By: Maria Zakourdaev | Updated: 2022-03-17 | Comments (1) | Related: > Azure Synapse Analytics
Problem
A great business analyst is never saturated with data, she/he needs more and more. Data analysis frequently calls for data enrichment, to enhance the dataset we already have by adding extra information. Data enrichment makes our data more useful and helps to get deeper insights. Sometimes this data may be internal company data, but in other situations we search for third party data over the internet such as historic sales data, market research data, product data, pricing data, etc.
It's great when we find the data available in a download format, however, from time to time we may need to scrape data directly from an HTML website. The technique of importing information from a website is called web scraping or data scraping. Data Engineers have a lot of tools that can help with querying web data, such as Chrome plugins and Excel Power Query, but my favorite data manipulation tool is Python which we will use this in this tutorial.
Solution
I find Pandas to be the most useful library in Python. Pandas is a powerful and flexible open-source data analysis tool. Pandas makes it amazingly easy to scrape an HTML table ( <table> tag in HTML code ) from a web page directly into the DataFrame, two dimensional tabular data structure, similar to a database table.
For this tutorial I will use Azure Synapse Analytics, a unified data analytics service in Azure cloud, that helps Data Engineers load, explore and process data using either SQL or Spark engine. I will use Spark engine and query the data using Synapse Notebook, a web interface that can contain live code, text and visualizations.
Azure Spark Pool Configuration
First, we need to create a Spark Pool inside Synapse workspace. Here you can find tutorial on how to create a Spark Pool. Apache Spark in Azure Synapse Analytics has a lot of libraries for common data engineering, data exploration and visualizations. For this example, we will need an additional library lxml that does not come with Apache spark distribution. We will need to install it into our Spark pool. After installation, it will be available for all Notebooks using this Spark pool.
In order to install Python libraries, we need to create a requirements.txt file. It's a simple text file, like the one you see below. As an example, I have more than just the lxml library, but we will not use the other two in this example.

After file creation, navigate in the Azure Portal to Settings> Packages and upload your file to the Spark pool:

Reading the Data
Now we will open Azure Synapse Studio from Synapse Workspace and go to Develop section to create a new Notebook.


If you want to read more on Notebooks usage, you can use this tutorial.
I will load the libraries that I will use in this example. Fsspec requires the lxml package that we have installed in the previous step.

import pandas as pd from datetime import datetime import fsspec
As an example, we will use Country codes translation table from the HTML table on this page https://www.worlddata.info/countrycodes.php.
Pandas library has a nice function that reads all <table> objects from an HTML web page into a list we have called dfs. The table that we are interested in, is the first item in a list. We will access it as dfs[0] and print the data:
datasource_url = 'https://www.worlddata.info/countrycodes.php'
dfs = pd.read_html(datasource_url)
df = dfs[0]
df

Cleaning the Data
Accessing data was very easy but I will probably want to clean the data a little.
I will change all data to be lowercase because its easy to join lowercase data. We will also remove white spaces from the column titles. White spaces in a column title sometimes might break data manipulation logic.
#change all data to be lowercase df = df.applymap(lambda s:s.lower() if type(s) == str else s) #remove whitespaces from column names [df.rename(columns={col: ''.join(col.lower().split())}, inplace=True) for col in df.columns]

Saving the Data
I want to save the data to Azure Data Lake and make it available for anyone who will want to use it.
To save the data to Azure Data Lake I need to create a connection, called "linked service", in Azure Synapse Studio. This connection that will contain credentials we will use for storage access in a secure form. We will not need to provide credentials in the script in clear text.
We can add the linked service it from the "Manage" section. In the wizard you will need to provide the credentials for the container access.

In this example we will save the data in the csv format using dataframe.to_csv operator. If we want a different format, we can save the data in any format, like PARQUET using .to_parquet or to AVRO using https://github.com/ynqa/pandavro library.
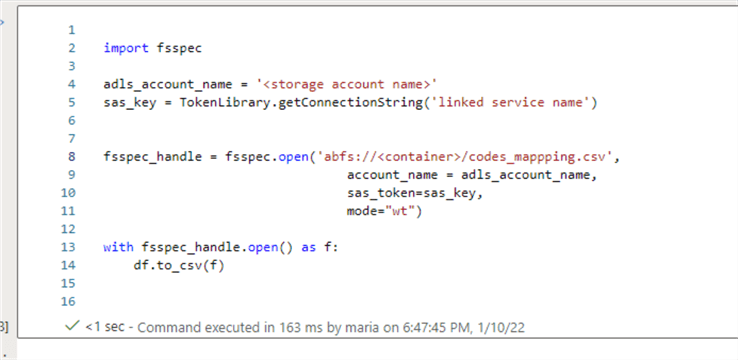
adls_account_name = '<Storage account name>'
sas_key = TokenLibrary.getConnectionString('Linked service name')
fsspec_handle = fsspec.open('abfs://country-codes/codes_mappping.csv',
account_name = adls_account_name,
sas_token=sas_key,
mode="wt")
with fsspec_handle.open() as f:
df.to_csv(f)
In the above example we have downloaded a dataset from a web page using Pandas Python library, cleaned the data and saved the result set to a csv file on Azure Data Lake Storage.
Next Steps
- Why use Python?
- Data exploration with Python and Sql Server using Jupyter Notebooks
- Data Engineering a Solution with Python and Sql Server






About the author
 Maria Zakourdaev has been working with SQL Server for more than 20 years. She is also managing other database technologies such as MySQL, PostgreSQL, Redis, RedShift, CouchBase and ElasticSearch.
Maria Zakourdaev has been working with SQL Server for more than 20 years. She is also managing other database technologies such as MySQL, PostgreSQL, Redis, RedShift, CouchBase and ElasticSearch.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-03-17
