By: Nai Biao Zhou | Updated: 2021-11-18 | Comments (2) | Related: > Python
Problem
We may hear a mantra that we should not use HTML tables in the near-modern web development (Faulkner, 2017). For example, W3C recommends: "Tables should not be used as layout aids" (W3C, 2014). However, HTML tables are a perfect solution for presenting structured tabular data (Collins, 2017). Many web applications still use HTML tables to display tabular data. Therefore, it is worthwhile to study HTML tables and extract data from these tables. Some tools, for example, Excel and Power BI, can get data from an HTML table. However, we often need a programmatic solution to store data in an SQL Server database. IT professionals who have a limited HTML and web scraping background want to know how web scraping works. They also want to use an appropriate approach to gather the data from an HTML table.
Solution
Web scraping is the practice of collecting data from websites in an automated manner. We then store the collected data in a structured format, such as CSV or JSON, which users can access easily. Making use of web scraping techniques, many companies collect data to help business operations. Especially with the advent of the Internet era, there is a vast amount of publicly available web data. We can use web scraping to access those sorts of on-page datasets (Paruchuri, 2021). Odier concludes with 11 reasons why we should use web scraping (Odier, 2018). We usually perform web scraping in three steps:
- Retrieve web content, usually in the form of HTML.
- Search the web content for target information.
- Extract data.
When searching for web scraping techniques, we find many references to web scraping and crawling. People might use these two terms interchangeably. However, web scraping is about extracting data from websites. A typical example of web scraping is to extract data from an HTML table. Web crawling is about discovering links on the World Wide Web (WWW), for example, search engines (Patel, 2020). A web content extraction project often has two tasks: web crawling and web scraping. We first crawl, like a spider, to discover the links. Next, we retrieve the contents corresponding to these links. Finally, we extract the contents and store desired data (Kenny, 2020).
Many web scraping libraries and tools can help us to extract data from web pages. The most used library for web scraping in Python is "Beautiful Soup,” and "Selenium” (Wu, 2020). The "Scrapy” library, a web crawling framework, is another popular web scraping tool for Pythonists (Grimes, 2021). When we need to deal with simple web scraping operations, for example extracting data from static HTML pages, the library "Beautiful Soup” is appropriate. The "Selenium” is suitable for JavaScript-based web pages. Lastly, the "Scrapy” library is an excellent choice for complex data extraction projects (Palakollu, 2019).
Since this article concentrates on retrieving the structured data in HTML tables, we use the "Beautiful Soup” library for web scraping. We are interested in a list of language self-study programs on the Wikipedia site (Wikipedia, 2013). The web page that contains the list has much information. We only want to extract data in the HTML table and then save the structured data into an SQL Server database. We create a project to implement this requirement. The project uses a Python program to extract information from the web page and save data into an SQL Server database table.
To explain using the "Beautiful Soup” library, we first introduce the HTML table in a simple HTML page. We then use the "Beautiful Soup” library to select HTML elements one at a time. Next, we explore the two most used methods, "find()” and "find_all().” We can find one or more HTML elements using these two methods according to their tag names and attributes. Besides these two methods, the library also allows us to navigate the tree-like HTML structure. When locating an element, we can access its siblings, parents, children, and other descendants.
After scraping two simple HTML pages using the "Beautiful Soup” library, we write a program to scrape the "List of language self-study programs” page. Before connecting to the target website, we need to make sure we can use the site’s contents, and the target site allows us to scrape the web page. Therefore, we look at the "Terms of Use” on the website and use the build-in module "robotparser” to check the "robots.txt” file. Next, we extract data from the web page and save data into a database table. In the end, we provide the complete code of this project.
We test all the Python scripts used in this article with Microsoft Visual Studio Community 2022 Preview 4.1 and Python 3.9 (64-bit) on Windows 10 Home 10.0 <X64>. Besides installing the Beautiful Soup library into the Python virtual environment, we also install the Requests library, an elegant and simple HTTP library (Requests, 2021). The DBMS is the Microsoft SQL Server 2019 Developer Edition (64-bit). The HTML editor used in the article is Notepad++ (v8.1.5), and the web browser is the Opera browser (Version:79.0.4143.50). In addition, we use SQL Server Management Studio v18.6 to design a database table.
1 – Introducing the HTML Table
We often organize contents into a table of rows and columns. A table can provide a straightforward way to display structured tabular data. Users can easily access and digest data in the table. For example, we can arrange MSSQLTips.com authors into a table, as shown in Table 1. The table contains four rows and four columns. The first row in the table acts as the table's header, and the first column contains row headers. The last row serves as the table's footer.
| Name | Company | Title | Author Since |
|---|---|---|---|
| Greg Robidoux | Edgewood Solutions | President | 2006 |
| Jeremy Kadlec | Edgewood Solutions | Chief Technology Officer | 2006 |
| Nai Biao Zhou | N/A | N/A | 2018 |
| Total: 225 (as the date of 2021-10-08) | |||
Table 1 Some MSSQLTips.com Authors
Since some adjacent cells contain the same information, we can merge these cells. We then obtain a more straightforward table, as shown in Table 2. In addition, when merging cells, we naturally put information in groups. For example, we can easily find Greg and Jeremy work in the same company. Thus, many tables adopt merged cells if appliable. Even though the two tables have different forms, they present the same tabular data. By splitting the merged cells, we can convert Table 2 to Table 1. We usually make this kind of conversion in web scrapping so that we obtain well-structured data for storage.
