By: Aaron Bertrand | Updated: 2023-10-11 | Comments (9) | Related: > SQL Server 2022
Problem
Every SQL Server release has new capabilities that are exciting to some group of customers – sometimes a change is introduced to please sysadmins, sometimes it's for finance, sometimes it's for customers of other platforms, and sometimes it's for developers. Now that the first public preview of SQL Server 2022 is available, I'll talk about some of the other new features in another post, but today I wanted to share a few of my favorite new features that will excite anyone who writes Transact-SQL.
Solution
I like to talk early about T-SQL enhancements because, unlike major features, they are largely baked in by the time the first public beta versions hit the shelves. They also aren't prone to further changes or renames by other Microsoft business units (like marketing).
A few of the most useful changes I've been able to play with in SQL Server 2022 so far:
- GREATEST / LEAST
- STRING_SPLIT
- DATE_BUCKET
- GENERATE_SERIES
In this tip, I'll explain each one, and show some practical use cases.
GREATEST / LEAST
Having covered them before, these functions are basically MAX and MIN, but across columns instead of across rows. A quick demonstration:
SELECT GREATEST(1, 5), -- returns 5
GREATEST(6, 2), -- returns 6
LEAST (1, 5), -- returns 1
LEAST (6, 2); -- returns 2
In this simple example, the logic is a lot like a CASE
expression. Taking just the first one:
SELECT CASE WHEN 1 > 5 THEN 1 ELSE 5 END;
When evaluating two expressions, it really is that simple: is the first one bigger than the second, or not? (However, keep NULL handling in mind; like MIN and MAX, both new functions also ignore NULLs.)
When you introduce a third value, though, it becomes much more complex. While the new syntax will offer:
SELECT GREATEST(1, 5, 3); -- returns 5
How we would write this as a CASE expression in
current and older versions is tedious:
SELECT CASE
WHEN 1 > 5 THEN
CASE WHEN 1 > 3 THEN 1 ELSE 3 END
ELSE
CASE WHEN 5 > 3 THEN 5 ELSE 3 END
END;
And it gets much worse from there, as you can imagine. I'm not even going
to try typing out what that spiderweb of CASE expressions
would look like when comparing 4 or more values.
But let's look at a real problem, because it's hard to feign complexity when we're talking about things we can easily do in our head. Picture a table like this, that holds a row for each year, and monthly sales figure columns (we'll just have three months to keep it simple):
CREATE TABLE dbo.SummarizedSales
(
Year int,
Jan int,
Feb int,
Mar int --,...
); INSERT dbo.SummarizedSales(Year, Jan, Feb, Mar)
VALUES
(2021, 55000, 81000, 74000),
(2022, 60000, 92000, 86000);
If we want to return the lowest and highest sales figure for each year, we could
write nasty CASE expressions (again, just imagine
that if we had all the months):
SELECT Year, BestMonth = CASE
WHEN Jan > Feb THEN
CASE WHEN Jan > Mar THEN Jan ELSE Mar END
ELSE
CASE WHEN Mar > Feb THEN Mar ELSE Feb END
END, WorstMonth = CASE
WHEN Jan < Feb THEN
CASE WHEN Jan < Mar THEN Jan ELSE Mar END
ELSE
CASE WHEN Mar < Feb THEN Mar ELSE Feb END
END FROM dbo.SummarizedSales;
Output:
Year BestMonth WorstMonth
---- --------- ----------
2021 81000 55000
2022 92000 60000
There are a couple of other ways to solve this problem, that at least scale better
without complicating the code exponentially. Here's one way using
UNPIVOT:
SELECT Year,
BestMonth = MAX(Months.MonthlyTotal),
WorstMonth = MIN(Months.MonthlyTotal)
FROM dbo.SummarizedSales AS s
UNPIVOT
(
MonthlyTotal FOR [Month] IN ([Jan],[Feb],[Mar])
) AS Months
GROUP BY Year;
And here's one using CROSS APPLY:
SELECT Year,
BestMonth = MAX(MonthlyTotal),
WorstMonth = MIN(MonthlyTotal)
FROM
(
SELECT s.Year, Months.MonthlyTotal
FROM dbo.SummarizedSales AS s
CROSS APPLY (VALUES([Jan]),([Feb]),([Mar])) AS [Months](MonthlyTotal)
) AS Sales
GROUP BY Year;
Those are easier to expand to cover more columns, but they're still tedious, and I don't like that both use transpose and grouping operations. Now we can perform this kind of task with ease:
