lakehouse. It is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters and is prevalent in Data Factory's Mapping Data Flows, Databricks, and Synapse Analytics and typically powers compute of the Lakehouse. As we grown and evolve the Lakehouse paradigm, Photon, a new execution engine on the Databricks Lakehouse platform provides even better performance than Apache Spark and is fully compatible with Apache Spark APIs. When there is an opportunity to utilize Photon for large data processing initiatives in supported platforms such as Databricks, it would certainly be a sound option. In this article, we will focus on the Ingestion and Processing Layers of the architecture diagram shown below.
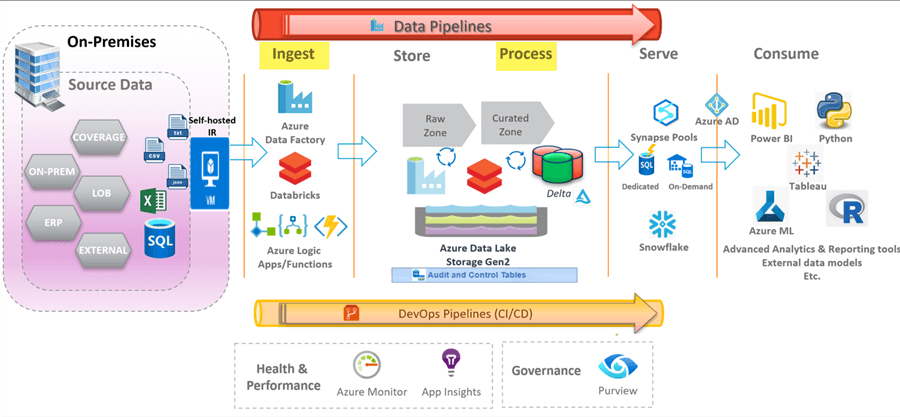
Ingestion and Processing
This initial portion of any data architecture is the ingestion process. Data sources range from on-premises to a variety of cloud sources. There are a few Azure resources that are typically used for the data ingestion process. This includes Data Factory, Databricks, and custom functions and connectors. This section will further explore some of these components and their capabilities.
Data Factory
Data Factory's tight integration with on-premises data sources using the self-hosted IR has positioned this service as a tool of choice for integrating a combination of on-premises and cloud sources using reusable and meta-data driven ELT patterns. For cloud sources, the Azure IR is recommended and the SSIS IR is used for running the SSIS engine which allows you to natively execute SSIS packages. An Integration Runtime is the compute infrastructure used by Azure Data Factory to provide data integration capabilities such as Data Flows and Data Movement which has access to resources in either public, private and/or hybrid network scenarios.
Within ADF, Integration Runtimes (IR) are the compute infrastructure used to provide data integration capabilities such as Data Flows and Data Movement. ADF has the following three IR types:
- Azure Integration Runtime: All patching, scaling and maintenance of the underlying infrastructure is managed by Microsoft and the IR can only access data stores and services in public networks.
- Self-hosted Integration Runtimes: The infrastructure and hardware are managed by you and you will need to address all the patching, scaling and maintenance. The IR can access resources in both public and private networks.
- Azure-SSIS Integration Runtimes: VMs running the SSIS engine allow you to natively execute SSIS packages. All the patching, scaling and maintenance are managed by Microsoft. The IR can access resources in both public and private networks.
Data Factory also supports complex transformations with its Mapping Data Flows service which can be used to build transformations, slowly changing dimensions, and more. Mapping Data Flows utilizes Databricks Apache Spark clusters under the hood and has a number of mechanisms for optimizing and partitioning data.
Mapping data flows are visually designed data transformations in Azure Data Factory. Data flows allow data engineers to develop data transformation logic without writing code. The resulting data flows are executed as activities within Azure Data Factory pipelines that use scaled-out Apache Spark clusters. We will explore some of the capabilities of Mapping data flows in Chapters 11 through 15 for data warehouse ETL using SCD Type I, big data lake aggregations, incremental upserts, and Delta Lake. There are many other use cases around the capabilities of Mapping Data Flows that will not be covered in this book (e.g.: dynamically splitting big files into multiple small files, manage small file problems, Parse transformations, and more), and I would encourage you to research many of these other capabilities of Mapping Data Flows.
Additionally, data can be transformed through Stored Procedure activities in the regular Copy Data activity of ADF.
There are three different cluster types available in Mapping Data Flows: general Purpose, Memory optimized and Compute optimized.
- General Purpose: Use the default general purpose cluster when you intend to balance performance and cost. This cluster will be ideal for most data flow workloads.
