By: Koen Verbeeck | Updated: 2022-07-14 | Comments (2) | Related: More > Import and Export
Problem
I have been working in IT for some time now. I've done a bit of database development, data modeling, etc. and I've always enjoyed working with data. I've been thinking about taking up a Business Intelligence (BI) job as an ETL developer. What tasks, responsibilities and skillsets are needed in such a role?
Solution
For a definition of what ETL (Extract, Transform, Load) is, check out the tips What is ETL? and What is ELT?. In short, an ETL developer is a developer who creates data pipelines (see more in the tip What is a data pipeline?). These pipelines can either be created by using an ETL tool which is software specialized in creating such data flows, or by writing code. In this tip, we'll focus on ETL developers working with the Microsoft Data Platform when it's relevant.
Tasks and Responsibilities of an ETL Developer
Below are various tasks and responsibilities of an ETL Developer.
Extracting Data
The first thing an ETL needs to do is extract the data from one or more sources. Before a single line of code is written, or before we open the ETL tool, it's advised to do some analysis of the sources. Either the ETL developer does this in conjunction with a technical analyst, with the persons responsible for the source (for example, a database administrator) or both. Here are some questions you might ask yourself before you start extracting data:
- What kind of data are we extracting? Does it come from a well-defined source, such as a relational database, a SharePoint list, an OData source, a REST API …? Or does it come from an unstructured source, such as Excel files, CSV files, JSON files …?
- How do we connect to the data source? Do we need a specific adaptor, such as an ODBC provider? Do we need a 32-bit or 64-bit provider, or maybe both? Is the source located on-premises or in the cloud? Is there a firewall?
- Do we need to authenticate? Is there a username and password, or can we use something like Azure Active Directory? Or do we need to generate some access token? In many cases, a service principal needs to be created for the ETL process.
- When we've been able to connect to the data successfully, we need to ask ourselves if we need all the data. Is the ETL process going to copy all rows and all columns? Or do we only need a subset of the columns? Are we going to do an incremental load (meaning, we only take the rows that are new or have changed since the last load), or are we going to do full loads each time?
- In the case of incremental loads, is there some sort of change data capture at the source? Or is there a column with a "modified date"? And if there is, can we trust it? Sometimes, people do manual updates in the source, and they forgot to update the modified date, making the column useless.
- In the case of unstructured data, is the schema fixed, or is there some schema drift to be expected? And if yes, how do we anticipate this? Integration Services (SSIS) for example doesn't handle schema drift at all.
- What is the quality of the data? Are there NULL values? What are the data types? What is the locale of the source? For example, are dates written as dd/mm/yyyy, or as mm/dd/yyyy? What are the row and column delimiters of the flat file? Are quotes used around text if the delimiter appears in the data itself? Are they escaped properly if needed?
- When can we load the data? Are there specific intervals we must avoid so we don't put a burden on the source system?
- If we have loaded the data, do we need to archive something?
Typically, this is an iterative process. You try to connect to the data, poke around, get a feel of what the data looks like and then create a process to extract it. You might create a data flow in an Integration Services package, or you use the Copy Activity in Azure Data Factory (ADF). Another option is to write some code in an Azure Databricks notebook or use Azure Logic Apps or Azure Functions to extract the data.
Whatever the tool of choice, the ETL developer needs to make sure the code is robust. If the source is offline for example, it's possible to retry the extraction at a later point and if that fails, a notification should be sent. The code should also be idempotent. This means you should be able to run the code/package/function multiple times in a row, and the result should be the same.
Transforming Data
Once the desired data is available, the ETL developer can create/write transformations on this data. There are transformations that aren't specifically tied to business logic:
- Trimming data. Removing special characters from data.
- Replacing NULL values with something like "Missing", "Unknown" or "N/A".
- Converting to the correct data type, e.g. from a string to an integer or a date.
- Removing duplicate rows and other data quality checks
- Unpivoting/pivoting of data
Many transformations are directly tied to business logic. An example can be that you have to derive the "total sales" from the "quantity sold" and "unit price" columns: total sales = quantity * unit price. In most cases, you'll work together with an analyst or with someone with knowledge of the business process to define exactly which calculations need to be performed. This means more complicated transformations are possible:
- Data integration of multiple data sets. You can use UNION ALL to append data sets with the same schema, or you can use joins to merge data sets together. In SSIS, you have the similar UNION and MERGE JOIN transformations. However, performance in SSIS can be worse than in T-SQL because the data needs to be sorted in SSIS before you can join it. When joining data sets, you need to be careful when you're dealing with incremental loads. Suppose you're loading data from a table that is loaded incrementally. You need to join against another source table for extra data, and that other table is also incremental. What if the data for that reference table hasn't changed in a while? This would mean the staging table is empty, and your join will fail. In general, it's best to load transactional data (typically used for fact tables) incrementally but do a full load for referential data (typically used for dimensions).
- Sometimes you need logic where the outcome of the calculation depends on multiple rows. For example: if the customer hasn't made a purchase in the past 3 months, flag it so we can send an email. Or, customers who have spent over $100,000 last year are assigned to a "high tier", customers between $50,000 and $100,000 to a "middle tier" and everyone else to a "low tier". Such calculations can be done in SQL using window functions. You can find more info about them in this tutorial.
In many cases, the calculations can be done using T-SQL or a derived column in SSIS.
