By: Maria Zakourdaev | Updated: 2022-09-15 | Comments | Related: > Azure
Problem
There is a lot of tooling around data enrichment and data orchestration in the Azure cloud and many services with similar features. Azure Data Factory, Azure Databricks, Azure Synapse Pipelines, and SSIS services can move data from one data store to another, clean the data, enrich the data by merging entities, and perform data aggregations. They can transform the data from one format into another and partition it according to the business logic. Why would we choose one service over another?
Solution
Let's take a look at things to consider when selecting tools and developing your data processing strategy.
Why Choose Only One Tool?
Data pipelines can be implemented using multiple tools. Let's consider per data pipeline stage.
Modern programming goes against monolithic architectures and against relying exclusively on the same technology.
A term that is dominant in modern data-driven applications is polyglot persistence. New data-driven applications encourage diversity and usage of multiple types of data stores depending on the data purpose. Some data can be temporarily stored in the cache layer or memory and expire when the application does not need it anymore. For other types of data, different data formats and multiple storage systems are used based on query requirements, level of performance needed, or cost efficiency.
There are enough reasons to support such diversity in any layer of data-driven applications, including the data processing layer. It enables flexibility to choose a different product for each section of the data pipeline. It adds reliability when different data processing phases aren't dependent on one another, being free to choose any data processing tool for different stages of data processing can greatly lower costs.
Moving away from large monolithic pipelines toward small reusable flows brings numerous benefits.
Chaining data migration and data processing pipelines:
- Improves Scalability: When the pipeline is autonomic and simple, it's easy to scale it up and down when amounts of data increase or decrease. Scaling only part of the dataflow can save a lot of money.
- Fast and Cost-efficient Upgrades: It's easy to change the logic or change technology for a subset of the data pipeline without affecting the whole flow. This supports an agile, continuous development methodology allowing frequent changes with minimal test time.
- Fault Isolation: Failure on any small pipeline does not trigger failures of other flows that aren't dependent on one another.
We are free to use the most suitable technology for each pipeline and avoid feature lock. This allows more flexibility in choosing the most appropriate data processing technology that suits the exact need. Adopting a new technology would be easier when the logic of the pipeline is not too complicated.
Where Each Service Fits?
Two flow types coexist inside our data pipeline: data ingestion and data preparation.
- Data Ingestion/Orchestration Flow reads data from multiple sources and copies the files to the destination or intermediate data store. Data orchestration tools have a different number of connectors, either native to the source data stores or simply generic.
- Data Preparation Flows are being executed by the data orchestration flow as a separate task and take care of data itself, making all kinds of data transformations, data cleaning, filtering, data enrichment, entity merging, and aggregation.
As a default architecture, Azure suggests using Data Factory for orchestration work, Databricks for data enrichment, and Azure Synapse as a data service layer. You can see below one of the examples of the data pipeline where Azure Data Factory is responsible for the orchestration, executing Databricks notebooks as a part of the flow.
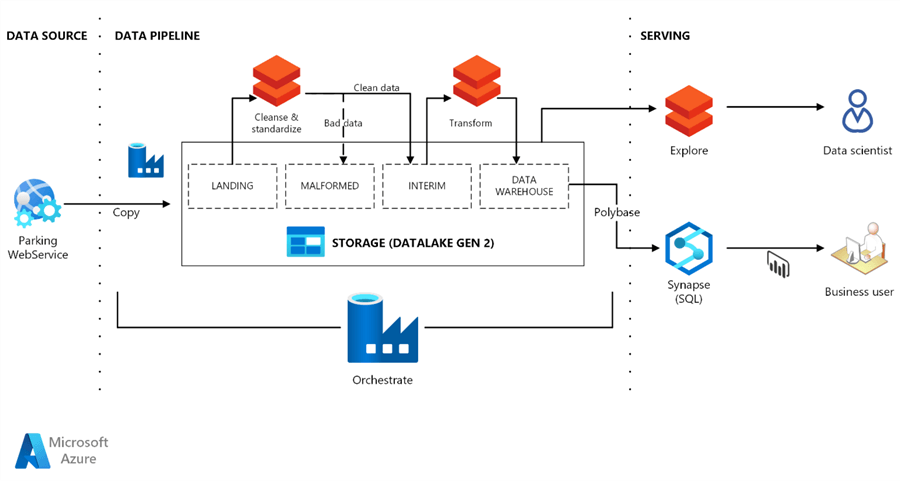
Source: https://docs.microsoft.com/en-us/azure/architecture/example-scenario/data-warehouse/dataops-mdw
- We need to make sure the orchestration tool that we choose can connect and read the source data format. Suppose we need to connect to a source that Data Factory doesn't support, for instance, some custom API. In that case, we can use Azure Databricks notebook or Azure Synapse Notebook and connect using Python code.
