By: Fikrat Azizov | Updated: 2022-04-15 | Comments (1) | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | > Azure Synapse Analytics
Problem
This tip is part of the series dedicated to the building of end-to-end Lakehouse solutions leveraging Azure Synapse Analytics. In the previous posts (see the links included at the bottom), we've explored various dimension-related challenges. In this tip, we're going to discuss the incremental processing challenges related to the fact tables.
Solution
Incremental ingestion approach
Fact tables are often the largest tables in the data warehouse because they contain historical data with millions of rows. A simple full data upload method for such tables will be slow and expensive. An incremental, timestamp-based upload would perform much better for large tables. The incremental method I'll be describing here is based on the timestamp columns reflecting the change-state of the rows. The essence of this idea is to split large data uploads into smaller, more manageable pipelines that fetch a subset of the data, based on certain date ranges. This split brings the following benefits:
- It ensures that data flow completes fast for a given date range.
- It eliminates unnecessary data upload for past times periods. In other words, we could upload historical data once and then upload regularly only recently changed data.
There's a slightly complicated version of this approach that covers cases when the table doesn't have timestamp columns, but it has a foreign key relationship to another table with timestamp columns.
The pipeline we'll be building here will fetch the fact data from the AdventureWorks database's SalesOrderHeader and SalesOrderDetail tables. My incremental logic will be based on the ModifiedDate timestamp column in the SalesOrderHeader table, and I'll rely on the foreign key relationship between SalesOrderHeader and SalesOrderDetail tables to ensure both tables are uploaded incrementally. This pipeline will be responsible for data transfer between Bronze and Silver layers, although the same logic can be applied to other parts of the ETL pipeline. To keep things tidy, I've split this discussion into two parts- part one explores the design of the child data flow responsible for data ingestion for a given date range, while part two covers the design of the parent pipeline that splits historical data into smaller time-periods and calls child pipeline for each period.
Inheriting initial ETL logic for the child flow
As mentioned earlier, this data flow will have two parallel streams (one for each table) and will include the incremental logic to replicate changes in the source. Let's start with the data flow DataflowBonzeSilver we discussed in this tip, which includes data deduplication logic. Here's a screenshot of the completed data:

Figure 1
This data flow is parameterized to be used for multiple tables. However, the incremental logic we're building here is hard to generalize, so we'll customize this flow for the needs of SalesOrderHeader and SalesOrderDetail tables and remove its table-related parameters. So, let's clone DataflowBonzeSilver data flow under the name DataflowBronzeSilver_SalesOrder, remove parameters SourceTableName, TargetTableName, PrimaryKey, TimestampColumn and add following string parameters:
| Name | Data type | Default value |
|---|---|---|
| WindowStart | string | '2008-06-07' |
| WindowEnd | string | '2008-06-15' |
It's worth mentioning that I've selected string parameter types for the date range because I found string parameters are easier to pass from the parent pipeline.
SalesOrderHeader stream design
Let's rename a Source transformation as SalesOrderHeaderBronze, and point it to the delta/bronze/SalesOrderHeader folder, as follows:

Figure 2
Next, add a Filter transformation named FilterTimeRange with the following condition:
ModifiedDate>=toTimestamp($WindowStart,'yyyy-MM-dd') && ModifiedDate <toTimestamp($WindowEnd,'yyyy-MM-dd')
This expression converts string parameters into a timestamp and excludes the rows outside the date range specified by parameters. Here's the screenshot:

Figure 3
Our next two transformations are responsible for deduplication. First, let's rename RankRowVersions as RankSalesOrderHeaders and specify the SalesOrderID column under its Over setting.

