By: Nai Biao Zhou | Updated: 2021-12-23 | Comments | Related: > Python
Problem
Many IT professionals encounter more-or-less regular expressions at work; however, regular expressions are challenging (Cook, 2019). For example, this regular expression pattern /(\w+\.)*\w+@(\w+\.)+[A-Za-z]+/, which matches email addresses, seems intimidating at first glance. Even though we can use reference books to find the meaning of each token in the expression, to craft a regular expression to solve a real-world problem, we must understand regular expressions truly. We may not want to be regular expression gurus, but we need sufficient knowledge to tackle practical day-to-day pattern matching tasks.
Solution
As an essential part of an IT professional's toolkit, regular expressions (also called RegExes or regexes) can save us much development effort and headache when working on text-related tasks. However, writing RegExes is not easy. Many tutorials explain tokens \ parameters and syntaxes used in RegExes. However, we may find it is hard to memorize them. Furthermore, the syntaxes vary from programming language to programing language, i.e., there are several RegEx dialects. Therefore, we should understand how the RegExes work, which is the key to really understanding RegExes (Friedl, 2006). This article explores core features in most of these dialects and explains mechanisms in RegExes.
RegExes are a highly specialized programming language (Kuchline, 2021) rather than a declarative specification describing text patterns. We also often encounter the term "regular expression engine" (or "RegEx engine"), which refers to a piece of software that can process RegExes. RegExes, like other programming languages, can contain subroutines, functions, methods, loops, and conditions (Conway, 2017). Therefore, we interpret each token in a RegEx as a programming command. For example, the RegEx /SQL/ informs the engine to match the "S" character and match the "Q" character next and then match the "L" character. It is worth noting that we use the forward-slash characters to denote the boundaries of RegExes.
Most RegExes execute on their virtual machine. Theoretically, the virtual machine on which RegExes are executing is a finite state machine (FSM) (Nagy, 2018). A finite state machine, represented in a directed acyclic graph, is a finite set of states and transitions (Warford,2009). We represent the states by circles and symbolize transitions by arcs between the circles. Each arc, a directed link, contains an arrowhead to indicate the direction from beginning to end. We can use an FSM diagram to visualize how a RegEx works, which helps us know how the machine interprets the RegExes, converts them into executable code, and executes them.
Figure 1, an FSM diagram representing the RegEx /SQL, has a set of states: {Start, A, B, Match} (also called nodes). There is a transition from the Start state to the A state on the "S" path. The transition represents a token (i.e., an instruction) in the RegEx. Since the RegEx engine can move forward from the Start state to the A state following the "S" transition, we say the Start state has a forward transition. Similarly, the engine can move from the A state to the B state on the "Q" path and from the B state to the Match state on the "L" path. A state may have multiple forward transitions. The engine moves forward along one path until it reaches the Match state or cannot move forward. In practice, the engine may not work as described; however, the diagram helps us understand how RegExes work.

In the matching process, the RegEx engine consumes (or eats) characters in an input string. The engine moves forward along the FSM diagram when characters in the input string match tokens in the RegEx. If the engine has not reached the Match state but cannot move anywhere from its current state, it uses the backtracking algorithms to avoid getting stuck (Nagy, 2018). When using the backtracking algorithms, the engine moves backward along the followed path until it reaches a state with an alternative forwarding transition that it has not explored yet. A particular situation is that the engine might move back to the Start state and get stuck. In this case, the engine gives up the current character in the input string, moves to the next one, and starts a new match process.
To demonstrate the process, let us use the RegEx /SQL/ to test the "MSSQLtips.com" string:
- The RegEx engine always starts in the Start state and scans the first character in the input string. The engine scans the "M" character in the "MSSQLtips.com" string. The forward transition expects to encounter an "S" character. So, the engine cannot move forward, and backtracking occurs. The engine moves back to the Start state, and there is no alternative transition; therefore, the engine moves to the next character in the input string and starts a new match process. The engine remembers the start position in the input string.
- In the Start state, the engine scans the "S" character, the second character in the "MSSQLtips.com" string. The character matches the "S" transition. Therefore, the engine moves through the transition to the A state.
- In the A state, the engine scans the "S" character, the third character in the "MSSQLtips.com" string. Since the forward transition wants a "Q" character, the engine fails to move forward. Backtracking happens. The engine moves back to state A, but the state does not have another transition to move forward. Then, the engine moves back to the Start state and gets stuck. The engine gives up the second character in the input string and moves to the third character. The engine updates the start position in the input string in its memory.
- In the Start state, the engine scans the "S" character, the third character in the "MSSQLtips.com" string. The character matches the "S" transition. Hence, the engine moves along the transition to state A.
- In the A state, the engine scans the "Q" character. The character matches the "Q" transition. Thus, the engine moves through the transition to the B state.
- In the B state, the regular expression engine scans the "L" character. The character matches the "L" transition. Consequently, the engine moves through the transition to the Match state.
When the engine reaches the Match state, the string "MSSQLtips.com" successfully matches the regular expression /SQL/. In other words, we say that result of the matching process is True. In addition, we can access some information about this match, such as the matched string and the positions of the matched string. This example shows a successful match. However, the engine may scan every position in the input string and try every forward transition but cannot match. In this case, the match fails. In practice, RegEx engines may not follow this step-by-step process. We presented this process to emphasize that RegExes are just code and full of instructions. Therefore, we learn the RegExes just as we learn a new programming language, and we can apply our development skills to practice this language.
In the subsequent sections of this article, we first explore the Python "re" module, which supports RegExes. We then use the simple plain string "SQL" as a RegEx to match an input string and demonstrate the "match," "search," and "finditer" operations. To get a real taste of the excitement, we introduce the dot metacharacter that can match any character. When we need to match the actual dot character, the article shows how to use a backslash to escape metacharacters. We also briefly discuss using grouping constructs to break up a RegEx into groups and retrieve content captured by these groups. Next, to further show the real power of RegEx matching, we cover character classes and some of their frequently used shorthand.
As other programming languages do, RegExes have control structures, such as conditions and loops. However, the control structures in RegExes do not have any conditions. To make a loop work as anticipated, we cover the greedy, reluctant, and possessive quantifiers. To make RegExes understandable and maintainable, we introduce extended formatting. We explore other advanced topics, such as lookaround and anchors, to solve complex problems. Finally, we cover the backreferencing technique. Since parentheses used in grouping constructors can remember the matched text, we can use the early matched text to match the rest in the input string.
We test all the Python scripts used in this article with Microsoft Visual Studio Community 2022 and Python 3.9 (64-bit) on Windows 10 Home 10.0 <X64>. In addition, we create a Python virtual environment and install the Requests library, an elegant and simple HTTP library. We also use the online tool RegExr (https://regexr.com/) to test RegExes (Gskinner, 2021). The sample text used for analysis is from the "Contact Us" page on the Edgewood Solutions website (Edgewood, 2021).