- Memory optimized: Use the more costly per-core memory optimized clusters if your data flow has many joins and lookups since they can store more data in memory and will minimize any out-of-memory errors you may get. If you experience any out of memory errors when executing data flows, switch to a memory optimized Azure IR configuration.
- Compute optimized: Use the cheaper per-core priced compute optimized clusters for non-memory intensive data transformations such as filtering data or adding derived columns
ADF also has a number of built in and custom activities which integrate with other Azure services ranging from Databricks, Functions, Login Apps, Synapse and more. Data Factory also has connectors for other cloud sources including Oracle Cloud, Snowflake, and more. The figure below shows a list of the various activities that are supported by ADF. When expanded, each activity contains a long list of customizable activities for ELT. While Data Factory is typically designed for batch ELT, its robust event-driven scheduling triggers can also support event-driven real-time processes, although Databricks Structured Streaming is typically recommended for all things streaming. Data Factory also has robust scheduling and monitoring capabilities with verbose error logging and alerting to support traceability and restart capabilities of pipelines. Pipelines that are built in ADF can be dynamic and parameterized, which contribute to the reusability of pipelines that are driven by robust audit, balance, and control ingestion frameworks. Data Factory also securely integrates with Key Vault for secret and credential management. Synapse pipelines within Synapse Analytics workspace has a very similar UI as Databricks as it continues to evolve into the Azure standard unified analytics platform for the Lakehouse. Many of the same ADF pipelines can be built with Synapse pipelines with a few exceptions. For features and capabilities that are available in the more Data Factory v2 toolbox, choose Data Factory V2 as the ELT tool.
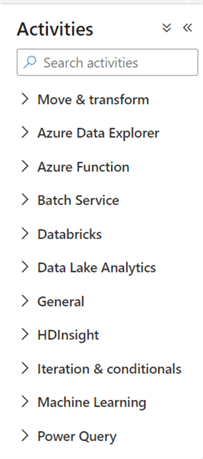
Data Factory supports over 90 sources and sinks as part of its ingestion and load process. In the subsequent chapters, you will learn how to create pipelines, datasets, linked services, and activities in ADF.
- Pipelines are logical grouping of activities that together perform a task.
- Activities define actions to perform on your data (For example: Copy data activity, ForEach loop activity etc.)
- Datasets are named views of data that simply points or references the data you want to use in your activities within the pipeline.
- Linked Services are much like connection strings, which define the connection information needed for Data Factory to connect to external resources.
Currently, there are a few limitations with ADF. Some of these limitations include:
- Inability to add a For Each activity or Switch activity to an If activity.
- Inability to nest ForEach loop, If and Switch activities.
- Lookup activity has a maximum of 5,000 rows and a maximum size of 4 MB.
- Inability to add CRON functions for modular scheduling.
Some of these limitations are either on the ADF product team's roadmap for future enhancement or there are custom solutions and workarounds. For example, the lack of modular scheduling within a single pipeline can be offset by leveraging tools such as Azure Functions, Logic Apps, Apache Airflow and more. Ensure that you have a modular design with many pipelines to work around other limitations such as the 40 activities per pipeline limit. Additional limitations include 100 queued runs per pipeline and 1,000 concurrent pipeline activity runs per subscription per Azure Integration Runtime region.
Databricks
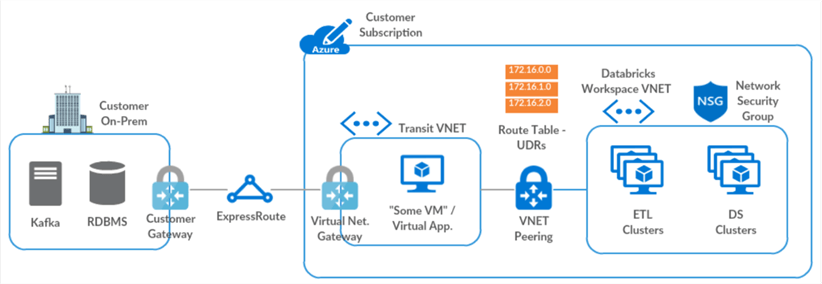
Databricks can also be used for data ingestion and is typically well suited for cloud and streaming sources. While Databricks can certainly be connected to an on-premises network using an architecture similar to the Figure below, it is an unnecessarily complex path to access on-premises data sources given the robust capabilities of ADF's self-hosted IR. When connecting to on-premises source, try to use ADF as much as possible. On the other hand, from a streaming perspective, Databricks leverages Apache Spark to ingest and transform real-time big data sources with ease. It can store the data in a variety of file formats including Parquet, Avro, Delta, and more. These storage formats will be covered in more detail within the storage section. When combined with ADF for ingestion, Databricks can be a powerful customizable component in the Lakehouse data ingestion framework.