| Name | Company | Title | Author Since |
|---|---|---|---|
| Greg Robidoux | Edgewood Solutions | President | 2006 |
| Jeremy Kadlec | Chief Technology Officer | ||
| Nai Biao Zhou | N/A | 2018 | |
| Total: 225 (as the date of 2021-10-08) | |||
Table 2 A Table with Merged Cells
1.1 Scraping a Simple HTML Table
A simple HTML table looks like Table 1, which arranges the data in a set of columns and rows. An HTML table can have a table header, a table body, and a table footer like the physical table. The HTML table can also consider data in the first column to be row headers. Since people mostly use computer programs to produce HTML tables, many HTML tables have the same format as the simple HTML table. Before diving into HTML tables, we first create an HTML page.
We could use HTML, standing for HyperText Markup Language, to create web pages. Some other web development languages, such as PHP, can generate HTML elements. An HTML document consists of a tree of elements. We define an HTML element using an opening tag, a closing tag, and some content between these two tags. These tags tell a web browser how to display the content. For example, the following tags and text describe a simple HTML document (WHATWG, 2021):
<!DOCTYPE html>
<html lang="en">
<head>
<title>MSSQLTips.com Authors</title>
<style>
.large_font{
font-size:24px;
}
.small_font{
font-size:16px;
}
</style>
</head>
<body>
<h1>The Talented and Community Minded MSSQLTips.com Authors</h1>
<p class="large_font">deliver value to the global SQL Server community</p>
<p class="small_font">Click on <a href="https://www.mssqltips.com/sql-server-mssqltips-authors/">here</a> for a complete list.</p>
</body>
</html>
Figure 1 illustrates how the Opera browser displays the simple HTML document. A web page must start with a DOCTYPE declaration, which defines the version of the HTML code. The declaration <!DOCTYPE html> tells the browser that the HTML code is in HTML5. The tags <html>, <head>, <body>, and <title> control the overall structure of the web page. The other tags such as <h1>, <p> and <a> contain content. We call these tags the container tags. For example, <h1> defines a large heading, and <p> defines a paragraph. The <a> tag defines a hyperlink, which allow us to navigate to another web page. We use the <style> tag to specify how HTML elements should render in a web browser.
We can add attributes to HTML elements to provide additional information about the elements. We often specify attributes in the opening tag using name/value pairs, for example, class= "large_font.” However, some Boolean attributes in HTML5, such as checked, disabled, readonly, and required only use names. In the previous HTML document, we added the "href” attribute to the <a> tag to specify the link’s destination and added the "class” attribute to the <p> tag to define the paragraph’s font size. It is worth noting that we should always enclose attribute values in quotation marks.

Figure 1 A Simple Web Page
1.1.2 Create a simple HTML Table
We add an HTML table to a web page using the <table> tag. The <tr> tag defines table rows. In each row, we create table cells using the <td> tags. These three elements are the basic building blocks of an HTML table. They form a simple tree-like structure: Table -> Row -> Cell. There are additional elements we can use to add semantic meaning to the data in the HTML table. For example, we use the tag <th> instead of <td> when using some cells as table headings. When presenting many table rows, we often arrange the rows into three sections, i.e., header, body, and footer, by using the tags <thead>, <tbody>, and <tfoot>, respectively. The following code presents a web page with a simple HTML table. The web page should look like Figure 2.