1 – Introducing Regular Expressions in Python
Many computer programming languages, such as Java, C#, R, and Python, have RegExes implemented as a built-in feature. However, this article does not concentrate on any particular hosting language and RegEx syntaxes. Instead, we focus on the idea of RegExes, like Professor Papert, a pioneer of constructionist learning, said, "My central focus is not on the machine but on the mind." (Papert, 2020). However, we still need a specific example to support learning. Therefore, we design a simple Python web scraping project to practice RegExes. The project asks us to extract relevant information from the "Contact Us" page on the Edgewood Solutions website (Edgewood, 2021). First, we should get familiar with the "re" module that provides RegEx matching operations in Python.
1.1 Regular Expression Objects in Python
The Python re module provides many functions and methods to handle RegExes. We often use the method "re.compile()" to compile RegExes into pattern objects, then pass the pattern objects to other methods for matching operations. We can reuse these pattern objects for efficiency. Since RegExes may contain special characters, for example, backslash (‘\’), to avoid any confusion while dealing with RegExes in Python, we use Python’s raw string notation, for instance, "re.compile(r’SQL’)".
The "re.match()" and "re.search()" methods can take a pattern object and an input string to perform a search. If the engine finds a match, the two functions return a match object. Otherwise, they return a value of None. The match objects contain a wealth of information we want to extract from the input string. Furthermore, if we want to find all matches, we often use the method "re. finditer()" that returns an iterator yielding match objects over all non-overlapping matches (Python, 2021).
1.1.1 The Match Operation in Python RegEx
String matching is a common task in computer programming. For example, when we search for a file containing the string "SQL" at the beginning, we can use the "re.match()" method. This method searches only from the beginning of an input string and returns a match object if found. Nevertheless, if the matched substring is in the middle of the string, the method returns None. We say a match object is truthy because it is true in a Boolean context. This feature allows us to determine whether a match succeeds or fails quickly. To demonstrate how to use the "re.match()" method, let us run the following Python script in Visual Studio 2022 to search for the substrings "SQL" and "MS" in the input string "MSSQLTips."
import re
input_string = "MSSQLTips"
regex = re.compile(r"SQL")
match_obj = re.match(regex, input_string)
if match_obj:
print(match_obj)
else:
print("No match")
# Output
# No match
The output of the Python code indicates the match fails, even though the input string "MSSQLTips" contains the string "SQL." The reason is that the "re.match()" method searches for a match from the beginning of the input string; but, the input string starts with the "M" character. In addition, we observe that the Python code uses the match object as a condition in the Python if-statement. In this example, the match object acts as a value of false in the Boolean context. To exhibit the match object, we conduct another test that searches for the string "MS" in the input string "MSSQLTips."
import re
input_string = "MSSQLTips"
regex = re.compile(r"MS")
match_obj = re.match(regex, input_string)
if match_obj:
print(match_obj)
else:
print("No match")
# Output
# <re.Match object; span=(0, 2), match='MS'>
When the RegEx engine finds a match, the match object has a value of true in the Boolean context. The string representation of the match object indicates that the RegEx engine finds the first match at index 0, and the matched string is "MS." The method returns only the first matched occurrence in the input string and ignores others. We can extract some useful information from the match object. We use the Visual Studio 2022 Interactive window to execute the three methods of the match object. To make sense of the group () method, we cover "Capturing Groups" in a later section.
>>> match_obj.start() # returns the starting position of the match 0 >>> match_obj.end() # returns the ending position of the match 2 >>> match_obj.group() # returns the complete matched string 'MS' >>>
1.1.2 The Search Operation
The "re.search()" method, taking a RegEx pattern object and an input string, also searches for the first occurrence of the match within an input string. Unlike the "re.match()" method, the "re.search()" method checks for a match anywhere in the input string. If the search is successful, the method returns a match object or None otherwise. Since the match object is truthy, we can use an if-statement to test if the search succeeded. For example, we use the "re.search()" method to determine whether the string "SQL" is in the string "MSSQLTips" and the positions of the match.
import re
input_string = "MSSQLTips"
regex = re.compile(r"SQL")
match_obj = re.search(regex, input_string)
if match_obj:
print(match_obj)
print(match_obj.start())
print(match_obj.end())
print(match_obj.group())
else:
print("No match")
# Output
# <re.Match object; span=(2, 5), match='SQL'>
# 2
# 5
# SQL
1.1.3 The Finditer Operation
Both the "re.match()" and "re.search()" methods only return the first instance of the match in an input string. However, we may need to find all matches. The "re" module provides the method "finditer()" that returns a sequence of non-overlapping match instances as an iterator. The RegEx engine scans the input string from left to right, and all non-overlapping matches returned are sequential. For example, the following Python script finds all "S" characters in the input string "MSSQLTips" regardless of the case.
import re
input_string = "MSSQLTips"
regex = re.compile(r"S", re.I)
iterator = re.finditer(regex, input_string)
for match_obj in iterator:
print(match_obj)
print(match_obj.start())
print(match_obj.end())
print(match_obj.group())
# Output
# <re.Match object; span=(1, 2), match='S'>
# 1
# 2
# S
# <re.Match object; span=(2, 3), match='S'>
# 2
# 3
# S
# <re.Match object; span=(8, 9), match='s'>
# 8
# 9
# s
The output of the Python script indicates there are three matches in the input string. We can find the beginning position and the end position of every substring and the substring content. We modified the RegEx engine's default behavior by specifying a value to the flag when we compiled the RegEx. We use the flag "re.I" to tell the engine to perform case-insensitive matching. Some other flags are available to use, such as "re.X," which allow us to add comments to RegExes. We can use multiple flags simultaneously by combining them with the bitwise OR operator (i.e., the | operator).
1.2 Matching Literal Text
We demonstrated how to use the Python "re" module to execute RegExes and extract matched information. However, the RegExes in these examples are just plain strings. The real-world problems are more complicated than these examples. This section explores some other RegEx syntaxes, which can make us acclimated to writing simple RegExes. We use RegEx to analyze the "Contact Us" page on the Edgewood Solutions website (Edgewood, 2021). For the sake of brevity, we assign the text content on the page to a Python variable. We then use the value of the variable directly in the remainder of this section. We also omit the "import re" statement, but this statement is always necessary. We should run the following script before running other scripts in this section.
import re contact_us_page_content = """ Contact Us With consultants in New England and the Mid-Atlantic area, Edgewood Solutions offers the hands-on administration and database consulting services that will optimize any SQL Server system. We cater to companies of all sizes and industries. Whether your company has one SQL Server or 500, we have solutions and offerings that can work for you. We offer affordable solutions for both the short and long term, with on-site or remote assignments to meet your specific needs. For more information about Edgewood, please call 603-566-4928 or send an e-mail to [email protected] Sales: [email protected] Technical Support: [email protected] Career Opportunities: [email protected] Marketing: [email protected] Address Edgewood Solutions P.O. Box 682 Wilton, NH 03086 Phone: 603-566-4928 - NH Phone: 410-591-4683 - MD Fax: 603-590-5806 (Retrieved from https://www.edgewoodsolutions.com/about/) """
When a RegEx is a simple plain string, the RegEx engine compares the characters in the RegEx to the characters in the input string character-by-character. The real power of RegEx starts to emerge when the RegEx contains unknown characters. We use the dot character (i.e., ".") to match any character. For example, the RegEx /o.e/, illustrated in Figure 2, match "one," "ore," and "ote." This RegEx tells the engine to match an "o" character and next match any character then matches an "e" character. We use the following Python script to search if any non-overlapping three characters in the "Contact Us" page matches the pattern /o.e/. Note that we create a user-defined function.

