By: Koen Verbeeck | Updated: 2022-06-22 | Comments | Related: More > Import and Export
Problem
As often happens in changing industries, new terminology is introduced to describe certain features or products. "Data pipeline" is such a terminology that has been on the rise since data science and data engineering have become more popular. But what is a data pipeline exactly? And how does it differ from an ETL workflow?
Solution
Like most terminology in the IT sector, there isn't a strict definition of what a data pipeline exactly is. If you ask 10 people what a data pipeline is, you might get 10 different – but hopefully related – answers. What most definitions have in common is that a data pipeline has a data source (which can be anything: on-premises relational databases, raw data files, streaming data from IoT devices and so on), a destination (typically a data lake or a data warehouse) and some optional processing steps (where data is transformed, manipulated, and changed). Yes, this seems very similar to the definition of an ETL process (Extract, Transform, Load).

In many cases, the term ETL or data pipeline can be used interchangeably. Depending on their background, some people see ETL as a subset of data pipelines, while other people see it exactly the other way around.
Data Pipelines vs ETL Pipelines
Most of the time, the difference between data pipelines and ETL processes is merely the context. ETL is typically used in the context of business intelligence and data warehousing context. Sometimes – and this may be a subjective opinion – it's used to indicate "older tools" such as Integration Services (SSIS). Data pipelines on the other hand are usually found in the context of data engineering and data science. ETL has been around for quite some time but using "data pipelines" as a term has only been around for a couple of years. In the Microsoft Data Platform stack, this has been popularized by Azure Data Factory (ADF) which uses pipelines as the main building block for data management automation.

Data engineering itself is also a term that is quite new. It refers to the practice where engineers design and build the data pipelines to transform the data into a format that is usable by end users such as the data scientists. Typically, data engineering is more code-heavy than traditional ETL processes and several software engineering practices are applied, such as tight integration with source control and the use of CI/CD processes to deliver the code. Data engineering and data pipelines are often used in the context of big data or streaming data, while ETL is usually associated with batch processing.
Difference in Data Pipeline Tools vs. ETL Tools
ETL processes are typically developed using one single tool. SSIS for example can handle the ingestion of data, the transformation using the different components in the data flow, and it also writes the data to a destination. It can also orchestrate other processes such as executing SQL statements in a database. The same can be done using ADF. ETL tools are typically very visual in nature, where you don't have to write much code.
A data pipeline can be build using one single tool as well – take Azure Databricks for example – but it's not uncommon that the data pipeline is managed by different tools. In the Azure Data Platform, one might ingest data to Azure Data Lake Storage using ADF, transform the data using Python notebooks in Azure Databricks and then pull the data into Azure Synapse Analytics. The following architectural diagram comes from the Microsoft documentation:
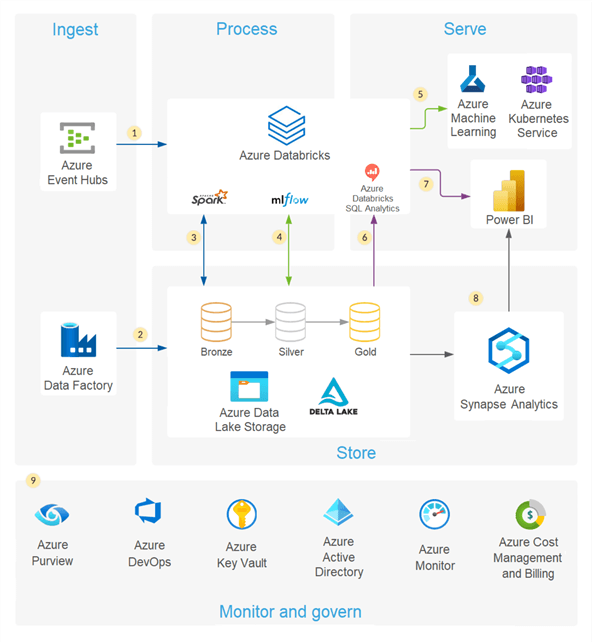
A data engineer who needs to create data pipelines doesn't need to understand one ETL tool and know how to write SQL; but rather they need to know how to write code in a couple of languages (e.g. SQL and Python), how to work with multiple tools (ADF, Event Hubs, Streaming Analytics, Cosmos DB, Synapse Analytics …), how to setup code repositories and how to integrate those with CI/CD pipelines, how to efficiently store and partition the data and so on.
Use Case - Data Pipelines and the Lambda Architecture
To deal with huge quantities of data, the lambda architecture takes advantage of both batch and streaming methods. In such an architecture, you have data pipelines that will process data using batches (the slow track) and data pipelines using streaming data (the fast track). From the Microsoft documentation on big data architectures:
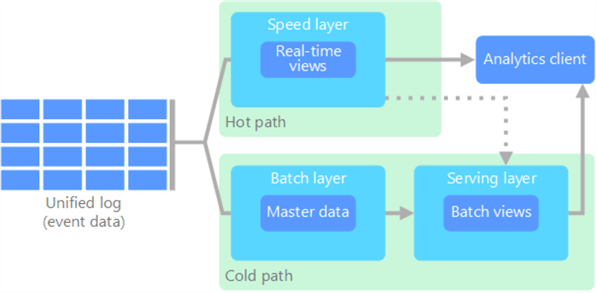
The batch layer (cold path in the figure) compromises data pipelines that follow the typical ETL processes. Data is extracted, transformed, and loaded on scheduled intervals. Because this introduces latency, a hot path is added where data pipelines using streaming technologies (such as Event Hubs, Kafka, Stream Analytics etc.) are used to process the data much faster (but maybe less accurate). For a unified results, the presentation layer can join results from both the fast and the slow track.
This means it's important to realize there can be different types of pipelines. Depending on the need, you might need to switch to other tools for data processing.
Conclusion
Data pipelines are processes that extract data, transform the data, and then write the dataset to a destination. In contrast with ETL, data pipelines are typically used to describe processes in the context of data engineering and big data. Usually, more code is involved and it's possible multiple tools or services are used to implement the pipeline. However, there are many similarities between ETL and data pipelines, so one might even conclude they're actually the same.
Next Steps
- Want to learn more about real-time data integration with SSIS and ADF? Check out the following tutorials:
- You can find a full overview of all the ADF resources here. And a similar overview for Azure Databricks can be found here.
- The tip Lambda Architecture in Azure for Batch Processing gives more detail on the lambda architecture in Azure.
- Next to ETL, there's also the pattern ELT. Learn more about it in the tip What's ELT?.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-06-22
