By: Andrea Gnemmi | Updated: 2021-12-29 | Comments | Related: > SQL Server vs Oracle vs PostgreSQL Comparison
Problem
In part 1 of this tutorial series, we have seen what an identity column is and the various ways to set it up and modify it in SQL Server, Oracle and PostgreSQL. In this tutorial we will dig a little deeper into identity columns and look at topics like caching identity values and how to turn an existing column (with data in it) into an identity column.
Solution
As always for test purposes I will use the Github freely downloadable database sample Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for data structure and all the Inserts for data.
Cache in SQL Identity Columns
SQL Server Database Example
In part 1, we saw that in SQL Server it is not possible to define a cache for the identity column (while it is possible for sequences), but that doesn't mean that there is not a cache! In fact, even in SQL Server there is a cache for performance reasons and it has been like this since version 2012. The default is 1,000 if the column data type is INT or 10,000 if it's a BIGINT. However, this may lead to gaps in identity values in case of inconsistent (unexpected) SQL Server shutdowns, in this case the pre-allocated values in the cache are simply lost and the identity column will restart with a huge gap of 1,000 values in the case of an INT column!
Let's demonstrate this with the syntax below, we'll insert a new row in the supplier table via an INSERT statement that we've created in part 1 of the tutorial and then provoke an unexpected shutdown in our SQL Server:
insert into supplier(Companyname, vatcode, address, city, country, email)
values('EMI Austria','123456789','Klinghofer Strasse, 2','Wien','Austria','[email protected]')
Check values:
select * from supplier

Now we'll provoke a shutdown issuing this command in a new query window:
SHUTDOWN WITH NOWAIT;

We'll now restart the service and check the value of our identity column using IDENT_CURRENT function introduced in the previous tip:
select IDENT_CURRENT('Supplier')
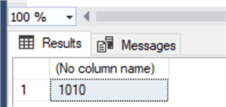
As expected, our identity column jumped 1000 values!
For some tables and applications this can be an issue, so what can be done in order to avoid this huge jump of values?
In SQL Server 2017 and later there is way to disable the cache, setting the parameter IDENTITY_CACHE ON or OFF, in this way we'll be able to avoid this possible gap in identity columns. Let's try it now!
So first we can check the parameter value with this simple query in the following example:
SELECT * FROM sys.database_scoped_configurations WHERE NAME = 'IDENTITY_CACHE'

Now we can set the parameter to OFF:
ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE=OFF

Let's check the parameter again:
SELECT * FROM sys.database_scoped_configurations WHERE NAME = 'IDENTITY_CACHE'

And now let's try again to insert a new value and then provoke an unexpected shutdown:
insert into supplier(Companyname,vatcode,address,city,country,email)
values('Granite Austria Inc','123456789','Reisenauer Strasse, 5','Graz','Austria','[email protected]')

SHUTDOWN WITH NOWAIT;
Now we will restart the service and run this query to check things.
select IDENT_CURRENT('Supplier')

As you can see now, we've avoided the values jump. To be precise the same result could have been achieved also in previous releases of SQL Server by turning on trace flag 272 in order to disable the identity cache, but the downside is that this trace flag disables the identity cache at the server level and not at database level like the IDENTITY_CACHE parameter.
Bear in mind that disabling the identity cache could lead to performance problems especially if you have lots of inserts in the tables using identity columns, so setting IDENTITY_CACHE to OFF should be carefully tested as it's potentially bad for INSERT performance.
Oracle
As we've seen in part 1, in Oracle since the identity column is directly derived from Sequences, there is the possibility to specify the value of the cache. The default is 20 and it is also possible to specify NOCACHE, thus totally avoiding the possibility of huge gaps in case of unexpected crash.
However, in Oracle we can have big problems of performance if we do not use a cache in sequences and identity columns, especially if we are in a RAC environment. Very quickly I'll cover what RAC is: the acronym is for Real Application Cluster, it is the High Availability of Oracle, a proven technology in which we have normally two nodes running two Oracle database instances, if one goes down the other takes all the load. The main difference with a traditional SQL Server cluster is that both nodes are active, thus possibly creating contention if they both access the same thing, like for example a sequence/identity column. There is a lot more to say about RAC and ways to avoid contention, for example using different services to compartmentalize the load, but that is not the scope of this tip.
So this is the basis of possible performance problems with caching. Using an identity column or sequence without a properly dimensioned cache in an Oracle RAC environment could lead to contention on the sequence which is accessed by both nodes of the RAC. That is why it is always recommended to check with application developers how many inserts per minute are expected in a table using an identity column or sequences. Obviously we are talking about huge OLTP loads.
Besides the above, we can still have gap problems in Oracle with an inconsistent shutdown (like a SHUTDOWN ABORT), in this case Oracle behaves exactly as SQL Server, so that we have a jump in identities as the cache values are discarded.
Let me demonstrate this. We insert a new row in the supplier table, but first we have to bring back the INCREMENT BY that we changed in last example of part 1 of the tip to 1 as it will be easier to check identities:
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY INCREMENT BY 1;
insert into chinook.supplier (companyname,vatcode,Address,city,country,email)
values ('EMI Austria','123456789', 'Klinghofer Strasse, 2', 'Wien','Austria','[email protected]');
commit;
Check values:
select * from chinook.supplier;