SELECT Year,
BestMonth = GREATEST([Jan],[Feb],[Mar]),
WorstMonth = LEAST ([Jan],[Feb],[Mar])
FROM dbo.SummarizedSales;
STRING_SPLIT
I wrote about the enable_ordinal enhancement to this function in this tip, but I wanted to mention it again because, at the time, I could not confirm the change would make it into SQL Server 2022. Now I can, and I wanted to mention a few use cases where having the ordinal is beneficial:
Determining the nth item in a comma-separated list
I've seen many requests to return the 2nd
or 3rd item in a list, which
was cumbersome to do with STRING_SPLIT before because
the output order was not guaranteed. Instead, you'd see more verbose solutions
with
OPENJSON or tricks with PARSENAME. With
this new parameter, I can simply say:
DECLARE @list nvarchar(max) = N'35, Bugatti, 89, Astley'; SELECT value FROM STRING_SPLIT(@list, N',', 1) WHERE ordinal = 2; -- output is now guaranteed to be Bugatti
Joining to ordered data based on position in list
Let's say you want to assign new listings to salespeople based on past performance. You have this table:
CREATE TABLE dbo.SalesLeaderBoard
(
SalesPersonID int,
SalesSoFar int
); INSERT dbo.SalesLeaderBoard(SalesPersonID, SalesSoFar)
VALUES(1,2),(2,7),(3,8),(4,5),(5,1),(6,12);
And now you have a set of new listings that have come in, ranked by preference:
DECLARE @NewListings varchar(max) = '81,76, 80';
In this case, we'd want to assign the most preferential listing (81) to
salesperson 6, the second listing (76) to salesperson 3, and the third (80) to salesperson
2. Having a meaningful and reliable ordinal output
makes this easy:
SELECT Leaders.SalesPersonID, Listing = Listings.value
FROM STRING_SPLIT(@NewListings, ',', 1) AS Listings
INNER JOIN
(
SELECT TOP (3) SalesPersonID,
Ranking = ROW_NUMBER() OVER
(ORDER BY SalesSoFar DESC, SalesPersonID)
-- tie-breaker: seniority ---^^^^^^^^^^^^^
FROM dbo.SalesLeaderBoard
ORDER BY SalesSoFar DESC
) AS Leaders
ON Listings.ordinal = Leaders.Ranking;
Output:
SalesPersonID Listing
------------- -------
6 81
3 76
2 80
Reconstructing strings and preserving order
Another scenario I've dealt with in a tedious way is reconstructing a string to remove duplicates. Let's say we have a string like this:
Bravo/Alpha/Bravo/Tango/Delta/Bravo/Alpha/Delta
We want to remove duplicates from the list, but also maintain the original order, making the desired output:
Bravo/Alpha/Tango/Delta
With this new functionality we can accurately rebuild the string in a very direct
way by taking the first instance of any string in the list, and then using its overall
ordinal position to define the ordering used by STRING_AGG:
DECLARE @List nvarchar(max), @Delim nchar(1) = N'/'; SET @List = N'Bravo/Alpha/Bravo/Tango/Delta/Bravo/Alpha/Delta'; SELECT STRING_AGG(value, N'/') WITHIN GROUP (ORDER BY ordinal)
FROM
(
SELECT value, ordinal = MIN(ordinal)
FROM STRING_SPLIT(@List, @Delim, 1)
GROUP BY value
) AS src;
Output:
Bravo/Alpha/Tango/Delta
That is a much simpler approach than any of the awkward solutions I've used in the past.
That all said…
STRING_SPLIT is unfortunately still limited by
a single-character delimiter, which I have addressed in
this previous tip. But the new enable_ordinal argument does simplify
some of the more frequent use cases that have traditionally required tiresome workarounds.
It also adds a performance benefit compared to current methods, because the optimizer
recognizes that the data is returned sorted. Meaning it won't always need
to explicitly add a sort operator in the plan if the data needs to be ordered by
ordinal. While the complex example above does require sorting, the following example
does not:
DECLARE @List varchar(max) = N'32,27,6,54'; SELECT value FROM STRING_SPLIT(@List, ',', 1)
ORDER BY ordinal;
Here is the plan:

DATE_BUCKET
This function collapses a date/time to a fixed interval, eliminating the need to round datetime values, extract date parts, perform wild conversions to and from other types like float, or make elaborate and unintuitive dateadd/datediff calculations (sometimes using magic dates from the past).