When you're working with Azure Data Factory, you cannot use the Copy Activity for transformations, with just a few exceptions:
- You can change the file format, for example from JSON to CSV. When the destination is a relational database, data types can be implicitly converted as well.
- If the data is compressed, it can be decompressed or the other way around.
- You can add additional static columns.
For actual transformations in ADF, you'll need to use the data flows functionality.
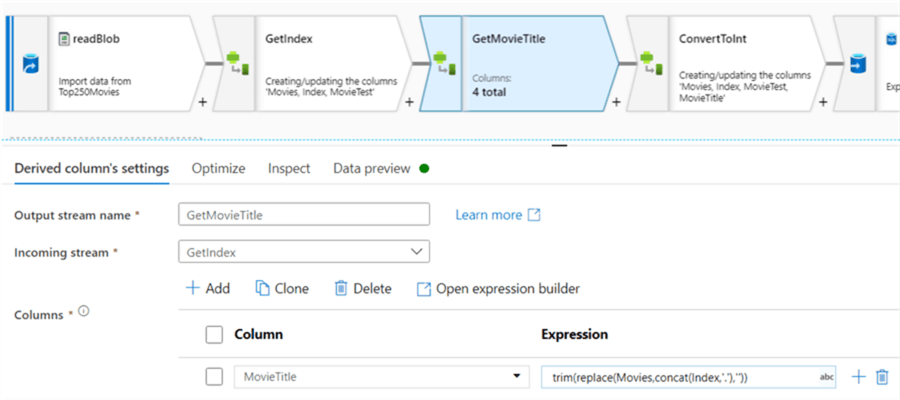
However, sometimes there's functionality required that cannot be handled in either T-SQL or a simple expression editor. Luckily there are some alternatives:
- You can include .NET scripts in SSIS or SQL CLR code in SQL Server. A good use case is for example when you need to use regular expressions or need to use some external libraries.
- There are a couple of options in Azure:
- You can use Azure Databricks or Azure Spark pools in Synapse Analytics. These allow you to write your calculations in R, Python, Scala, or SQL in a notebook fashion. Typically, you have access to far more advanced libraries, such as libraries for machine learning.
- You can create an Azure Function to process the data. These support many programming languages, such as Python, C#, PowerShell, JavaScript …
Loading Data
Once the data is in the desired shape, you can load it into the destination (ie.e. data warehouse, data mart, etc.). Typically, this is either some file system (for example Azure Blob Storage or Azure Data Lake Storage) or a relational database. In many scenarios, the ETL developer will load data into a data warehouse. Depending on the size of the team, the ETL developer and the data warehouse designer are the same person. If not, you'll need to sit down with the data warehouse architect and discuss how the facts and dimensions are designed. Typically, you'll need an answer to the following questions:
- How do I need to load this fact table? Is it a full load or an incremental one? If we load for a specific day, do I delete the data if it's already there (or use partition switching)? Do we update data? Or do we do only inserts? Suppose we have a sales value of $100 in a transaction, and in the source it was updated to $50. Do we overwrite the value, or do we add another transaction of -$50, so the total is $100? Both are valid options, but depending on auditability, you might need to go with extra inserts.
- How do we load the dimension? Are there any historical columns (Slowly Changing Dimension Type 2, or any other type of SCD)? What about records that were deleted from the source? Do we delete them as well in the dimension (hard-delete), or do we mark them as deleted (soft-delete)?
- Are there any dependencies between dimensions? Or between facts? In what order do we need to load everything?
- Do we need to drop/disable indexes before we load a table? Are there any columnstore indexes present that might make the data load more complex? What about foreign keys?
- How often do we need to load the data warehouse? What if some sources are updated more frequently than others? What if some sources are unavailable?
- What if an error occurs? Do we continue loading, knowing there might be some data missing? Or do we just halt the process, fix the error, and then continue?
Any tool mentioned in the previous sections can be used to load data. When loading data warehouses, it's most of the time SSIS or the T-SQL scripting language is used.
Other Responsibilities and Skillsets
An ETL developer does more than create ETL pipelines:
- Whatever code/package/artifact you create, it better be checked into some sort of source control.
- Not always the task of the ETL developer, but sometimes they are responsible for creating build/release pipelines as well.
- Attending meetings is part of the deal as well as a part of the software development team. This can be status meetings (like daily standups), but also planning meetings, requirements gathering, workshops with business users, meetings with business/technical analysts and so on. So, communication skills are a must.
- Orchestrating the pipelines with schedulers like SQL Server Agent or triggers in ADF, but perhaps other tools like Apache Airflow.
- Creating/configuring a monitoring solution around the ETL pipelines. If something goes wrong, you'll want to know about it. Troubleshooting and data analysis can be difficult and time consuming.
- Testing everything you created. This can be unit tests (does the data in my dimensions look OK?), to integration tests (does the data warehouse load still run fine after I've deployed my changes?) to user acceptance testing (do the reports still display correct data after my changes in the ETL pipeline?). Problem solving skills are key here.
- Performance tuning of every shackle in the ETL chain to make sure it all runs smoothly.
Next Steps
- Interested in the role of an ETL developer? Check out the tip A Day in the Life of a BI Developer as well.
- Azure Data Factory vs SSIS vs Azure Databricks
- How to Add SQL Server Integration Services Projects to Azure Devops for Version Control
- Using Azure DevOps CI CD to Deploy Azure Data Factory Environments






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-07-14