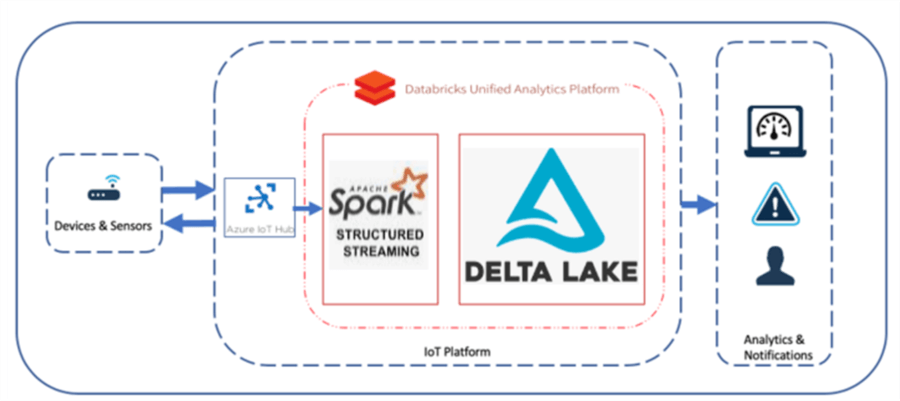
Apache Spark's structured streaming is a stream processing framework built on the Spark SQL engine. Once a computation along with the source and destination are specified, the structured streaming engine will run the query incrementally and continuously as new data is available. Structured streaming treats a stream of data as a table and continuously appends data. Databricks does an excellent job of implementing structured streaming solutions using events fed into an Azure IoT Hub and processed by Apache Spark through a Databricks Notebook and into a Delta Lake to persist the data. Structured streaming provides the robust capability of applying advanced schema evolution, data aggregations, and transformation on datasets in real-time. The concept of event driven ELT paradigms is a best practice within the Lakehouse. Databricks Auto Loader is a designed for event driven structured streaming ELT and advanced schema evolution patterns.
Functions and Logic Apps
With serverless Functions, developers can create custom event-driven serverless code that can solve complex data integration and orchestration challenges. Functions can be called from both Databricks notebooks as well as Data Factory pipelines. With Logic Apps, creating and running automated workflows that integrate your apps, data, services, and systems has never been easier. With this platform, you can quickly develop highly scalable integration solutions.
Synapse Analytics Serverless Pools
Synapse Analytics play a strong role in the Lakehouse architecture due to it ever growing and flexible feature set which includes dedicated MPP SQL big data warehouses, serverless on-demand SQL and Apache Spark pools, and its very own workspace environment for writing and executing custom code along with creating, scheduling, and monitoring pipelines.
With Serverless SQL Pools, developers can write SQL scripts similar to what is shown in the code below which demonstrates how to query the Azure Data Lake Storage gen2 account by using standard SQL commands along with the OPENROWSET function. The format can include parquet, delta, and others. Queries can contain complex joins with orders and groupings. Also, wild cards such as '*.parquet' are permitted in the ADLS gen2 folder path. Once a SQL endpoint is created, it can be connected to BI services such as Power BI and more. The user will be able to easily retrieve the tables through the UI while the underlying data is actually in parquet file format.
With serverless Apache Spark pools, you can leverage Apache spark for compute resources that are similar to Databricks Spark clusters. It is also unique from Data Factory in that it does not utilize Databricks compute resources. there is no need to set up any underlying infrastructure to maintain clusters. With its pay per use model, serverless pool charges are calculated per terabyte for data that is processed by each query that is run. This model separates storage from compute costs to promote a cost-efficient Lakehouse architecture that provides fine grained insights into storage and compute costs. Note also that external tables can also be created with data lake delta format files. The default Spark node size is memory-optimized and it has a few options: Small (~4 vCores/32GB), Medium (~8 vCores/64GB), Large (~16 vCores/128GB), XLarge (~32 vCores/256GB), XXLarge (~64 vCores/432GB), XXXLarge (~80 vCores/2504GB). Auto-scaling can be enabled and is determined by the number of nodes defined in the scale settings. Synapse Analytics also support Spark Structured Streaming capabilities.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'https://adls2.blob.core.windows.net/delta-lake/data/*.parquet',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2021
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2021' AS datetime) AND CAST('12/31/2021' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Stream Analytics
Azure Stream Analytics is an event-processing engine which allows examining high volumes of data streaming from devices, sensors, web sites, social media feeds, applications etc. It is easy to use and based on simple SQL query language. Additionally, it is a fully managed (PaaS) offering on Azure that can run large-scale analytics jobs that are optimized for cost since users only pay for streaming units that are consumed.