The arguments are:
DATE_BUCKET(<datepart>, <bucket_width>, <input date/time> [, <origin>])
The output is a date/time type (based on the input), but at an interval governed
by the datepart and bucket_width.
For example, if I wanted to simplify the output of a particular column so it just
gave me the month boundaries, I might have done this in the past:
SELECT name, modify_date,
MonthModified = DATEADD(MONTH, DATEDIFF(MONTH, '19000101', modify_date), '19000101')
FROM sys.all_objects;
Or this, on SQL Server 2012 or better:
SELECT name, modify_date,
MonthModified = DATEFROMPARTS(YEAR(modify_date), MONTH(modify_date), 1)
FROM sys.all_objects;
Now, in SQL Server 2022, I can do this:
SELECT name, modify_date,
MonthModified = DATE_BUCKET(MONTH, 1, modify_date)
FROM sys.all_objects;
All three of the above queries give me identical results:
name modify_date MonthModified
--------------------------- ----------------------- -----------------------
sp_MSalreadyhavegeneration 2022-04-05 17:46:02.420 2022-04-01 00:00:00.000
sp_MSwritemergeperfcounter 2022-04-05 17:46:15.410 2022-04-01 00:00:00.000
sp_drop_trusted_assembly 2022-04-05 17:45:32.097 2022-04-01 00:00:00.000
sp_replsetsyncstatus 2022-04-05 17:45:41.850 2022-04-01 00:00:00.000
sp_replshowcmds 2022-04-05 17:45:48.197 2022-04-01 00:00:00.000
…
Additionally, this might have better performance in some cases; since the function is order-preserving, there are cases where a sort can be avoided. Getting out of the system objects business, let's create a simpler table, and compare the plans generated by grouping:
DECLARE @t table(TheDate date PRIMARY KEY);
INSERT @t(TheDate) VALUES('20220701'),('20220702'),('20220703');
SELECT TheMonth = DATEFROMPARTS(YEAR(TheDate), MONTH(TheDate), 1),
TheCount = COUNT(*)
FROM @t GROUP BY DATEFROMPARTS(YEAR(TheDate), MONTH(TheDate), 1);
SELECT TheMonth = DATE_BUCKET(MONTH, 1, TheDate),
TheCount = COUNT(*)
FROM @t GROUP BY DATE_BUCKET(MONTH, 1, TheDate);
Here are the plans:

More importantly, the function allows me to do much more elaborate things, like segmenting data into 5-minute intervals:
DECLARE @Orders table(OrderID int, OrderDate datetime); INSERT @Orders(OrderID, OrderDate) VALUES (1,'20220501 00:03'),
(1,'20220501 00:04'), (1,'20220501 00:05'), (1,'20220501 00:06'),
(1,'20220501 00:07'), (1,'20220501 00:10'), (1,'20220501 00:11'); SELECT Interval = DATE_BUCKET(MINUTE, 5, OrderDate),
OrderCount = COUNT(*)
FROM @Orders
GROUP BY DATE_BUCKET(MINUTE, 5, OrderDate);
Output:
Interval OrderCount
----------------------- ----------
2022-05-01 00:00:00.000 2
2022-05-01 00:05:00.000 3
2022-05-01 00:10:00.000 2
Want 10-minute intervals? No problem. We can even pass a parameter or variable so we can adjust on the fly:
DECLARE @MinuteWindow tinyint = 10; SELECT Interval = DATE_BUCKET(MINUTE, @MinuteWindow, OrderDate),
OrderCount = COUNT(*)
FROM @Orders
GROUP BY DATE_BUCKET(MINUTE, @MinuteWindow, OrderDate);
Output:
Interval OrderCount
----------------------- ----------
2022-05-01 00:00:00.000 5
2022-05-01 00:10:00.000 2
Another thing I can do is vastly simplify week boundary calculations. Here is
a completely unintuitive and cryptic way to get the previous Saturday (regardless
of a user's SET DATEFIRST or
SET LANGUAGE settings):
DECLARE @d date = GETDATE(), @PrevSat date; SET @PrevSat = DATEADD(DAY, -(DATEPART(WEEKDAY, @d) + @@DATEFIRST) % 7, @d); SELECT @PrevSat;
If we know any Saturday in the past, like January 1st,
2000, we can simplify this as follows, by passing that date into the
origin parameter:
DECLARE @KnownSat date = '20000101'; SET @PrevSat = DATE_BUCKET(WEEK, 1, @d, @KnownSat); SELECT @PrevSat;
This gives the same answer (at the time of writing – Tuesday, May 24th, 2022 – this returned Saturday, May 21st, 2022). And, like above, if we have a bunch of data, we can use this same technique to filter or group based on any known weekday.