<!DOCTYPE html>
<html lang="en">
<head>
<title>MSSQLTips.com Authors</title>
<style>
table, th, td {
border: 1px solid black;
border-collapse: collapse;
}
.large_font{
font-size:24px;
}
.small_font{
font-size:16px;
}
</style>
</head>
<body>
<h1>The Talented and Community Minded MSSQLTips.com Authors</h1>
<p class="large_font">deliver value to the global SQL Server community</p>
<table>
<thead>
<tr>
<th scope="col">Name</th>
<th scope="col">Company</th>
<th scope="col">Title</th>
<th scope="col">Author Since</th>
</tr>
</thead>
<tbody>
<tr>
<th scope="row">Greg Robidoux</th>
<td>Edgewood Solutions</td>
<td>President</td>
<td>2006</td>
</tr>
<tr>
<th scope="row">Jeremy Kadlec</th>
<td>Edgewood Solutions</td>
<td>Chief Technology Officer</td>
<td>2006</td>
</tr>
<tr>
<th scope="row">Nai Biao Zhou</th>
<td>N/A</td>
<td>N/A</td>
<td>2018</td>
</tr>
</tbody>
<tfoot>
<tr>
<td colspan = "4">Total: 225 (as the date of 2021-10-08)</td>
</tr>
</tfoot>
</table>
<p class="small_font">Click on <a href="https://www.mssqltips.com/sql-server-mssqltips-authors/">here</a> for a complete list.</p>
</body>
</html>

Figure 2 A Simple Web Page with an HTML Table
1.1.3 Using Beautiful Soup
Beautiful Soup is a Python library designed for pulling data from HTML and XML files (BeautifulSoup, 2020). With this library, we can easily navigate, search, and modify an HTML document. Beautiful Soup can take an HTML document as input and then construct a BeautifulSoup object representing the parsed document. Through the BeautifulSoup object, we can access other objects such as Tag, NavigableString, and Comment. A Tag object represents the corresponding tag in the HTML document. A NavigableString object represents the text within a tag. A Comment object, a particular type of NavigableString, represents a comment in the document. To explore these features, we create a Python application project using Visual 2022 Preview. To keep all libraries separated by project, we add a virtual environment to this project using this requirement.txt:
beautifulsoup4==4.10.0 certifi==2021.10.8 charset-normalizer==2.0.6 idna==3.2 pip==21.2.3 pyodbc==4.0.32 requests==2.26.0 setuptools==57.4.0 soupsieve==2.2.1 urllib3==1.26.7
1.1.3.1 Construct a Beautiful Soup Object
We use the Beautiful Soup constructor to create a Beautiful Soup instance. The first argument of the constructor is a string or an open filehandle that represents an HTML document. It is also worth pointing out that Beautiful Soup is not an HTTP client; therefore, we cannot pass an URL to the constructor. The second argument specifies the parser that we want BeautifulSoup to use. In most cases, it makes no difference which parser we choose (Mitchell, 2018). Since the parser "html.parser" is built-in with Python 3, we use this parser in our project. The following sample code constructs a Beautiful Soup instance:
from bs4 import BeautifulSoup, NavigableString
html = """
"""
soup_1_1 = BeautifulSoup(html, 'html.parser')
print(soup_1_1.title)
print(soup_1_1.title.get_text())
# If we save the html code into the file "list 1.1.2.html”
with open('list 1.1.2.html') as html_file:
soup_1_1_2 = BeautifulSoup(html_file , 'html.parser')
print(soup_1_1_2.title)
print(soup_1_1_2.title.get_text())
After obtaining the Beautiful Soup instance, we can immediately access Tag objects, and locate the desired content in the HTML document. For example, we print the title element and the text content in the element in the Python Interactive window:
>>> soup_1_1 = BeautifulSoup(html, 'html.parser') >>> print(soup_1_1.title) <title>MSSQLTips.com Authors</title> >>> print(soup_1_1.title.get_text()) MSSQLTips.com Authors >>>
We continue to run the following Python statements to practice how to access the tags in the HTML document. When using a tag name as an attribute, we can observe that the Beautiful Soup instance returns the first Tag instance by the tag name. We should also notice that the attributes "soup_1_1.body.h1” and "soup_1_1. h1” return the same value. If we know a tag in the HTML document is unique, for example, "title,” this approach can give us the desired data. Otherwise, we should search for tags in the HTML tree structure.
print(soup_1_1.head) print(soup_1_1.head.get_text()) print(soup_1_1.head.style) print(soup_1_1.style) print(soup_1_1.body.h1) print(soup_1_1.h1) print(soup_1_1.body.a) print(soup_1_1.a) print(soup_1_1.a.get_text()) print(soup_1_1.th) print(soup_1_1.td) print(soup_1_1.td.get_text()) print(soup_1_1.tr)
1.1.3.2 Searching the Tree Structure in the Beautiful Soup Instance
When searching for tags in the Beautiful Soup instance, we often use these two methods: find() and find_all(). These two methods are similar; however, the "find()” method only returns the first matched object, and the "find_all()” method returns all matched objects. The official Beautiful Soup document (BeautifulSoup, 2020) provides a complete list of filters we can pass into these two methods. However, as Mitchell mentioned, "In all likelihood, 95% of the time you will need to use only the first two arguments: tag and attributes” (Mitchell, 2018). The following exercise in the Python interactive window demonstrates how to use these two methods. The exercise also shows the way to access the tag name and attribute values (PYTutorial, 2021).
>>> paragraph = soup_1_1.find('p',{'class':'small_font'})
>>> print(paragraph.get_text())
Click on here for a complete list.
>>> print(paragraph.attrs['class'])
['small_font']
>>> data_cells = soup_1_1.find_all('td')
>>> for cell in data_cells:
... print('Tag Name: {}; Content:{}'.format(cell.name,cell.get_text()))
...