Now we shutdown with option ABORT the Oracle instance in order to provoke an inconsistent shutdown, in my case this is a PDB or Pluggable Database which is part of a CDB or Container Database (for more info see an explanation of this Multitenant architecture in my tip: https://www.mssqltips.com/sqlservertip/6843/relational-database-comparison-sql-server-oracle-postgresql/ ).
Bear in mind that it is possible to Shutdown with the Abort option a PDB only if it's in Archivelog mode, the equivalent of recovery model FULL in SQL Server, but the Archivelog mode is set at the Container (CDB) level, so it is set for all the PDBs in the Container.
In order to shutdown the PDB we connect in SSH to the host, logging in with Oracle user, and login to the container with sqlplus, checking first that ORACLE_SID variable is the service name of our container database:

Now we can connect with sqlplus:

At this point we can shutdown the TEST db using command ALTER DATABASE (valid only on PDBs) with option ABORT. Please do this only in test environments!
Now we reopen it:
And we get the following error:

In order to recover the database after an inconsistent shutdown we must recover each datafile using its number:

Once we have recovered each one of the datafiles we are able to finally open the db reissuing :
Now we can finally check in our current value of the identity column, using the same trick I explained in part 1 by checking the Oracle Sequence:
SELECT CHINOOK.ISEQ$$_85607.currval FROM DUAL;

As you can see we have jumped 50 numbers, exactly the cache value.
Let's also do an example of changing the CACHE parameter, again this is a simple alter table modify operation:
alter table chinook.supplier modify SupplierId GENERATED BY DEFAULT AS IDENTITY NOCACHE;

That's it, now the identity column won't use a cache anymore, very easy.
PostgreSQL
We have already seen in part 1 that PostgreSQL has a peculiar way to handle cache for identity columns and sequences. In PostgreSQL multiple sessions that insert values in the table each use their own cache pool. I already demonstrated this, but that means that any time that the session is closed and a new one is opened we have a gap, even without a shutdown no matter if it is consistent or inconsistent.
Let's look at an example. Before we insert a new row in supplier table, first we will set the increment back to 1:
alter table supplier alter column supplierid set increment by 1
insert into supplier (companyname,vatcode,Address,city,country,email)
values ('EMI Austria','123456789', 'Klinghofer Strasse, 2', 'Wien','Austria','[email protected]');
And check our table:
select * from supplier;

Yes, I know that we played a little bit more with PostgreSQL data as shown above from the previous tip!
Now we just close the session and open a new one and issue a NEXTVAL like we did in part 1 of the tip:
select nextval(pg_get_serial_sequence('supplier','supplierid'))

Again we jumped the 50 values in the cache. So with PostgreSQL gaps are not a possibility, but almost certainty and that is valid both for identity columns and sequences.
Change an Existing Column to an Identity Column
As I mentioned in part 1, it is very easy to add an identity column to an existing table if we just add a new column, but what if we'd like to take an existing column and turn it into and identity? That could be tricky if we want to correctly preserve the values already stored in it.
SQL Server
In SQL server there is no direct way to accomplish this task, but we have a workaround.
It is possible to create a new separate table with an identity column and the same structure of the one in which we want to modify the column, then set IDENTITY_INSERT ON and copy all data from old table to the new one and finally delete the old table and rename the new one. Obviously, this solution is subjectable to the existence of Foreign Key references on the table (you will need to drop the constraints in order to delete the old table).
So, let's say we want to modify the ArtistId column in table Artist into and identity column, so first we create a new table Temp_Artist with the CREATE TABLE statement:
CREATE TABLE Temp_Artist( ArtistId int identity(1,1) NOT NULL, -- starting value of 1 and a seed value of 1 [Name] nvarchar(120) NULL, CONSTRAINT [PK_Artist_new] PRIMARY KEY CLUSTERED (ArtistId ASC))
Now we set IDENTITY_INSERT to ON:
set identity_insert Temp_Artist on
And we can now copy the values from one table to the other:
insert into Temp_Artist(Artistid, name) select Artistid, name from Artist

Let's check the values in our new table:
select * from temp_artist

Since everything seems fine we can drop the table Artist:
drop table artist

As expected, we cannot drop it because there is a Foriegn Key referencing this table, so we must first drop the constraint, using the stored procedure SP_FKEYS we can check which constraint is referencing table Artist:
EXEC sp_fkeys @pktable_name = 'Artist'

In this way we can see that ArtistId column is referenced by constraint FK_AlbumArtistId and we can drop it and we will then create it again once we have finished and renamed the new table:
alter table album drop constraint FK_AlbumArtistId
Now we can finally drop the old table:
drop table artist