DECLARE @LawnServices table(CustomerID int, ServiceDate date); INSERT @LawnServices(CustomerID, ServiceDate) VALUES (1, '20220501'),
(1, '20220508'), (1, '20220516'), (1, '20220526'), (1, '20220603'),
(2, '20220501'), (2, '20220517'), (2, '20220527'), (1, '20220602'); DECLARE @KnownSat date = '20000101'; SELECT [Week] = DATE_BUCKET(WEEK, 1, ServiceDate, @KnownSat), Services = COUNT(*)
FROM @LawnServices
GROUP BY DATE_BUCKET(WEEK, 1, ServiceDate, @KnownSat);
Output:
Week Services
---------- ---------
2022-04-30 2
2022-05-07 1
2022-05-14 2
2022-05-21 2
2022-05-28 2
This is a much simpler way to segment data based on a non-standard work week. As another example, our team's on-call schedule at Stack Overflow cycles on Wednesdays, and I've already used this function to map out our future schedule.
GENERATE_SERIES
This function produces a set-based sequence of numeric values. It supplants cumbersome numbers tables, recursive CTEs, and other on-the-fly sequence generation techniques we've all used at one point or another.
The arguments are:
GENERATE_SERIES(<start>, <stop> [, <step>])
A couple of simple examples:
SELECT value FROM GENERATE_SERIES(1, 5); SELECT value FROM GENERATE_SERIES(1, 32, 7);
Output:
value
-----
1
2
3
4
5 value
-----
1
8
15
22
29
(Note that it won't include the
STOP
value, or anything near it, if the next
STEP
pushes past it.)
In previous versions, to generate a sequence of numbers like this, you would probably use a numbers table, or a recursive CTE like this:
WITH cte(n) AS
(
SELECT 1 UNION ALL
SELECT n + 1 FROM n WHERE n < 5
)
SELECT value = n /* or ((n-1)*7)+1 */ FROM cte;
GENERATE_SERIES has a clear advantage here in terms
of simplicity and, as we'll see in a moment, performance.
One downside during the early CTPs was that the function
was not order-preserving. This meant that if you tried to sort by
value, you would find a sort in the plan, whereas that has
been guarded against in many cases with the other functions mentioned above. For
this example:
SELECT value FROM GENERATE_SERIES(1, 5) ORDER BY value;
Here is the plan:
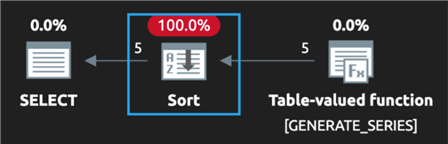
This was fixed in CTP 2.1.
With that fixed, this is a versatile function that will simplify code, and performs no worse than existing methods - and often better (some evidence).
BONUS
We can combine DATE_BUCKET and
GENERATE_SERIES to build a contiguous series of date/time
values. I often see people struggle to build a full data set when they are reporting
on intervals where not all intervals are populated. For example, I want hourly sales
figures across a day but, if we're selling something like cars, not every
hour will always contain a sale. Let's say we have this data:
CREATE TABLE dbo.Sales
(
OrderDateTime datetime,
Total decimal(12,2)
); INSERT dbo.Sales(OrderDateTime, Total) VALUES
('20220501 09:35', 21000), ('20220501 09:47', 30000),
('20220501 11:35', 23000), ('20220501 12:55', 32500),
('20220501 12:57', 16000), ('20220501 13:42', 17900),
('20220501 15:05', 20950), ('20220501 15:45', 24700),
('20220501 15:49', 18750), ('20220501 15:51', 21800);
If I want to find the hourly sales for business hours on May 1st, I might write this query:
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00'; SELECT OrderHour, HourlySales = SUM(Total)
FROM
(
SELECT Total,
OrderHour = DATEADD(HOUR, DATEDIFF(HOUR, @Start, OrderDateTime), @Start)
FROM dbo.Sales
WHERE OrderDateTime >= @Start
AND OrderDateTime < @End
) AS sq
GROUP BY OrderHour;
What I get:
OrderHour HourlySales
---------------- -----------
2022-05-01 09:00 51000.00
2022-05-01 11:00 23000.00
2022-05-01 12:00 48500.00
2022-05-01 13:00 17900.00
2022-05-01 15:00 86200.00
What I actually want is a row for each hour, even if there were no sales:
OrderHour HourlySales
---------------- -----------
2022-05-01 09:00 51000.00
2022-05-01 10:00 0.00
2022-05-01 11:00 23000.00
2022-05-01 12:00 48500.00
2022-05-01 13:00 17900.00
2022-05-01 14:00 0.00
2022-05-01 15:00 86200.00
2022-05-01 16:00 0.00
The typical way we'd start is with a simple recursive CTE that builds out all the possible rows in the range, and then performs a left join against the populated data.