Figure 2 Regular Expression /o.e/
# Create a user-defined function to print all matches
def find_all_matches(pattern_object, input_string):
'''
Take a pattern object and an input string.
Print all matches
'''
iterator = re.finditer(pattern_object, input_string)
match_num = 0
for match_obj in iterator:
match_num = match_num + 1
print ("Match {match_num} was found at {start}-{end}: {match}"
.format(
match_num = match_num,
start = match_obj.start(),
end = match_obj.end(),
match = match_obj.group()))
# Define the pattern object
regex = re.compile(r"o.e")
# Invoke the user-defined function
find_all_matches(regex, contact_us_page_content)
# Output
# Match 1 was found at 278-281: one
# Match 2 was found at 439-442: ote
# Match 3 was found at 489-492: ore
# Match 4 was found at 570-573: o@e
# Match 5 was found at 834-837: one
# Match 6 was found at 859-862: one
We found six matches on the "Contact Us" page. The substring "one," "ote," and "o@e" match the RegEx /o.e/. We also know the location of these substrings on the page, but we do not know which words contain these substrings. In another section of this article, we will provide a solution to identify all these words. In addition, we observe that the dot character also matches the character "@" that is non-alphanumeric. Strictly speaking, the dot character, acting as a wildcard, can match anything except a newline character (Fitzgerald, 2012).
1.2.2 Escaping Metacharacters
We used the dot character to match any character; therefore, the dot character has a special meaning in the RegEx. We call the dot character a metacharacter. There are some other metacharacters, and all of them are the building blocks of RegExes. By using metacharacters in RegExes, we can take advantage of the real power of RegEx. Below is a list of metacharacters we often use in writing RegExes (Kuchling, 2021):
. ^ $ * + ? { } [ ] \ | ( )
Because these metacharacters have special meanings in RegExes, we cannot use them to represent themselves. For example, if we need a token in RegExes to match a dot character, we should tell the engine that we want the actual dot character rather than any character. In this case, we can escape the dot character by preceding it with a backslash (\). However, the backslash itself is also a metacharacter. Therefore, when using an actual backslash (\) in RegExes, we can escape it with another backslash. Let us use an example to demonstrate how to escape a metacharacter. The following Python script searches for the first substring ".com" on the "Contact Us" page. If we do not escape the dot, the match is not ".com" but " com" because the dot matches a whitespace character.
regex = re.compile(r"\.com")
match_obj = re.search(regex, contact_us_page_content)
if match_obj:
print ("A match was found at {start}-{end}: {match}"
.format(
start = match_obj.start(),
end = match_obj.end(),
match = match_obj.group()))
else:
print("No match")
# Output
# A match was found at 585-589: .com
In the previous examples, we used RegExes to determine whether we found matches in the input strings. We also demonstrated how to read some useful information in the match objects. For example, the "group()" method returns the matched string. However, we may want to extract some substrings that are meaningful to us. Let us look at another example. The menu items on the top right of the "Contact Us" page link to several URLs, and one of them is "https://www.edgewoodsolutions.com/about/." When searching for the URLs on the page, we also want to know information about protocol, domain name, top-level domain (TLD), and route. That means we want to know those substrings that match the particular parts of the RegEx.
We can group a particular part of expression into a pair of parentheses. Then the RegEx engine captures the content that matches the particular group and stores it temporarily in memory. Next, we can retrieve the content from the match object. A pair of parentheses not only inform the RegEx engine to match the pattern inside the pair, but they also want the engine to remember the matched substring. The opening parenthesis signals to start remembering, and the closing parenthesis signals to stop remembering. Dr. Conway used a diagram, as shown in Figure 3, to illustrate how a capturing group works (Conway, 2017).

Figure 3 Capturing Group
We can use the plain text /https:\/\/www.edgewoodsolutions.com\/contact\// as a RegEx. In order to extract the protocol, domain name, top-level domain, and route from the match object, we put these corresponding parts of the RegEx into groups. Therefore, the updated RegEx looks like /(https):\/\/www.(edgewoodsolutions).(com)\/(about)\//. The following Python script first creates a user-defined function to print all matches and their corresponding groups. We will use this user-defined function in other sections. Next, the script creates a pattern object and invokes the user-defined function.
# Create a user-defined function to print all matches and their groups
def find_all_matches_and_groups(pattern_object, input_string):
'''
Take a pattern object and an input string.
Print all matches and groups
'''
iterator = re.finditer(pattern_object, input_string)
match_num = 0
for match_obj in iterator:
match_num = match_num + 1
print ("Match {match_num} was found at {start}-{end}: {match}"
.format(
match_num = match_num,
start = match_obj.start(),
end = match_obj.end(),
match = match_obj.group()))
for group_num in range(len(match_obj.groups())+1):
print ("Group {group_num} found at {start}-{end}: {group}"
.format(
group_num = group_num,
start = match_obj.start(group_num),
end = match_obj.end(group_num),
group = match_obj.group(group_num)))
# Define the pattern object
regex = re.compile(r"(https):\/\/www.(edgewoodsolutions).(com)\/(about)\/")
# Invoke the user-defined function
find_all_matches_and_groups(regex, contact_us_page_content)
# Output
# Match 1 was found at 917-957: https://www.edgewoodsolutions.com/about/
# Group 0 found at 917-957: https://www.edgewoodsolutions.com/about/
# Group 1 found at 917-922: https
# Group 2 found at 929-946: edgewoodsolutions
# Group 3 found at 947-950: com
# Group 4 found at 951-956: about
The match object’s groups() method returns a tuple that contains all the captured groups. We also observe that the group() method, which returns a single captured group, can take one argument. The argument is one-based. Therefore, group(1) returns the first captured group, group(2) returns the second and the like. However, group(0) does return a value, and it returns the fully matched string. We usually use the position of the opening parenthesis to determine the group index. We count the open parenthesis from the left side, and every open parenthesis adds one to the group index. Therefore, the first open parenthesis from the left side corresponds to the first group. The second open parenthesis from the left side corresponds to the second group and the like.
Nevertheless, there are limitations in maintaining this RegEx. For example, the index numbers may point to the wrong groups after adding a new group, such as a subdomain name group, to the RegEx. We can name a group by using the syntax (?P<name>pattern) to solve this problem. In this case, we access the captured groups through the group names. Another limitation is that we may use a pair of parentheses only for precedence, but these parentheses capture the substrings. In this case, we can define non-capturing parentheses by using the syntax (?:pattern). In addition, the nested groups also make the RegEx complicated.