Tag Name: td; Content:Edgewood Solutions
Tag Name: td; Content:President
Tag Name: td; Content:2006
Tag Name: td; Content:Edgewood Solutions
Tag Name: td; Content:Chief Technology Officer
Tag Name: td; Content:2006
Tag Name: td; Content:N/A
Tag Name: td; Content:N/A
Tag Name: td; Content:2018
Tag Name: td; Content:Total: 225 (as the date of 2021-10-08)
>>>
In the exercise, we pass tag names and attributes to the "find()” and "find_all()” methods to obtain the desired information. We can also use the "extract()” method to remove a tag from the tree structure; we then access the rest. By the way, the "extract()” method returns the removed tag. The HTML document has two <p> tags. When removing the first one, we can access the second one using the tag name. This approach is helpful when we want to exclude a tag. We demonstrate the approach using the following code:
>>> soup_1_1.p.extract() deliver value to the global SQL Server community >>> print(soup_1_1.p.get_text()) Click on here for a complete list. >>>
1.1.3.3 Navigating the Tree Structure in the Beautiful Soup Instance
A node in a tree-like structure always has parents, children, siblings, and other descendants. The Beautiful Soup library provides us with these attributes to navigate the tree. Through these attributes, we can extract any information from an HTML document. Even though an HTML element does not have a unique identifier, we can locate the element through other identifying elements. The Beautiful Soup official document gives excellent examples of navigating the tree (BeautifulSoup, 2020). We only explore the parent and children attributes in this article. First, we access an element’s parent with the "parent” attribute. For example, the following code gets a column header; then, the parent attribute allows us to access the table header.
>>> print(soup_1_1.th) <th scope="col">Name</th> >>> print(soup_1_1.th.parent) <tr> <th scope="col">Name</th> <th scope="col">Company</th> <th scope="col">Title</th> <th scope="col">Author Since</th> </tr> >>>
Next, the following code shows how to access all column headers in the HTML table given the table header.
>>> table_row = soup_1_1.tr.children
>>> for cell in table_row:
... if isinstance(cell, NavigableString): continue
... print('=================================')
... print(cell)
...
=================================
<th scope="col">Name</th>
=================================
<th scope="col">Company</th>
=================================
<th scope="col">Title</th>
=================================
<th scope="col">Author Since</th>
>>>
We explored all methods and features we needed to scrape the simple table. We can design a program to scrape the HTML table. Several ways can scrape the simple table. For example, Gaurav provides complete code to extract three HTML tables and save data into CSV files (Gaurav, 2019). We choose a slightly different way for easy explanation. We first access the table body. We then loop through the table body’s children to get all rows. Next, we loop through each row to get text in the table cells. The following code demonstrates this process:
from bs4 import BeautifulSoup, Tag
soup_1_1 = BeautifulSoup(html, 'html.parser')
for table_row in soup_1_1.tbody.children:
if isinstance(table_row, Tag):
cells = list()
for cell in table_row.children:
if isinstance(cell, Tag):
cells.append(cell.get_text())
print("{0:20}{1:20}{2:30}{3:20}".format(cells[0],cells[1],cells[2],cells[3]))
# Output of the script:
#Greg Robidoux Edgewood Solutions President 2006
#Jeremy Kadlec Edgewood Solutions Chief Technology Officer 2006
#Nai Biao Zhou N/A N/A 2018
The Beautiful Soup constructor takes web page content and a parser name to create a Beautiful Soup instance in the above code. The Beautiful Soup instance represents a parse tree of the entire web page. However, the web page could have much information, and we only need a small portion of the web page. Therefore, we can use a SoupStrainer object to tell the Beautiful Soup what elements should be in the parse tree. This approach could save time and memory when we perform web scraping (Zamiski, 2021). The following code creates a SoupStrainer object that limits the parse tree to the table body element.
from bs4 import BeautifulSoup, Tag, SoupStrainer
strainer = SoupStrainer(name='tbody')
soup_1_1_ = BeautifulSoup(html, 'html.parser',parse_only=strainer)
for table_row in soup_1_1_.tbody.children:
if isinstance(table_row, Tag):
cells = list()
for cell in table_row.children:
if isinstance(cell, Tag):
cells.append(cell.get_text())
print("{0:20}{1:20}{2:30}{3:20}".format(cells[0],cells[1],cells[2],cells[3]))
1.2 Scraping an HTML table with Merged Cells
When a table has many rows and columns, we may merge the adjacent cells with duplicate content, as shown in Table 2. Since Greg and Jeremy work in the same company and have become MSSQLTips.com authors since 2006, we can collapse the same values into a single cell (Penland, 2020). Nai Biao did not provide the company and title information; rather than having the value "N/A” expressed twice, we can merge the two data cells into one. When performing web scraping, we split the merged cells. Then, we can import the well-structured data into other systems.
1.2.1 Create an HTML table with Merged Cells
We can add attributes to the HTML table tags to tell the web browser how to display the table. For example, when we merge horizontal adjacent data cells into a single cell, we add the "colspan” attribute to the <td> tag. The value of the attribute determines how many data cells are merged into a single cell. Likewise, suppose we merge vertical adjacent data cells into a single cell. In that case, we add the attribute "rowspan” to the <td> tag. The following code demonstrates how to add the "colspan” and "rowspan” attributes to the <td> tags, and Figure 3 shows how the table should look. We can observe that the numbers of <td> tags in each row are not the same.