And rename the new, for this purpose we will use the SP_RENAME stored procedure:
EXEC sp_rename 'Temp_Artist', 'Artist';
And create the FK constraint that we dropped:
ALTER TABLE [dbo].[Album] WITH NOCHECK ADD CONSTRAINT [FK_AlbumArtistId] FOREIGN KEY([ArtistId]) REFERENCES [dbo].[Artist]([ArtistId]) ALTER TABLE [dbo].[Album] CHECK CONSTRAINT [FK_AlbumArtistId]

And then check the table's identity column using IDENT_CURRENT:
select ident_current('Artist')
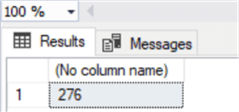
And it's done, with a simple workaround we have transformed an existing column into an identity one, preserving the values already stored.
Oracle
In Oracle we have the same exact behavior as in SQL Server, so in order to modify an existing column into an identity column we follow the same workaround, so first we create the new table:
CREATE TABLE CHINOOK.TEMP_ARTIST (ARTISTID NUMBER GENERATED BY DEFAULT AS IDENTITY (START WITH 1 INCREMENT BY 1 CACHE 50) NOT NULL ENABLE, NAME VARCHAR2(120 BYTE), CONSTRAINT PK_TEMP_ARTIST PRIMARY KEY (ARTISTID));
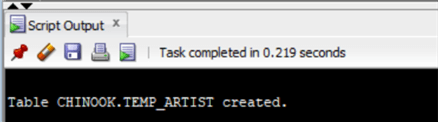
We can now insert into the new table as we've set the identity column as generated by default:
insert into CHINOOK.TEMP_ARTIST (ArtistId, name) select ArtistId, name from chinook.artist; commit;

Drop the constraint on table Artist, in order to retrieve the references to a table in Oracle there is a simple query making use of the table DBA_CONSTRAINTS:
with foreign_key as
(SELECT c.constraint_name, c.r_constraint_name, c.table_name
FROM dba_constraints c
WHERE constraint_type='R')
SELECT FOREIGN_KEY.table_name,foreign_key.constraint_name as "Constraint Name",
D.TABLE_NAME AS referenced_table_name,d.constraint_name as "Referenced PK"
FROM dba_constraints d inner join
foreign_key on d.constraint_name=foreign_key.r_constraint_name
WHERE D.table_name='ARTIST' AND D.OWNER='CHINOOK';

alter table chinook.album drop constraint FK_ALBUMARTISTID; drop table chinook.artist;

And we can finally rename our new table and create again the constraint, in Oracle it is possible to use statement ALTER TABLE RENAME in order to rename a table:
ALTER TABLE CHINOOK.TEMP_ARTIST RENAME TO artist;
alter table chinook.album add CONSTRAINT FK_ALBUMARTISTID FOREIGN KEY (ARTISTID)
REFERENCES CHINOOK.ARTIST (ARTISTID) ENABLE;
And let's check the value of our identity column:
select column_name, data_default from dba_tab_cols where owner= 'CHINOOK' AND table_name = 'ARTIST';

SELECT "CHINOOK"."ISEQ$$_87188".nextval FROM DUAL;

In Oracle we see that we need to set the identity column to start from the last value used:
select max(artistid) from chinook.artist;

alter table chinook.artist modify artistid generated always as identity (start with 277);
And we have finally setup our new identity column!
PostgreSQL
In PostgreSQL we have instead a different solution. It is possible to directly add an identity property to an existing column, preserving the values, so let's perform the same activity on PostgreSQL, changing ArtistID on table Artist, first of all let's check the max value of the column:
select max("ArtistId") from "Artist"

Now we can modify the column, using a normal ALTER TABLE ADD and specifying in the START WITH option the number we just obtained plus one:
ALTER TABLE "Artist" ALTER "ArtistId" ADD GENERATED ALWAYS AS IDENTITY (START WITH 277)

Now let's check the values inside the table:
select * from "Artist"

And check the nextval of our new identity column:
select nextval(pg_get_serial_sequence('"'||'Artist'||'"','ArtistId'))

That's it! In PostgreSQL this activity is easy and can be done directly without problems! Very Nice!
Conclusion
In this second part of this tip on Identity Columns we have seen the cache usage and the possible gaps problem and we've seen the various ways of modifying an existing column into an identity column along with preserving the values.
Next Steps
- As usual links to the official documentation:
- SQL Server: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-table-transact-sql-identity-property?view=sql-server-ver15
- Oracle:
- PostgreSQL :
- This is a link to the best possible explanation on Oracle sequences (and also Identity columns) including performance problems in RAC made by Oracle guru Jonathan Lewis: https://www.red-gate.com/simple-talk/databases/oracle-databases/oracle-sequences-the-basics/ It's a 4 part blog going deep also on the internals.
- Links to other tips regarding identity columns, first one has an important comment made by Aaron Bertrand:
- And why Gaps are unimportant (most of the times anyway) again by Aaron Bertrand: Five Things I Wish I Knew When I Started My SQL Server Career






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-12-29