To demonstrate how to use named groups, we re-write the RegEx:
regex = re.compile(r"(?P<protocol>https):\/\/www.(?P<domain>edgewoodsolutions).(?P<tld>com)\/(?P<route>about)\/")
group_names = ["protocol", "domain", "tld", "route"]
iterator = re.finditer(regex, contact_us_page_content)
match_num = 0
for match_obj in iterator:
match_num = match_num + 1
print ("Match {match_num} was found at {start}-{end}: {match}"
.format(
match_num = match_num,
start = match_obj.start(),
end = match_obj.end(),
match = match_obj.group()))
for group_name in group_names:
print ("Group {group_name} found at {start}-{end}: {group}"
.format(
group_name = group_name,
start = match_obj.start(group_name),
end = match_obj.end(group_name),
group = match_obj.group(group_name)))
# Output
# Match 1 was found at 917-957: https://www.edgewoodsolutions.com/about/
# Group protocol found at 917-922: https
# Group domain found at 929-946: edgewoodsolutions
# Group tld found at 947-950: com
# Group route found at 951-956: about
1.2.4 Matching Character Classes
We explored a RegEx syntax that uses alphanumeric characters to match characters in the input string. We also introduced the dot character that can match any character. These are two extreme cases, either matching exactly or matching anything. However, we often want to write a RegEx in which one of the characters in a character set matches a character in the input string. For example, we want to define a RegEx to match all phone numbers in an input string. We can use a character class to tell the engine to match only one of ten digits. The character class, also known as the character set, allows a RegEx engine to match a character successfully if the character is in the set (Lopez & Romero, 2014).
We use square brackets, "["and "]," to define a character set. Then, everything between them is part of the set. To have a successful match, one of the set members must match the corresponding character in the input string (Forta, 2018). For example, The RegEx /[0123456789][ 0123456789][ 0123456789]/ matches any sequence of three decimal digit characters. Likewise, the RegEx /[aeiou]/ matches any English vowels. Figure 4 illustrates the character set [SQL], which asks a character to match S, Q, or L. All the three transitions can lead the FSM to the same state.

Figure 4 The Character Class [SQL]
We can complement a character class by specifying ^ as the first character, in which case it matches any character that is not in the class. For instance, /[^0123456789]/ matches any character that is not a digit. When the number of characters in the character class is big, such as 26 lowercase letters, it is not efficient to place all possible characters inside the square brackets. Instead, we can use the hyphen symbol (-) between two related characters to define a consecutive span of letters or numbers. For example, [0-9] represents ten digital characters, and [a-z] represents 26 lowercase letters. Furthermore, if we want to define a character set containing both ten digits and 26 lowercase letters, we can combine these two ranges with this format: [0-9a-z].
The "Contact Us" page has some phone numbers and a fax number. We use a RegEx to extract all these numbers:
# Define the pattern object regex = re.compile(r"[0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]") # Invoke the user-defined function find_all_matches(regex, contact_us_page_content) # Output # Match 1 was found at 533-545: 603-566-4928 # Match 2 was found at 839-851: 603-566-4928 # Match 3 was found at 864-876: 410-591-4683 # Match 4 was found at 887-899: 603-590-5806
1.2.5 Matching Pre-defined Character Classes
We used the character class [0-9] to match any decimal digit and [^0-9] to match any non-digit character. There are some other classes that we use frequently and have meaningful names. For example, the class [a-zA-Z0-9_] matches any alphanumeric character, and the class [\t\n\r\f\v] matches any whitespace character. As we use these classes quite frequently, we prefer shorthand. Some of the special sequences beginning with "\" represent pre-defined sets of characters that are often useful, such as the set of digits (\d), the set of alphanumeric characters (\w), or the set of anything that is not whitespace (\S) (Kuching, 2021). For simplicity’s sake, we often use these special sequences as class shorthand so that the RegExes become maintainable.
| Predefined Character Class | Description |
|---|---|
| \d | Matches any decimal digit; this is equivalent to the class [0-9]. |
| \D | Matches any non-digit character; this is equivalent to the class [^0-9]. |
| \s | Matches any whitespace character; this is equivalent to the class [ \t\n\r\f\v]. |
| \S | Matches any non-whitespace character; this is equivalent to the class [^ \t\n\r\f\v]. |
| \w | Matches any alphanumeric character; this is equivalent to the class [a-zA-Z0-9_]. |
| \W | Matches any non-alphanumeric character; this is equivalent to the class [^a-zA-Z0-9_]. |
Table 1 Pre-defined Character Classes (Kuching, 2021)
Table 1 presents a list of pre-defined character classes we often use. We should know the RegEx syntax is case sensitive. The sequence "\D" acts opposite of "\d." The following code shows the simplified version of the RegEx that matches all phone numbers on the "Contact Us" page. While the RegEx looks concise, there still is room for improvement. We learn about repeating matches in the next section. Note that there are almost always multiple ways to define any RegEx (Forta, 2018). We pick syntaxes that should be easy to maintain.
regex = re.compile(r"\d\d\d-\d\d\d-\d\d\d\d")
2 – Regular Expression Control Structures
A computer programming language often has control structures that allow a program which is not limited to a linear sequence of instructions. For example, the program may execute a code block repeatedly or jump to other code blocks (Yse, 2020). The control structures usually include conditional statements or loop statements. As a programming language, RegExes have conditional statements (also known as alternations) and loop statements (also known as repetitions or quantifiers). However, the syntaxes of the control structures RegExes are different from other programming languages. A typical difference is that the control structures in RegExes do not have explicit conditions.
2.1 Alternations – The If Statements
We have shown a single execution path, illustrated in Figure 1. However, sometimes, we need two or more alternative execution paths. For example, we want to search for email addresses "[email protected]" and "[email protected]" on the "Contact Us" page because we want to replace them with another email address. We can use a RegEx alternation operator to split a RegEx into multiple alternatives (Goyvaerts & Levithan, 2012). The alternation operator, denoted with a vertical bar "|," means an "OR" operator. For example, the RegEx /(info|sales)@edgewoodsolutions.com/ can match the two email addresses. Figure 5 illustrates the RegEx. It is worth noting that the "|" operator always has the lowest precedence; therefore, it is best practice to put alternatives inside a pair of parentheses.
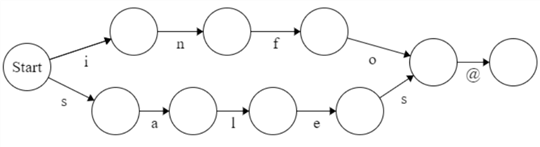
Figure 5 The FSM diagram for the RegEx /(info|sales)@edgewoodsolutions.com/
The RegEx engine scans the alternatives in a RegEx from left to right; it stops when it finds an alternative that matches. In this email example, the RegEx engine first matches the "i" token. If the match succeeds, the engine continues to match the "n" token. If the match fails, backtracking occurs, and the engine moves back to the previous state and tries an alternative path, i.e., the engine matches the "s" token. Unlike other programming languages, conditional statements do not check conditions first. Instead, the RegEx engine executes a statement and uses the execution result as a condition. If the execution fails in one path, the engine tries alternative paths.