Azure Stream Analytics also offers built in machine learning functions that can be wrapped in SQL statements to detect anomalies. This anomaly detection capability coupled with Power BI's real time streaming service makes it a powerful real-time anomaly detection service. While there are a few use cases that can benefit from Stream Analytics, the Lakehouse architecture has been adopting Databricks Structured Streaming as the stream processing technology of choice since it can leverage Spark for compute of big delta and parquet format datasets and has other valuable features including Advanced Schema Evolution, support for ML use cases and more. As we wrap up this section on Stream Analytics, the following script demonstrates just how easy it is to write a Stream Analytics SQL query using the Anomaly detection function. Stream Analytics is a decent choice for a stream processing technology that is needed to process real-time data from an IoT hub which can then also be read in real-time by a Power BI dashboard.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM IoTHub
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO IoTPowerBIOutput
FROM AnomalyDetectionStep
In time-streaming scenarios, performing operations on the data contained in temporal windows is a common pattern. Stream Analytics has native support for windowing functions, enabling developers to author complex stream processing jobs with minimal effort. The following windowing functions are available within Stream Analytics:
- Tumbling window allows you to segment data into distinct time segments. (Count of tweets per time zone every 10 secs)
- Session window allows group streaming events that arrive at similar time and filter our no data. (Count of tweets that occur within 5 min of each other)
- Hopping window looks backwards to determine when an event occurs. (Every 5 secs, count of tweets in last 10 secs)
- Sliding window produces output when an event occurs. (Count of tweets for a single topic over the last 10sec)
- Snapshot window groups events that have the same timestamp. You can apply a snapshot window by adding System.Timestamp() to the GROUP BY clause.
Messaging Hubs
Azure's IoT Hub and Event Hub are cloud service offerings which can ingest and support large volumes of low latency and high reliability, real-time device data into the Lakehouse. Azure IoT Hub connects IoT devices to Azure resources and supports bi-directional communication capabilities between devices. IoT Hub uses Event Hubs for its telemetry flow path. Event Hub is designed for high throughput data streaming of billions of requests per day. Both IoT and Event Hub fit well within both Stream Analytics and Databricks Structured Streaming architectures to support the event-driven real-time ingestion of device data for further processing and storage in the Lakehouse.
The following table lists the differences in capabilities between Event Hubs and IoT Hubs.
| IoT Capability | IoT Hub standard tier | IoT Hub basic tier | Event Hubs |
|---|---|---|---|
| Device-to-cloud messaging | Yes | Yes | Yes |
| Protocols: HTTPS, AMQP, AMQP over webSockets | Yes | Yes | Yes |
| Protocols: MQTT, MQTT over webSockets | Yes | Yes | |
| Per-device identity | Yes | Yes | |
| File upload from devices | Yes | Yes | |
| Device Provisioning Service | Yes | Yes | |
| Cloud-to-device messaging | Yes | ||
| Device twin and device management | Yes | ||
| Device streams (preview) | Yes | ||
| IoT Edge | Yes |
Summary
In this article, you learned about the Ingestion and Processing layers of the Data Lakehouse. You learned about the capabilities of Databricks, Data Factory, and Stream Analytics as an ingestion tool for batch and real-time streaming data. You also learned more about Functions and Logic Apps along with where they reside in the Lakehouse. Finally Synapse Analytics Serverless pools and its robust capabilities of querying the Lake. Finally, you learned about Event and IoT Hubs for ingesting large volumes of event driven data. In another article, you will learn more about Reporting, Advanced Analytics, CI / CD, and Data Governance in the Lakehouse.
Next Steps
- Read more about Selling the Data Lakehouse
- Read more about Azure Synapse Analytics in the Azure Architecture Centre
- Read Real-time IoT Analytics Using Apache Sparks Structured Streaming
- Read Lakehouse ELT design, development and monitoring of Azure Pipelines
- Read Snowflake Data Warehouse Load with Azure Data Factory and Databricks
- Read about Spark Adaptive Query Execution (mssqltips.com)
- Read more about What Is a Lakehouse? - The Databricks Blog
- Read more about Snowflake to Delta Lake integration






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master�s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-11-09