<!DOCTYPE html>
<html lang="en">
<head>
<title>MSSQLTips.com Authors</title>
<style>
table, th, td {
border: 1px solid black;
border-collapse: collapse;
}
.large_font{
font-size:24px;
}
.small_font{
font-size:16px;
}
</style>
</head>
<body>
<h1>The Talented and Community Minded MSSQLTips.com Authors</h1>
<p class="large_font">deliver value to the global SQL Server community</p>
<table>
<thead>
<tr>
<th scope="col">Name</th>
<th scope="col">Company</th>
<th scope="col">Title</th>
<th scope="col">Author Since</th>
</tr>
</thead>
<tbody>
<tr>
<th scope="row">Greg Robidoux</th>
<td rowspan=2>Edgewood Solutions</td>
<td>President</td>
<td rowspan=2>2006</td>
</tr>
<tr>
<th scope="row">Jeremy Kadlec</th>
<td>Chief Technology Officer</td>
</tr>
<tr>
<th scope="row">Nai Biao Zhou</th>
<td colspan=2>N/A</td>
<td>2018</td>
</tr>
</tbody>
<tfoot>
<tr>
<td colspan = "4">Total: 225 (as the date of 2021-10-08)</td>
</tr>
</tfoot>
</table>
<p class="small_font">Click on <a href="https://www.mssqltips.com/sql-server-mssqltips-authors/">here</a> for a complete list.</p>
</body>
</html>

Figure 3 An HTML Table with Merge Cells
1.2.2 Scrape the HTML Table with Merged Cells.
Compared to the code list in 1.1.2, the HTML Table with merged cells in 1.2.1 has the same number of <tr> tags; however, the number of <td> tags in every row might differ. This difference is because some <td> tags represent the merged cells, which causes fewer <td> tags in the same row or the next row. Therefore, we should split the merged cells into the same number of the cells defined in the "colspan” or "rowspan” attribute.
We first create a two-dimensional python list that represents the data cells in the table. We then loop through each <td> tag to check the attribute "colspan.” Suppose a <td> tag’s attribute "colspan” has a value of two. In that case, we add the data cell content immediately after the corresponding item in the same row of the two-dimensional list. When the attribute "rowspan” value is two, we insert the content in the next row of the two-dimensional list at the same horizontal position. The following Python code demonstrates these steps.
from bs4 import BeautifulSoup
html = """
<! -- Add the HTML code list in Section 1.2.1 -- >
"""
# Construct a Beautiful Soup instance
soup_1_2 = BeautifulSoup(html, 'html.parser')
# Extract the data in the HTML table to a list of list,i.e., two-dimentional list
rows = list()
for row_num, table_row in enumerate(soup_1_2.tbody.find_all('tr')):
rows.append(list())
for cell in table_row.find_all(['th','td']):
rows[row_num].append(cell.get_text())
# Split the merged cells according to the colspan and rowspan
for row_num, table_row in enumerate(soup_1_2.tbody.find_all('tr')):
for cell_num, cell in enumerate(table_row.find_all(['th','td'])):
if 'colspan' in cell.attrs and cell.attrs['colspan'].isdigit():
colspan = int(cell.attrs['colspan'])
for i in range(1, colspan):
rows[row_num].insert(cell_num, cell.get_text())
if 'rowspan' in cell.attrs and cell.attrs['rowspan'].isdigit():
rowspan = int(cell.attrs['rowspan'])
for i in range(1, rowspan):
rows[row_num + i].insert(cell_num, cell.text)
# Print out the structed data
for row in rows:
print("{0:20}{1:20}{2:30}{3:20}".format(row[0],row[1],row[2],row[3]))
# Output
#Greg Robidoux Edgewood Solutions President 2006
#Jeremy Kadlec Edgewood Solutions Chief Technology Officer 2006
#Nai Biao Zhou N/A N/A 2018
2 – Performing Web Scraping on a Static Web Page
Wikipedia provides a list of self-study programs (Wikipedia, 2013). We want to extract the information and store it in a database table. To scrape data from an external website, we first need to read the "Terms of Use” to ensure the website allows us to use their information. We then need to check the "robots.txt” file on the website to see if we can run a web scraping program to extract the content of interest. After inspecting the HTML elements that contain the desired data, we write a Python program to read the web content and parse the HTML document to a tree-like structure. We then extract the data into a readable format. Finally, we save the well-structured data into a SQL database server.
2.1 Read the "Terms of Use”
Terms of use (or Terms of Service) are legal agreements between a service provider and a party such as a person or an organization who wants to use that service. To use the service, the party should agree to these terms of service. Wikipedia posted the Terms of Use on the web page https://foundation.wikimedia.org/wiki/Terms_of_Use/en, as shown in Figure 4. As of this writing, we are free to share and reuse their articles and other media under free and open licenses.

