By: Levi Masonde | Updated: 2022-10-06 | Comments (1) | Related: > Python
Problem
In a previous article, we looked at how to consume an API endpoint to store data to a SQL Server table and then used Power BI to report on that data. In this article, we will look at how to load multiple tables using API endpoints from the same source or even different ones, as well as how to automate the load process.
Solution
Python has a module called AsyncIO which can help you organize, manage and run multiple API requests in an elegant way, making your code easy to understand and scale. Combining AsyncIO with SQL Server and Power BI, you can have a nice stream of data from your API sources to visualize on reports.
In this article, you will learn how to automate the consumption of multiple API endpoints asynchronously using Python and storing the consumed data in SQL Server tables.
This article is a follow-up to this article, so kindly go through the previous article in order to create the main folder, install the necessary modules and get the general background.
Consuming API data
Just like in the previous article, for this tutorial we will use mock API endpoints data provided by JSONPlaceholder.
We will be using Python to fetch the data and load it to a SQL database using a script at the end of this section. The twist in this article is that we will automate the consumption of three of these API endpoints asynchronously.
JSONPlaceholder comes with a set of 6 common resources:
| /posts | 100 posts |
| /comments | 500 comments |
| /albums | 100 albums |
| /photos | 5000 photos |
| /todos | 200 todos |
| /users | 10 users |
We will be consuming the 'users', 'comments' and 'todos' endpoints in this article.
We will continue from where we left off in the previous article, so you will need to walk through the first article before starting here.
Open the MSSQLTIPS folder in Visual Studio Code and select the API-DATA_Users.py file.

This is the final code for the API_DATA_Users.py file from the previous article, you need to edit this code to prepare it for AsyncIO.
Open the Visual Studio terminal by clicking on 'Terminal' and selecting 'New Terminal'.

AsyncIO is a library to write concurrent code using the async/await syntax. Read more about AsyncIO here.
Install AsyncIO by running the following pip command on your terminal:
pip install AsyncIO
The output will be as below.

Select the entire code starting at the main_request function in the API-DATA_Users.py file and press the tab key on your keyboard to indent the entire code to nest the code in a new Async function you will create in the next step.

You declare an async function by using async as a prefix to your function and use await to call the function.

Create another async function below the Get_Users async function and name the function Call_GetUsers. This function will be responsible for calling the Get_Users function when called. Another fact to keep in mind is that you can only await a function in an async function.

Good work so far, this will be the template for the other files you will create now, every API endpoint will have a file dedicated to it but the files will follow the structure followed on the API-DATA_users.py file.
Rename the API-DATA_users.py to ApiData_users.py.
Create another file called ApiData_comments.py and write the code as below.

Notice how the endpoint is changed to 'comments' instead of 'users' as seen in the API-DATA_users.py. Otherwise, most of the code is similar to the one in the ApiData_users.py
Create another file and name it ApiData_todos.py and write the code as shown below.

Yet again, the change happens at the endpoint variable and function names.
Now you have to create the file to automate running/calling the async functions declared in ApiData_users.py, ApiData_comments.py and ApiData_todos.py.
To help you run these different files. Install apscheduler by running this pip command on your visual studio terminal:
pip install apscheduler
Create the main concurrent file and name it concurrent.py and write the code as shown below and click the RUN icon to run the code.

The output on your terminal should be as shown below.
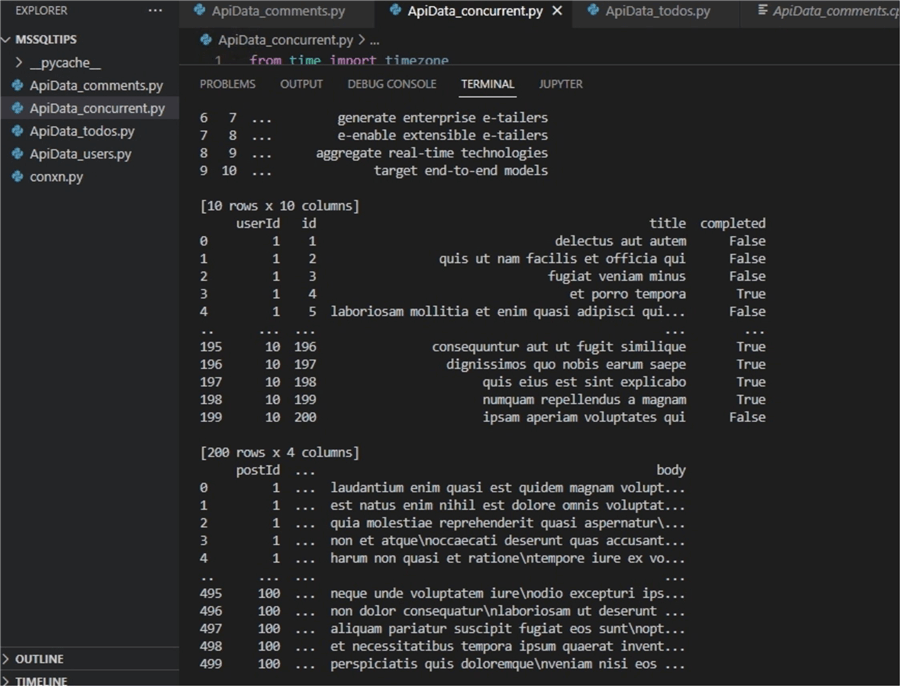
These are the Print() functions displaying the Users, Comments and Todos from their respective files.
Great job, you have automated calling different async functions from different files, this is set to run continuously unless you click 'Ctrl + C' to cancel.
In this article, you are using static API data, but the methods described here are ideal for API data that is constantly changing. In the following section, you will create tables in your SQL Server database for the API data.
Creating SQL Tables
In the previous article, we showed how to create the users table using SSMS and that we only needed to create the id column, because the Python code would create the rest of the table columns. That is the same for these other two tables todos and comments.
Here is the SQL code to create the three tables.
CREATE TABLE users (id int); GO CREATE TABLE todos (id int); GO CREATE TABLE comments (id int); GO
Writing to SQL Server database
To write the Comments API data to the SQL server database, add this code to the bottom of your code in the ApiData_Comments.py as shown below.