Figure 4
Next, navigate to the Sort tab, select DateInserted column and specify descending order, as follows:

Figure 5
Rename the next two transformations (Deduplicate and RemoveMetadataColumn) as follows, to indicate they belong to the SalesOrderHeaders stream:

Figure 6
Next, select SelectSalesOrderHeaders transformation, remove existing expression-based fields and add all of the columns from the SalesOrderHeaders table, as follows:

Figure 7
Because this data flow needs to update existing rows, we'll need to add Alter row transformation. Here's the required configuration for it:
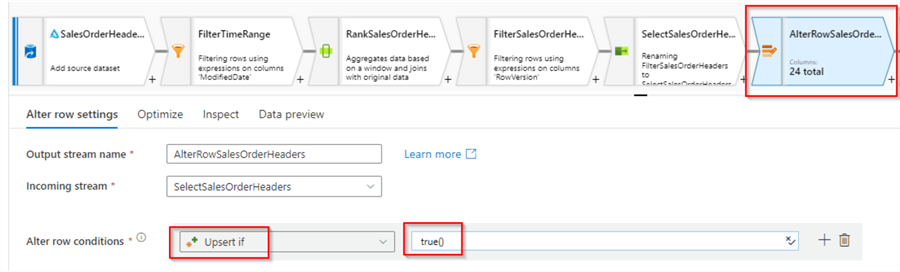
Figure 8
This expression will ensure that all new and updated rows are included in the output.
Finally, let's rename the sink transformation as SalesOrderHeaderSilver and point it to the delta/silver/SalesOrderHeader folder. Also, enable Allow upsert checkbox and select SalesOrderID as a key column. Here's the screenshot:

Figure 9
Now that we have data flow for the SalesOrderHeader table, we will add a similar stream for the SalesOrderDetail table.
SalesOrderDetail stream design
Let's add another source with Delta format, pointing to the delta/bronze/SalesOrderDetail folder. Here's the screenshot:

Figure 10
Next, add Exists transformation, select FilterTimeRange as a right stream and SalesorderID column as a key from both sides. This transformation will ensure indirect (through foreign key relationship) application of date range filter to SalesOrderDetail stream. Here's the screenshot:

Figure 11
Next, add a Window transformation, and include columns SalesOrderID and SalesOrderDetailID columns as keys, under the Over tab, as follows:

Figure 12
The next few transformations will have the same configurations as for the SalesOrderHeader stream, so let's add Filter, Select and Alter transformations and set them up accordingly. Here's the screenshot:

Figure 13
Finally, add sink transformation with the Delta format, point it to the delta/silver/SalesOrderDetail folder and configure its settings as follows:
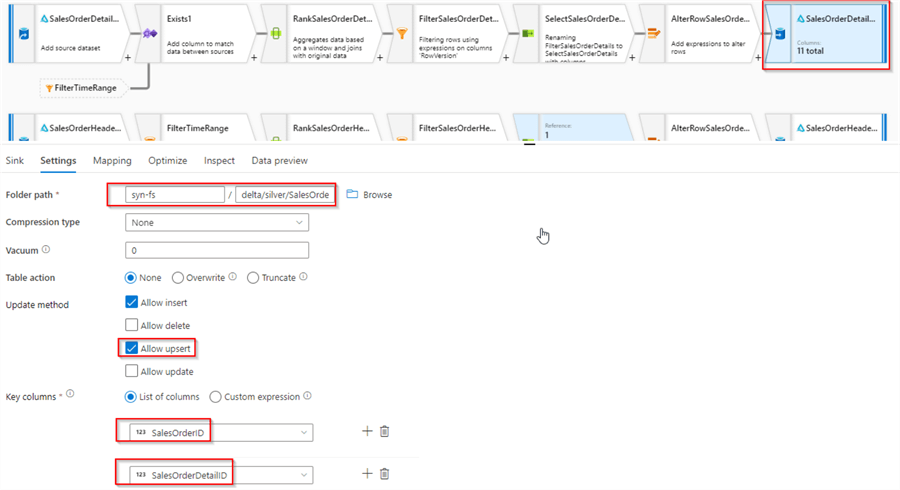
Figure 14
Here's a screenshot of the completed data:

Figure 15
We can validate it by enabling Debug mode, as follows:

Figure 16
Next Steps
- Read: Common Data Warehouse Development Challenges
- Read: Implementing data deduplication in Lakehouse using Synapse Analytics Mapping Data Flow
- Read: Mapping data flows in Azure Data Factory






About the author
 Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.
Fikrat Azizov has been working with SQL Server since 2002 and has earned two MCSE certifications. He’s currently working as a Solutions Architect at Slalom Canada.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-04-15