Figure 4 The Terms of Use for Articles and Media on the Wikipedia Website
2.2 Check the "robots.txt” File
Most websites provide a file called robots.txt, which tells web crawlers what URLs the crawler can access on the site. A robots.txt file is located at the root of the site. For example, we can access Wikipedia’s robots.txt file through this URL: https://en.wikipedia.org/robots.txt. We find a long list of "Disallow” on the Wikipedia site. Rather than reading through the entire list, we can use a method provided in the Python built-in module to verify the access permission. The following code demonstrates how we use the module to verify that we can scrape the page of interest. The output of the "can_fetch()” method is True, which indicates that we can safely scrape the list of self-study programs page.
from urllib import robotparser
robots_txt_parser = robotparser.RobotFileParser()
robots_txt_parser.set_url('https://en.wikipedia.org/robots.txt')
robots_txt_parser.read()
robots_txt_parser.can_fetch('*', 'https://en.wikipedia.org/wiki/List_of_language_self-study_programs')
# Output
# True
2.3 Inspect HTML Elements
We want to scrape the HTML table on the web page: https://en.wikipedia.org/wiki/List_of_language_self-study_programs, as shown in Figure 5. The table has five columns, and some cells are empty. We need to find a unique identifier of the HTML table so that we can use the "find()” method in the Beautiful Soup library. Next, we should look at the table structure. We also need to check if there is any non-standard HTML, which may result in undesired outputs.

Figure 5 The Web Page Containing the HTML Table
2.3.1 Locate the HTML table on the Web Page
Most web browsers come with development tools. First, we right-click on the web page. On the context menu, we select the menu item "Inspect,” as shown in Figure 6.

Figure 6 The Context Menu on the Opera Browser
After we select the "Inspect element” menu item, a new panel appears. We can use the "Select an element in the page to inspect it” icon to locate the HTML table tag in the HTML document, as shown in Figure 7.
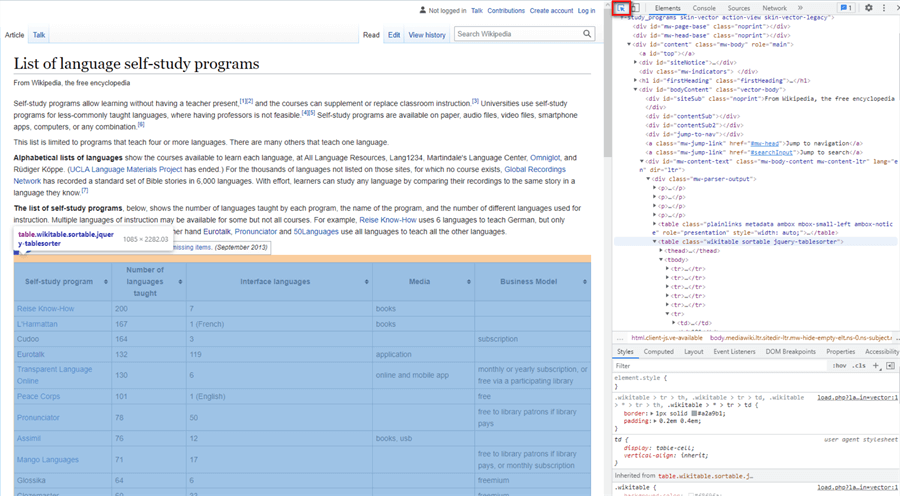
Figure 7 Inspect the HTML Table Element
We find the table structure in the "Elements” panel, like the simple HTML table in 1.1.2. The table contains a table head, a table body, and a table foot element, as shown in the following pseudocode. The data we want to extract is in the table body element. The table body element contains table row elements which, in turn, contain table cell elements. All these elements form a tree-like structure.
<table>
<thead>
<tr>
<th>…</th>
…
<th>…</th>
</tr>
</thead>
<tbody>
<tr>
<td>…</td>
…
<td>…</td>
</tr>
…
<tr>
<td>…</td>
…
<td>…</td>
</tr>
</tbody>
<tfoot></tfoot>
</table>
2.3.2 View the Source Code
To further understand the HTML table structure, we look at the page source code. We right-click on the page to bring up the context menu, as shown in Figure 6. After selecting the "Page Source” menu item, we can view the page source code, as shown in Figure 8. Because the table is sortable, the client-side JavaScript functions take control of the table head. We can observe that the table’s class attribute in the page source is different from the element inspection panel. The cause of the difference is beyond this article. We use the class name provided in the page source; we also confirm that the class name is unique in the page source.

Figure 8 Inspect the HTML Table Source Code
2.4 Scrape the HTML Table
The HTML table structure shows that all data is in the table body. The table body consists of many table rows, and each table row contains five table cells. Thus, we can loop through the table body’s children to obtain a list of table rows. Next, we loop through each data row’s children to get a list of table cells. We then save data into a list of Python tuples for performing database operations (Zhou, 2021). For example, the following code extracts data from the HTML data table and stores data in a list of tuples.
import requests
from bs4 import BeautifulSoup, Tag
html_table_data = list()
self_study_programs_page = "https://en.wikipedia.org/wiki/List_of_language_self-study_programs"
response = requests.get(self_study_programs_page)
if response.status_code == 200:
soup_2_4 = BeautifulSoup(response.text, "html.parser")
self_study_programs_table = soup_2_4.find('table',{'class':'wikitable sortable'})
for table_row in self_study_programs_table.tbody.children:
if isinstance(table_row, Tag):
data_row = list()
for data_cell in table_row.children:
if isinstance(data_cell, Tag):
data_row.append(data_cell.get_text().strip())
html_table_data.append(tuple(data_row))
print(html_table_data)
We do not always need to cleanse or transform data in the web scraping process. Instead, we can save data in a staging table for further processing. In that case, we make the web scraping independent of the data handling process and mitigate the risk of exceptions in web scraping. The staging table works like a web page cache that saves raw data into a database table (Hajba, 2018).