The following Python script finds the two email addresses. Note that we use the syntax (?:pattern) when defining the alternation. The syntax defines a pair of non-capturing parentheses. If we do not use this syntax, the pair of parentheses captures a group and causes computational overhead.
# Define the pattern object regex = re.compile(r"(?:info|sales)@edgewoodsolutions.com") # Invoke the user-defined function find_all_matches_and_groups(regex, contact_us_page_content) # Output # Match 1 was found at 567-593: [email protected] # Group 0 found at 567-593: [email protected] # Match 2 was found at 602-629: [email protected] # Group 0 found at 602-629: [email protected]
2.2 Repetitions – The Loop Structures
RegExes have loop structures, which can repeatedly execute a RegEx portion (Nield, 2019). Rather than using "for" or "while" keywords to define a loop, RegExes use a quantifier metacharacter (i.e., postfix operator) to follow a portion of a RegEx immediately and indicate how many times that portion must occur for the match to succeed (Sturtz, 2020). For example, the RegEx /s{m, n}/ allows the RegEx engine to match the token "s" at least m times and at most n times.
2.2.1 Zero or More Loop
In Section 1.2.1, we searched for three characters that match the RegEx /o.e/. However, we could not find the words that contain the three characters. The reason is that the length of these words is unknown. The word may start with the "o" character or any number of other alphabet letters. We want to tell the RegEx engine to match any number of alphabet letters, including zero, before matching the "o" character.
If we want a RegEx portion repeatedly matched, we place the "*" metacharacter immediately following the portion. The metacharacter "*" informs the engine to match zero or more instances of the portion. Therefore, we rewrite the RegEx as the following: /[^\Wo]*o\we\w*/. This RegEx matches all words that contain a substring /o\we/, where "\w" matches any alphanumeric character. In this example, we intentionally use the two mutually exclusive instructions, the character set [^\Wo] and the "o" character. In that case, the RegEx execution is easy to explain through an FSM diagram.
The character set [^\Wo] matches any alphanumeric characters except the "o" character. Let us explain this set using the set theory. First, we use A to denote a set containing all alphanumeric characters and use O to denote the "o" character. Then, we use the following algebraic derivation to explain the character set [^\Wo].
We re-run the Python script with the updated RegEx. The output, as shown in the following, exhibits the words that contain the three characters.
# Define the pattern object regex = re.compile(r"[^\Wo]*o\we\w*") # Invoke the user-defined function find_all_matches(regex, contact_us_page_content) # Output # Match 1 was found at 278-281: one # Match 2 was found at 436-442: remote # Match 3 was found at 488-492: more # Match 4 was found at 832-837: Phone # Match 5 was found at 857-862: Phone
Figure 6 illustrates an FSM diagram for the loop structure. When the RegEx engine encounters the postfix "*" that immediately follows the character set [^\Wo], the engine matches the character set as many times as possible until the match fails. The engine moves back to the same state in every successful match and scans the next character in the input string. The loop stops when the engine scans an "o" character because the match fails. Then, backtracking occurs, and the engine unwinds one loop and tries an alternative path represented by a dashed line. The dashed line with no label, representing a free transition, does not ask to match anything in the input string; it provides a path to exit the loop (Conway, 2017).

Figure 6 Zero or More Loop
2.2.2 Other Loop Syntaxes
We introduced the "*" quantifier that repeats the preceding RegEx portion as many as possible. However, sometimes we need to limit the number of repetitions. One fundamental loop syntax uses a quantifier to specify a minimum and a maximum number of allowable repetitions. The quantifier has the form {m,n} where m and n are nonnegative integers. The value of m should not be greater than n. When the value of m equals the value of n, we have a fixed repetition, in which the engine repeats the preceding RegEx portion m times. We can write the fixed repetition in this form: {m}. The quantifier "*" is equivalent to the quantifier {0,} where the quantifier with missing n allows for infinite repetitions. Table 2 presents some quantifiers we use frequently.
| Name | Syntax | Description | Equivalent |
|---|---|---|---|
| zero or more loop | * | Match zero or more occurrence of the preceding RegEx portion | {0,} |
| one or more loop | + | Match one or more occurrence of the preceding RegEx portion | {1,} |
| zero or one loop | ? | Match zero or one occurrence of the preceding RegEx portion | {0,1} |
Table 2 Regular Expression Quantifiers (Summerfield, 2009)
2.2.3 Greedy, Reluctant, and Possessive Quantifier
Since the loop structures do not define any condition explicitly and do not specify the number of repetitions precisely, sometimes, we get an undesired result. For example, we want to extract the base URL from the internet address "https://www.edgewoodsolutions.com/about/" using the RegEx /https:\/\/.+\//. We test the RegEx through RegErx.com (Gskinner, 2021). We expect that the matched string should be "https://www.edgewoodsolutions.com/" in the match object. However, as shown in Figure 7, the RegEx matches the entire URL string.

Figure 7 Test Greedy Quantifiers
By default, all quantifiers are greedy—they match as many characters as possible (Summerfield, 2009). Therefore, when matching the URL, the RegEx token /.+/ matches all characters following the substring "https://.". Then, because there is no more character in the input string, the RegEx engine fails to match the forward-slash token. Thus, backtracking occurs to allow the rest of the input string to match. The loop unwinds one iteration, and the engine backs off the input string by one character. Then, the engine tries an alternative path. In that case, the token /.+/ matches these characters "www.edgewoodsolutions.com/about" in the input string. After the engine traverse on the alternative free path, the token forward-slash matches the character forward-slash in the input string, as shown in Figure 8. Thus, the match succeeds, and the matched string is the entire URL.

Figure 8 Greedy Quantifier: The Loop on the Uppermost
Another interesting example is to extract year and month from a file name "file_name_20211130.csv" using the RegEx /.+(\d{6})/. We expect the group to capture the substring "202111," but it captures the substring "211130." The reason is that the loop /.+/ always matches any character as much as possible. We may not need this kind of greedy behavior. Instead, we may want the engine to match as little as possible. We call this kind of minimal match loop non-greedy, also known as reluctant or lazy. We can make any quantifier non-greedy by following it with the "?" symbol. Let us use the non-greedy loop and conduct another test through RegErx.com (Gskinner, 2021). The matched string shown in Figure 9 satisfies our requirement. We also can use the same technique to extract the year and month from the string "file_name_20211130.csv" using the RegEx /.+?(\d{6})/.

Figure 9 Test the Nongreedy Quantifier
When encountering a non-greedy quantifier, the RegEx engine reluctantly enters the loop. Instead, the engine always tries to match the token that immediately follows the loop. If there is a match, the engine exits the loop. Otherwise, the engine enters the loop and iterates one more time. Then, the engine continues to match the token that immediately follows the loop. The process repeats until the engine exits the loop or runs out of characters in the input string. Figure 10 illustrates the finite state machine diagram. The free transition is on the top, which indicates that the RegEx engine always wants to traverse the free transition first. When the match on the uppermost path fails, the engine will return to the state with loop transitions and add one more iteration.