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00'; ;WITH Hours(OrderHour) AS
(
SELECT @Start
UNION ALL
SELECT DATEADD(HOUR, 1, OrderHour)
FROM Hours WHERE OrderHour < @End
),
SalesData AS
(
SELECT OrderHour, HourlySales = SUM(Total)
FROM
(
SELECT Total,
OrderHour = DATEADD(HOUR, DATEDIFF(HOUR, @Start, OrderDateTime), @Start)
FROM dbo.Sales
WHERE OrderDateTime >= @Start
AND OrderDateTime < @End
) AS sq
GROUP BY OrderHour
)
SELECT OrderHour = h.OrderHour,
HourlySales = COALESCE(sd.HourlySales, 0)
FROM Hours AS h
LEFT OUTER JOIN SalesData AS sd
ON h.OrderHour = sd.OrderHour
WHERE h.OrderHour < @End;
The thing I like least about this solution is the awkward dateadd/datediff expression
to normalize date/time data to the top of the hour. Functions like
SMALLDATETIMEFROMPARTS are clearer in their intent,
but even more hassle to construct. Instead, I wanted to use
DATE_BUCKET and GENERATE_SERIES
to turn this whole query pattern on its head:
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00'; ;WITH Hours(OrderHour) AS
(
SELECT DATE_BUCKET(HOUR, 1, DATEADD(HOUR, gs.value, @Start))
FROM GENERATE_SERIES
(
START = 0,
STOP = DATEDIFF(HOUR, @Start, @End) – 1
) AS gs
)
SELECT h.OrderHour, HourlySales = COALESCE(SUM(Total),0)
FROM Hours AS h
LEFT OUTER JOIN dbo.Sales AS s
ON h.OrderHour = DATE_BUCKET(HOUR, 1, s.OrderDateTime)
/* -- alternatively:
ON s.OrderDateTime >= h.OrderHour
AND s.OrderDateTime < DATEADD(HOUR, 1, h.OrderHour) */
GROUP BY h.OrderHour;
I see great potential in both functions to help simplify logic and reduce dependencies on helper objects.
Honorable Mentions
There are a few other T-SQL enhancements coming in SQL Server 2022, but I'm going to leave them for Itzik Ben-Gan to tell you about in this article:
- WINDOW clause
- NULL treatment clause (IGNORE NULLS | RESPECT NULLS)
Next Steps
Note that many of the features that eventually make it into a major release of SQL Server first appear in Azure SQL Database and/or Azure SQL Edge. In fact, most of the functions above were available in those flavors months ago. You don't necessarily have to wait for a public preview to kick the tires on new syntax. But for SQL Server 2022 specifically, the first builds available for CTP 2.0 are only for Windows.
Now that it's here, though, go grab the CTP, see the "What's New" documentation, and grab Bob Ward's demos.
In the meantime, see these tips and other resources:
- T-SQL Windowing Improvements in SQL Server 2022
- SQL Server 2022 Resources
- Get Ready for SQL Server 2022
- Using GREATEST and LEAST functions in Azure SQL Database
- Find MAX value from multiple columns in a SQL Server table
- Trusting STRING_SPLIT() order in Azure SQL Database
- Ordered String Splitting in SQL Server with OPENJSON
- Removing Duplicates from Strings in SQL Server
- How to Expand a Range of Dates into Rows using a SQL Server Numbers Table
- SQL Server Function to return a range of dates
- The SQL Server Numbers Table, Explained - Part 1
- The SQL Server Numbers Table, Explained - Part 2






About the author
 Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.
Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He is editor-in-chief of the performance-related blog, SQLPerformance.com, and also blogs at sqlblog.org.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-10-11