2.5 Store Data into an SQL Server Database
The HTML table has five columns, i.e., Self-study program, Number of languages taught, Interface languages, Media, and Business Model (Wikipedia, 2013). Examining the HTML table, we find the table is un-normalized. One data cell could have multiple-values attributes. For example, the media cell contains multiple media. We can save raw data into an un-normalized database table and use another process to handle the un-normalized data. In this exercise, we only save data into the un-normalized database table called the staging table.
2.5.1 Design the Database Table
Creating a normalized table is unnecessary since we only want to save raw data into a database table. As shown in Figure 9, we design a database table to represent the HTML table on the web page. We use empty strings in SQL to describe empty table cells. We also set the "date_extracted” column to "GETDATE ()” by default so that the value of a new row would contain the timestamp of when data is created data in the database table. Then, we provide the SQL code to create the database table.

Figure 9 The Diagram of the Staging Table
CREATE TABLE [dbo].[stg_language_self_study_programs]( [self_study_program] [nvarchar](50) NOT NULL, [number_of_languages_taught] [nvarchar](10) NOT NULL, [interface_languages] [nvarchar](500) NOT NULL, [media] [nvarchar](100) NOT NULL, [business_model] [nvarchar](250) NOT NULL, [date_extracted] [datetime] NOT NULL DEFAULT getdate(), CONSTRAINT [PK_stg_language_self_study_programs] PRIMARY KEY CLUSTERED ([self_study_program] ASC) )
2.5.2 Save the HTML table Data
We use the connection/cursor model to perform database operations. In this model, the connection object can connect to the database, send the information, create new cursor objects, and handle commits and rollbacks (Mitchell, 2018). On the other hand, a cursor object can execute SQL statements, track the connection state, and travel over result sets. For example, to insert data into a database table, we should first connect to the SQL Server database; we then use the connection object's "cursor()" method to create a cursor object. Next, we use the cursor object’s "executemany()" method to add multiple rows into a database table (Zhou, 2021). The following code demonstrates the process of adding a list of tuples to a database table. Figure 10 shows the data rows retrieved from the database table.
import sys, pyodbc
connection = pyodbc.connect(Driver="{ODBC Driver 17 for SQL Server}",
Server='192.168.2.16',
Database='demo',
UID='user',
PWD='password')
cursor = connection.cursor()
cursor.fast_executemany = True
try:
cursor.executemany('''
INSERT INTO [dbo].[stg_language_self_study_programs]
([self_study_program],[number_of_languages_taught],
[interface_languages],[media],[business_model])
VALUES(?,?,?,?,?)''',html_table_data[1:])
connection.commit()
except:
# We should log the specific type of error occurred.
print('Failed to save data to the database table: {}'.format(sys.exc_info()[1]))
raise
finally:
cursor.close()
connection.close()

Figure 10 The HTML Table Data Stored in the SQL Server Database Table
3 – The Complete Code
We write a Python program to scrape the HTML table and store data into the SQL Server database table. The program uses the Python Requests library to retrieve the HTML content on the web page. We then use the Beautiful Soup library to parse the web content and search for the HTML table elements. Next, we extract the desired data into a list of Python tuples. Finally, we use the pyodbc library to save the Python list into the database table. By and large, the program includes these five steps:
- Read the web page content.
- Use an instance of the Beautiful Soup class to parse the web content.
- Search for the table element in parsed content.
- Loop through the table body element to download data into a list of Python tuples.
- Store the HTML table data into the SQL Server Database.
Click here for the complete code. To run the program, we should assign correct values to these constant variables: DBSERVER, DATABASE_NAME, UID, and PWD.
Summary
With Web scraping (also called web content extraction), we can access nearly unlimited data. When exploring the Internet for information, we find that many web pages use HTML tables to present tabular data. The article covered a step-by-step process to download data from an HTML table and store data into a database table. We started with introducing a simple HTML page and then presented a web page with an HTML table. The HTML document demonstrated a tree-like structure, which helped us to navigate all the HTML elements. We also discussed an HTML table with merged cells. After exploring some essential methods and features provided in the Beautiful Soup library, we employed the library to extract content from these HTML tables.
To demonstrate how we extract an HTML table from a web page, we created a project to download data from a Wikipedia page. Before scraping the web page, we read the "Terms of Use” to confirm we could use the content on the page. Next, we checked the "robots.txt” file to ensure we could use a computer program to scrape the page. We then used the Python Requests library to retrieve the web content from the Wikipedia site.
We used the "find()” method in the Beautiful Soup library to locate the position of the table element. Next, we navigated across the attribute "children,” a collection of child elements, to find the desired data. We then saved the data into a two-dimensional list, which represents the HTML table data. Finally, we saved the Python list into the SQL Server database table.