Figure 10 Nongreedy Quantifier: Place the Free Path on the Uppermost
There is another type of quantifier, possessive quantifiers. The RegEx engine tries to match as many characters as possible with the possessive quantifiers, as greedy quantifiers do. However, when the token immediately following the loop fails in matching, the engine does not backtrack. In this case, the engine does not release characters to give the token immediately following the loop a chance to retry. Because the possessive quantifiers can make the engine fail earlier, using proper possessive quantifiers can improve the performance of the RegEx engine. However, the Python "re" module does not support possessive quantifiers.
3 – Advanced Regular Expressions
We have shown RegExes containing plain text characters (also called literal) and metacharacters. With literal text acting as the words and metacharacters as the grammar, we use these pieces together to achieve a particular goal (Friedl, 2006). We have witnessed the power of the metacharacters. This section explores more metacharacters for advanced uses. To make examples more practical, we analyze an HTML document extracted from an URL. First, we employ the following Python script to retrieve contents from a web page and store it into a variable.
import requests
res = requests.get("https://www.edgewoodsolutions.com/contact/")
contact_us_page_html = res.text
3.1 Extended Formatting
We presented the RegEx /(\w+\.)*\w+@(\w+\.)+[A-Za-z]+/ at the beginning of this article. Even though we know the meaning of every token in the RegEx, it may still take us some time to comprehend the expression. One reason is that the RegEx is density packed, and another reason is that there is no comment. We have challenges in maintaining this RegEx. Furthermore, RegExes which we encounter at work may be more complicated than this one. A RegEx becomes clean and readable if we add whitespace characters and comments. Moreover, a RegEx is more understandable if we can separate it into multiple lines. The extended formatting, prepending (?x) at the beginning of the RegEx, can arrange the RegEx for easy understanding.
The following script demonstrates how to use the extended formatting syntax. In the script, we add whitespace characters for the layout and add comments for explanation. The RegEx engine does not consider a whitespace character as a command in this format; therefore, the engine does not use the whitespace character to match anything. However, any whitespace character before the token (?x) still counts. Therefore, The token (?x) should always be at the beginning of the RegEx.
regex = re.compile(r'''(?x) # Enables extended formatting ( # The 1st group starts \w+ # Matches one-or-more word characters \. # Matches a literal dot )* # End of the 1st group. Matches the 1st group zero-or-more times \w+ # Matches one-or-more word characters @ # Matches the literal @ ( # The 2nd group starts \w+ # Matches one-or-more word characters \. # Matches a literal dot )+ # End of the 2nd group. Matches the 2nd group one-or-more times [A-Za-z]+ # Matches one or more alphabets ''') find_all_matches(regex, contact_us_page_html) # Output # Match 1 was found at 3157-3183: [email protected] # Match 2 was found at 3185-3211: [email protected] # Match 3 was found at 3278-3305: [email protected] # Match 4 was found at 3307-3334: [email protected] # Match 5 was found at 3392-3421: [email protected] # Match 6 was found at 3423-3452: [email protected] # Match 7 was found at 3513-3542: [email protected] # Match 8 was found at 3544-3573: [email protected] # Match 9 was found at 3617-3648: [email protected] # Match 10 was found at 3657-3688: [email protected]
The output indicates there are ten matches on the "Contact Us" page. However, there are only five different email addresses. The following HTML code shows that both the anchor attribute value and anchor text contain email addresses. The RegEx matches the same email addresses in these two places. To distinguish the email address in the anchor attribute value from the one in the corresponding anchor text, we use lookaround tokens to check the matched string's left side or right side to determine whether the match is successful or not.
<a href="mailto:[email protected]">[email protected]</a>
3.2 Lookahead and Lookbehind
In the previous example, we could not distinguish an email address in an anchor attribute value from one in an anchor text. However, the business requirements may ask us to extract email addresses from the anchor text only. Using RegEx lookaround assertions, we can create a context-sensitive RegEx that differentiates the two kinds of email addresses. In addition to matching an email address, the RegEx engine also checks the position of the matched string. In other words, the engine examines the preceding and trailing characters of the matched string, then declares the match succeeds or fails. Therefore, we can categorize lookaround assertions into two categories: lookahead and lookbehind.
Looking closely at the HTML code, we find that the email address in an anchor text lies between a right-angle bracket ">" and a left-angle bracket "<," while the email address in the attribute value is located between a colon and a double quote. The differences in positions allow us to differentiate the two email addresses that have the same characters. When we use lookaround assertions, the match does not consume (or eat) any character. Therefore, this position match, also known as a zero-width or zero-length assertion, does not change the current position in the input string but only asserts whether a match succeeds or fails.
A lookahead assertion informs the RegEx engine to see if the right side of the current position matches the assertion. Note that the engine only looks ahead to check the specified matching requirement; it does not consume any character in the input string and does not include the matched text in the match object. The syntax of the lookahead assertion is /(?=sub-expression)/. Although we use a pair of parentheses, the parentheses do not capture any group content. For example, the following Python script only extracts email addresses from the anchor text, and the lookahead assertion does not capture any group.
regex = re.compile(
r'''(?x) # Enables extended formatting
( # The 1st group starts
\w+ # Matches one-or-more word characters
\. # Matches a literal dot
)* # End of the 1st group. Matches the 1st group zero-or-more times
\w+ # Matches one-or-more word characters
@ # Matches a literal @
( # The 2nd group starts
\w+ # Matches one-or-more word characters
\. # Matches a literal dot
)+ # End of the 2nd group. Matches the 2nd group one-or-more times
[A-Za-z]+ # Matches one-or-more alphabets
(?=\<) # The left side should match <
''')
find_all_matches_and_groups(regex, contact_us_page_html)
# Output
# Match 1 was found at 3185-3211: [email protected]
# Group 0 found at 3185-3211: [email protected]
# Group 1 found at -1--1: None
# Group 2 found at 3190-3208: edgewoodsolutions.
# Match 2 was found at 3307-3334: [email protected]
# Group 0 found at 3307-3334: [email protected]
# Group 1 found at -1--1: None
# Group 2 found at 3313-3331: edgewoodsolutions.
# Match 3 was found at 3423-3452: [email protected]
# Group 0 found at 3423-3452: [email protected]
# Group 1 found at -1--1: None
# Group 2 found at 3431-3449: edgewoodsolutions.
# Match 4 was found at 3544-3573: [email protected]
# Group 0 found at 3544-3573: [email protected]
# Group 1 found at -1--1: None
# Group 2 found at 3552-3570: edgewoodsolutions.
# Match 5 was found at 3657-3688: [email protected]
# Group 0 found at 3657-3688: [email protected]
# Group 1 found at -1--1: None
# Group 2 found at 3667-3685: edgewoodsolutions.
We call the lookahead assertion used in this example the positive lookahead. As the example demonstrated, we want to find the email addresses that should have a left-angle bracket on the right side. Moreover, the matched string should not include the left-angle bracket. In addition, there is the negative lookahead assertion that is the opposite of the positive lookahead assertion. When using a negative lookahead assertion, we do not want the right side of the current position to match the assertion.