- We will consider which data store will perform all work. This will impact data processing time due to different computing capacity and scaling sizes and will also affect the solution cost.
- We always consider whether we want to copy the data from the source data store to another data store or keep the data in one place without data duplication. Data duplication takes time and causes storage costs to grow.
- The more data we have to process inside our pipeline, the more impact parallel processing will make – this allows us to process data in chunks in parallel. For parallel data processing, we should consider using SPARK or any other massively parallel data processing technology.
Shall You Have a Single Pipeline?
Building a single pipeline is a very bad software design approach. This results in a huge pipeline with many steps that make you nervous every time you need to debug it. Data orchestration stages depend on one another and usually block each other. New data continues to arrive at the source system and will not be available for data analysis until the whole pipeline finishes processing.
Modern Modular Data Pipelines
Instead of having a huge single flow, modern data orchestration pipelines are divided into multiple pipelines - short, simple, and independent. One pipeline would copy the data from the source data store to the data lake, making it available to data analysts in almost near real-time. Data preparation flows independently prepare the data for future analysis and can work in parallel on the different frequencies and cave costs. One pipeline failure would not impact other data preparation pipelines. This way, it's easy to scale each pipeline separately where there are bottlenecks, to speed up only specific tasks and save money on keeping other operations on lower compute.
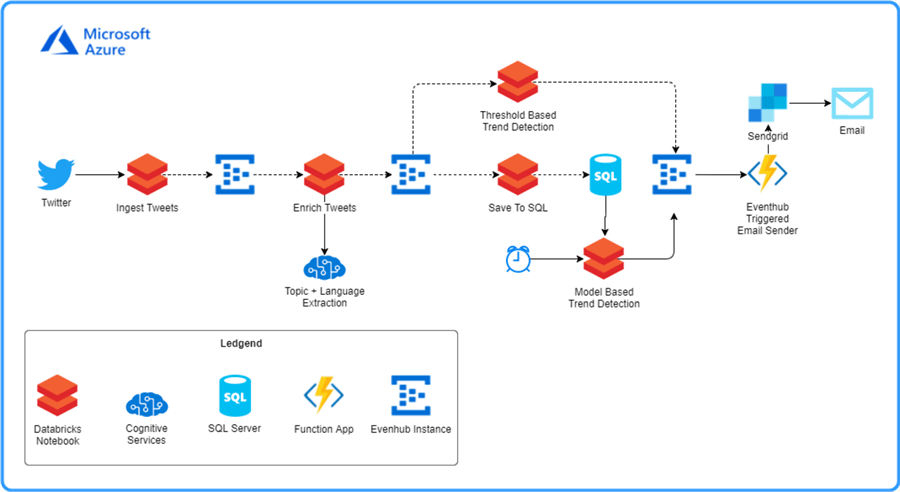
Source: https://devblogs.microsoft.com/cse/2018/12/12/databricks-ci-cd-pipeline-using-travis/
The above Microsoft DevBlogs article shows a really nice example of the modular pipeline. Multiple pipeline tasks are triggered separately, executed using Azure Databricks, and intermediate results persist in the different landing zones: Azure Event Hub and Azure SQL Database. Such architecture enables scalability in a smart way: each module requires different computational resources.
There are a lot of tools in the Data Engineer Toolbelt. Don't be afraid to step out of your comfort zone to select the right solution for the problem at hand.
Next Steps
- Additional reading:






About the author
 Maria Zakourdaev has been working with SQL Server for more than 20 years. She is also managing other database technologies such as MySQL, PostgreSQL, Redis, RedShift, CouchBase and ElasticSearch.
Maria Zakourdaev has been working with SQL Server for more than 20 years. She is also managing other database technologies such as MySQL, PostgreSQL, Redis, RedShift, CouchBase and ElasticSearch.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-09-15