Reference
BeautifulSoup. (2020). Beautiful Soup. https://www.crummy.com/software/BeautifulSoup.
Collins, J. M. (2017). Pro HTML5 with CSS, JavaScript, and Multimedia: Complete Website Development and Best Practices.New York, NY: Apress.
Faulkner, S. (2017). Hey, It’s Still OK to Use Tables. https://adrianroselli.com/2017/11/hey-its-still-ok-to-use-tables.html.
Gaurav, S. (2019). Extracting Data from HTML with BeautifulSoup, https://www.pluralsight.com/guides/extracting-data-html-beautifulsoup.
Grimes, J. (2021). Scrapy Vs. Beautifulsoup Vs. Selenium for Web Scraping. https://www.bestproxyreviews.com/scrapy-vs-selenium-vs-beautifulsoup-for-web-scraping.
Hajba, L. G. (2018). Website Scraping with Python Using BeautifulSoup and Scrapy. New York, NY: Apress.
Howe, S. (2014). Learn To Code Html And CSS. https://learn.shayhowe.com/html-css.
Kenny, C. (2020). What is the difference between web scraping and web crawling?. https://www.zyte.com/learn/difference-between-web-scraping-and-web-crawling/
Odier, G. (2018). 11 reasons why you should use web scraping. https://www.captaindata.co/blog/11-reasons-why-use-web-scraping.
Palakollu, M. S. (2019). Scrapy Vs Selenium Vs Beautiful Soup for Web Scraping. https://medium.com/analytics-vidhya/scrapy-vs-selenium-vs-beautiful-soup-for-web-scraping-24008b6c87b8
Paruchuri, V. (2021). Tutorial: Web Scraping with Python Using Beautiful Soup. https://www.dataquest.io/blog/web-scraping-python-using-beautiful-soup.
Patel, H. (2020). Web Scraping vs Web Crawling: What’s the Difference?. https://dzone.com/articles/web-scraping-vs-web-crawling-whats-the-difference.
Penland, J. (2020). Easy Tutorial for Creating HTML Tables That Add Value To Pages. https://html.com/tables/tutorial.
PYTutorial. (2021). Understand How to Use the attribute in Beautifulsoup Python. https://pytutorial.com/beautifulsoup-attribute#beautifulsoup-find-attribute-contains-a-number.
Requests. (2021). Quickstart. https://docs.python-requests.org/en/latest/user/quickstart.
Mitchell, R. (2018). Web Scraping with Python, 2nd Edition. Sebastopol, CA: O'Reilly Media.
Venmani, A. D. (2020). Requests in Python (Guide). https://www.machinelearningplus.com/python/requests-in-python.
W3C. (2014). HTML5 A vocabulary and associated APIs for HTML and XHTML. https://www.w3.org/TR/2014/REC-html5-20141028/tabular-data.html.
WHATWG. (2021). HTML: Living Standard — Last Updated 8 October 2021. https://html.spec.whatwg.org/multipage/introduction.html.
Wu. (2020). Web Scraping Basics: How to scrape data from a website in Python. https://towardsdatascience.com/web-scraping-basics-82f8b5acd45c.
Wikipedia. (2013). List of language self-study programs. https://en.wikipedia.org/wiki/List_of_language_self-study_programs.
Zamiski, J. (2021). Using Beautiful Soup’s SoupStrainer to Save Time and Memory When Web Scraping. https://medium.com/codex/using-beautiful-soups-soupstrainer-to-save-time-and-memory-when-web-scraping-ea1dbd2e886f.
Zhou, N. (2021). CRUD Operations in SQL Server using Python. https://www.mssqltips.com/sqlservertip/6694/crud-operations-in-sql-server-using-python.
Next Steps
- The author briefly covered some basics of an HTML document and an HTML table. The HTML table can arrange information into rows and columns. We do not recommend using HTML tables to layout web pages, but we can use HTML tables to structure and present tabular data. However, HTML tables, as well as web pages, could be complicated. When extracting the information from complex web pages, we may need advanced HTML parsing techniques. The Python scripts provided in this article are for demonstration. There is room to refactor these scripts. For example, we should create a separate configuration file to store sensitive information. The program should gracefully handle all exceptions and log exceptions for auditing. In addition, the Beautiful Soup library is a content parser. We used the "Requests" package to retrieve data from the Wikipedia site to perform web scraping. The "Requests” library provides an elegant solution for making GET, POST, PUT, and other types of requests and processing the received response in a flexible Pythonic way (Venmani, 2020).
- Check out these related tips:
- CRUD Operations in SQL Server using Python
- Explore the Role of Normal Forms in Dimensional Modeling
- What is a Relational Database Management System
- Create a Star Schema Data Model in SQL Server using the Microsoft Toolset
- Learning Python in Visual Studio 2019
- Python Programming Tutorial with Top-Down Approach
- Recursive Programming Techniques using Python
- Scraping HTML Tables with Python to Populate SQL Server Tables
- Web Screen Scraping with Python to Populate SQL Server Tables






About the author
 Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.
Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-11-18