Let us use examples to compare the positive lookahead and the negative lookahead. The RegEx /S(?=Q)/ matches the second "S" character in the string "MSSQLTips" because the trailing character "Q" matches the lookahead token. Therefore, this RegEx uses positive lookahead. On the other hand, the RegEx /S(?!Q)/ matches the first "S" character in the string "MSSQLTips" because the trailing character "S" does not match the lookahead token. Therefore, this RegEx uses the negative lookahead.
Another type of lookaround is the lookbehind assertion, which tells the RegEx engine to look backward and see if the left side of the current position matches the sub-expression. The syntax of the lookbehind assertion is /(?<=sub-expression)/. So, for example, we can write the expression to match all email addresses in the anchor text by using the following lookbehind assertion:
regex = re.compile( r'''(?x) # Enables extended formatting (?<=\>) # The left side should match > ( # The 1st group starts \w+ # Matches one-or-more word characters \. # Matches a literal dot )* # End of the 1st group. Matches the 1st group zero or more times \w+ # Matches one-or-more word characters @ # Matches a literal @ ( # The 2nd group starts \w+ # Matches one-or-more word characters \. # Matches a literal dot )+ # End of the 2nd group. Matches the 2nd group one or more times [A-Za-z]+ # Matches one-or-more alphabets ''') find_all_matches_and_groups(regex, contact_us_page_html)
If using this RegEx to match the HTML document of the "Contact Us" page, we find the RegEx does not match the email address "[email protected]" because there are several white space characters in front of the email address, as shown in the following line of the HTML code. The RegEx lookbehind token does not match the character before the email address; therefore, it declares a failure. In other words, the position of the email address does not match the RegEx.
<a href="mailto:[email protected]">\r\n\t\t\t\t\[email protected]</a>
Like the Lookahead assertion, the lookbehind assertion also has two types: positive and negative lookbehind. The previous example is positive lookbehind, in which the RegEx engine searches for a right-angle bracket ">" in character immediately preceding the matched character. If the engine finds the right-angle bracket, it declares the match is successful; otherwise, it declares it fails. When using a negative lookahead assertion, the match is successful if the left side of the matched character does not match the expression in the lookahead structure.
Let us use examples to compare the positive lookbehind and the negative lookbehind. The RegEx /(?<=M)S/ matches the first "S" character in the string "MSSQLTips" because the preceding character "M" matches the lookbehind token. Therefore, this RegEx uses a positive lookbehind. On the other hand, the RegEx /(?<!M)S/ matches the second "S" character in the string "MSSQLTips" because the preceding character "S" does not match the lookbehind token. Therefore, this RegEx uses the negative lookbehind.
3.3 Anchors
We explored context-sensitive RegExes that inform the RegEx engine where matches should begin and where they should end. Using lookaround syntaxes, we can define the positions of the matched string in an input string. However, we often need to look at two particular positions, the beginning and the end. These are typical cases in practice, and the RegEx language provides shorthand for these two scenarios.
We can use the caret "^" and dollar "$" to mark the beginning and the end of an input string, respectively. In the multi-line mode, these two characters specify the beginning and end of lines, respectively. We call these two characters "anchors," which specify positions in the string where matches must occur. These anchors do not change the match position in the input string.
In addition, we can use the "\b" anchor to define word boundaries (strictly speaking, identifier boundaries). The character "b" stands for a boundary. When a character before the boundary is an identifier character, the character following the boundary must not be an identifier character. Likewise, if a character before the boundary is not an identifier character, the character following the boundary must be an identifier character. All these anchors belong to the family of regex tokens that do not consume any characters but assert something about the match.
3.2.1 String or Line Boundary
The syntax in HTML5 requires that the tag <!DOCTYPE html> should always be the first thing in an HTML document, and the last tag on the document should be </html>. We first use a RegEx to validate the "Contact Us" page. We want to check if the HTML document starts with the <!DOCTYPE html> tag. We use the caret "^" to specify that the matched string should be at the beginning of the string. We call this special metacharacter a boundary since they specify the position before a pattern. The following script uses to the string boundary /^/ to validate the "Contact Us" page, and the output indicate there is no match.
regex = re.compile(r'^',re.IGNORECASE)
match_obj = re.search(regex, contact_us_page_html)
if match_obj:
print(match_obj)
print(match_obj.start())
print(match_obj.end())
print(match_obj.group())
else:
print("No match")
# Output
# No match
Next, we use a RegEx to verify if the last tag on the "Contact Us" page is the closing tag </html> (Forta, 2018). We use the dollar "$" to specify that the matched string should be at the end of the string. A web page may have white space characters after the closing tag. Thus, we use /</HTML>\s*$/ to match any number of whitespace characters followed by the </html> tag. The output indicates there is a match. Therefore, we know the last tag on the "Contact Us" page is the closing tag </html>.
regex = re.compile(r'</HTML>\s*$',re.IGNORECASE)
match_obj = re.search(regex, contact_us_page_html)
if match_obj:
print(match_obj)
print(match_obj.start())
print(match_obj.end())
print(match_obj.group())
else:
print("No match")
# Output
# <re.Match object; span=(7302, 7309), match='</html>'>
# 7302
# 7309
# </html>
We may need to find matches in every line of a document. In this case, we can enable a multi-line mode that informs the RegEx engine to treat line breaks as string separators. Therefore, the caret "^" specifies the matched string that should be at the beginning of a line, and the dollar "$" specifies the matched string that should be at the end of a line. For example, we want to extract the phone numbers on the "Contact Us" page. The phone numbers are on the lines that start with the characters "Phone:" which differentiate the phone numbers from the fax number. Figure 11 shows the matches.

Figure 11 Using Line Boundaries
3.2.1 Word Boundary
If we want to count the number of definite articles "the" on the "Contact Us" page, the RegEx /[Tt]he/ seems to work for us. However, we find the RegEx also matches the characters "the" in words such as "Whether" and "their." Therefore, to match the word "the" in a text, the preceding and trailing characters of the string "the" should not be word characters. Like "^" and "$" specify boundaries of a string or line, we use the anchor "\b" to specify the word boundaries (strictly speaking, identifier boundaries). As shown in Figure 12, the RegEx does not match the characters "the" in the word "Whether" because the preceding character is "e" and the trailing character "r." Therefore, both do not match the word boundary /\b/.

Figure 12 Using Word Boundaries
3.4 Rematching Previous Captures Through Backreference
There are several email links on the "Contact Us" page. An HTML mailto link can redirect users to an email address, shown as the following HTML code. The "Contact Us" page uses the "href" attribute to point to an email address and display the email address in the anchor text. Therefore, users can either click on the mailto link and write an email right away or save the email address and write an email later. The two email addresses should be the same. Nevertheless, sometimes, web admins may forget to keep them synchronized. Therefore, we want to use a RegEx to validate the mailto links on the "Contact Us" page.
<a href="mailto:[email protected]">[email protected]</a>
We covered the RegEx, i.e., /(\w+\.)*\w+@(\w+\.)+[A-Za-z]+/, that match a valid email address. We adding non-capturing parentheses to avoid overhead, we have a updated version: /(?:\w+\.)*\w+@(?:\w+\.)+[A-Za-z]+/. To validate two email addresses in an HTML mailto link, we may think of using the RegEx twice, as shown in the following:
/<a href="mailto:((?:\w+\.)*\w+@(?:\w+\.)+[A-Za-z]+)"\>\s*((?:\w+\.)*\w+@(?:\w+\.)+[A-Za-z]+)\<\/a\>/
However, the test result shown in Figure 12 does not work as we expected. The email address in the "href" attribute should be the same as the email address in the anchor text. The RegEx's second sub-expression should match the same email address as the first sub-expression does. For example, when the first sub-expression matched the text "[email protected]," we want the second sub-expression to use the text "[email protected]" to match the rest input string. In other words, the second sub-expression should be the string matched by the earlier sub-expression in the RegEx.

Figure 13 A RegEx Matches Undesired Text
Section 1.2.3 explored capturing groups, which can remember matched text. RegEx backreferences allow the engine to use substrings in the earlier captured groups to match the later parts of the input string. Since we can assign a name to a capturing group, we can access a backreference either by the ordinal position of the capturing group in the RegEx or the name of a capturing group defined in the RegEx. We can define backreferences using the following syntaxes:
- Numbered Backreferences: \number
- Named Backreferences: \k<group_name >
Therefore, we can rewrite the RegEx for mailto link validation in the following:
Using the Numbered Backreferences: /<a href="mailto:((?:\w+\.)*\w+@(?:\w+\.)+[A-Za-z]+)"\>\s*\1\<\/a\>/ Using the Named Backreferences: /<a href="mailto:(?P<email>(?:\w+\.)*\w+@(?:\w+\.)+[A-Za-z]+)"\>\s*\k<email>\<\/a\>/

Figure 14 Test Backreferences
Summary
RegExes may seem challenging and intimidating. With the advent of using data analytics to provide insights, mastering RegExes can save us considerable development effort and headache when we work with text. RegExes are not as hard as we may think they are. RegExes are a programming language. Many valuable topics around RegExes have been covered in this article.
We started with a gentle introduction to RegExes by exploring the details of how finite state machines implement them. For example, we used an FSM diagram to demonstrate how the engine executes a RegEx. During a matching process, the RegEx engine consumes characters in an input string one at a time from left to right.
We then explored the Python "re" module and practiced the "match," "search," and "finditer" operations. With this module, we not only could determine whether an input string matches a RegEx, but we also could retrieve useful match information such as the matched text and the match positions.
Next, we moved to some powerful features of RegExes. We discussed the metacharacters, capturing groups, and character classes. We also explored the control structures of RegExes. Alternations and repetitions allow us to craft RegExes using our programming skills.
To make the RegEx maintainable, we covered extended formatting. We also discussed other advanced topics, such as lookahead, lookbehind, and anchors. Finally, we introduced the backreference technique that can use the text previously matched by capturing groups to match the rest in an input string.
Reference
Child, D. (2020). Regular Expressions Cheat Sheet. https://cheatography.com/davechild/cheat-sheets/regular-expressions.
Cook, D. J. (2019). Why are regular expressions difficult? http://www.johndcook.com/blog/2019/06/19/why-regex/.
Conway, D. (2017). Understanding Regular Expressions. Sebastopol, CA: O'Reilly Media.
Edgewood. (2021). Edgewood Solutions – Contact Us. https://www.edgewoodsolutions.com/contact.
Fitzgerald, M. (2012). Introducing Regular Expressions. Sebastopol, CA: O'Reilly Media.
Forta, B. (2018). Learning Regular Expressions. London, UK: Pearson Education.
Friedl, E. F. J. (2006). Mastering Regular Expressions, Third Edition. Sebastopol, CA: O'Reilly Media.
Goyvaerts, J. (2021). Regular-Expressions.info. https://www.regular-expressions.info/.
Gskinner. (2021). RegExr. https://regexr.com.
Kuchling, A. M. (2021). Regular Expression HOWTO. https://docs.python.org/3/howto/regex.html.
Levithan, S. & Goyvaerts, J. (2012). Regular Expressions Cookbook, 2nd Edition. Sebastopol, CA: O'Reilly Media.
Lopez, F. & Romero, V. (2014). Mastering Python Regular Expressions. Birmingham, UK.
Nagy, Z. (2018). Regex Quick Syntax Reference: Understanding and Using Regular Expressions. New York, NY: Apress.
Nield, T. (2019). An Introduction to Regular Expressions.Sebastopol, CA: O'Reilly Media.
Papert, S. (2020). Mindstorms: children, computers, and powerful ideas. New York, NY: Basic Books.
Python. (2021). re — Regular expression operations. https://docs.python.org/3/library/re.html.
Sturtz, J. (2020). Regular Expressions: Regexes in Python. https://realpython.com/regex-python/.
Summerfield, M. (2009). Programming in Python 3: A Complete Introduction to the Python Language, Second Edition. Boston, MA: Addison-Wesley.
Warford, J. S. (2009). Computer Systems Fourth Edition. Sudbury, MA: Jones & Bartlett Learning.
Yse, L. D. (2020). Essential Programming | Control Structures. https://towardsdatascience.com/essential-programming-control-structures-2e5e73285df4
Next Steps
- We may have a very shallow understanding of how RegExes work. When writing RegExes to solve a real-world problem, we may need to call someone for help. This article concentrated on introducing how the RegEx engine works rather than the RegEx syntaxes. The author recommends using a cheat sheet for quick reference. The author made this article simple at the expense of accuracy. The book "Learning Regular Expressions," written by Ben Forta, provides explanations, examples, and analysis of the regular expression syntaxes frequently used in practice. Damian Conway's course "Understanding Regular Expressions" explains in more depth how regular expressions work. The visual aids used in his course are very instructive. All these resources include plenty of examples. Learning by doing is always an effective method to study a programming language. We should practice these examples as much as we can.
- Check out these related tips:
- CRUD Operations in SQL Server using Python
- CRUD Operations on a SharePoint List using Python
- Learning Python in Visual Studio 2019
- Python Programming Tutorial with Top-Down Approach
- Recursive Programming Techniques using Python
- Using Python to Download Data from an HTML Table to an SQL Server Database






About the author
 Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.
Nai Biao Zhou is a Senior Software Developer with 20+ years of experience in software development, specializing in Data Warehousing, Business Intelligence, Data Mining and solution architecture design.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-12-23