To write the Todos API data to the SQL server database, add this code to the bottom of your code in the ApiData_todos.py file as shown below.

After adding the 'to_sql()' functions to your files, go back to the ApiData_concurrency.py file and RUN the script.
After re-running the script. The API data will be written to the SQL server database. This will run continuously every 1 second until canceled.
Hooray, the data has been written to the SQL Server database from the API DATA.
Summary
Great work. You just gained superpowers in terms of processing APIs. You can now automatically source multiple API endpoints asynchronously, this becomes very important when you want to integrate a process where constantly updated API data is loaded for your needs such as reports, queries or for enhancing other data in your systems.
Complete Set of Python Code
Here is a complete set of code for this article.
ApiData_users.py full code:
#importing modules
import requests
import pandas as pd
from pandas import json_normalize
import sqlalchemy as sa
from conxn import coxn
#defining headers
headers = {
'accept':'application/json',
}
#defining baseurl
baseurl = 'https://jsonplaceholder.typicode.com/'
#defining endpoint
endpoint = 'users'
#async function
async def Get_Users():
#main request function
def main_request(baseurl,endpoint,headers):
#using requests to call API data
r = requests.get(baseurl + endpoint,headers=headers)
#returning data in json format
return r.json()
#variable calling main function
data = main_request(baseurl=baseurl,endpoint=endpoint,headers=headers)
#creating a datafram using pandas
data_DF = pd.DataFrame(data)
#adding a column called index to dataframe
data_DF['index'] = range(0,len(data_DF))
#creating a different dataframe for the nested column
company_DF = pd.concat([pd.DataFrame(json_normalize(x)) for x in data_DF['company']],sort=False)
#Renaming the column names to include company_ prefix
company_DF.columns = 'company_' + company_DF.columns
#creating a new column called index
company_DF['index'] = range(0, len(company_DF))
#combining the original dataframe with the dataframe from nested column.
merged_df = pd.merge(data_DF,company_DF,on="index")
#dropping the address column
merged_df = merged_df.drop(['address'], axis=1)
#dropping the company
merged_df = merged_df.drop(['company'], axis=1)
#write out merged data
print(merged_df)
merged_df.to_sql('Users',con=coxn, schema='dbo', if_exists='replace',index=True)
async def Call_GetUsers():
await Get_Users()
ApiData_comments.py full code:
#importing modules
import requests
import pandas as pd
from pandas import json_normalize
import sqlalchemy as sa
#importing the connection string from the conxn.py file
from conxn import coxn
#defining headers
headers = {
'accept':'application/json',
}
#defining baseurl
baseurl = 'https://jsonplaceholder.typicode.com/'
#defining endpoint
endpoint = 'comments'
#async function
async def Get_Comments():
#main request function
def main_request(baseurl,endpoint,headers):
#using requests to call API data
r = requests.get(baseurl + endpoint,headers=headers)
#returning data in json format
return r.json()
#variable calling main function
data = main_request(baseurl=baseurl,endpoint=endpoint,headers=headers)
#creating a datafram using pandas
comments_DF = pd.DataFrame(data)
print(comments_DF)
comments_DF.to_sql('Comments',con=coxn, schema='dbo', if_exists='replace',index=True)
async def Call_GetComments():
await Get_Comments()
ApiData_todos.py full code:
#importing modules
import requests
import pandas as pd
from pandas import json_normalize
import sqlalchemy as sa
from conxn import coxn
#importing the connection string from the conxn.py file
#defining headers
headers = {
'accept':'application/json',
}
#defining baseurl
baseurl = 'https://jsonplaceholder.typicode.com/'
#defining endpoint
endpoint = 'todos'
#async function
async def Get_Todos():
#main request function
def main_request(baseurl,endpoint,headers):
#using requests to call API data
r = requests.get(baseurl + endpoint,headers=headers)
#returning data in json format
return r.json()
#variable calling main function
data = main_request(baseurl=baseurl,endpoint=endpoint,headers=headers)
#creating a datafram using pandas
todos_DF = pd.DataFrame(data)
print(todos_DF)
todos_DF.to_sql('Todos',con=coxn, schema='dbo', if_exists='replace',index=True)
async def Call_GetTodos():
await Get_Todos()
ApiData_concurrent.py full code:
from time import timezone
from ApiData_users import Call_GetUsers
from ApiData_comments import Call_GetComments
from ApiData_todos import Call_GetTodos
import asyncio
from apscheduler.schedulers.asyncio import AsyncIOScheduler
import os
import tzlocal
async def chain():
Users_task = asyncio.create_task(Call_GetUsers())
Todos_task = asyncio.create_task(Call_GetTodos())
Comments_task = asyncio.create_task(Call_GetComments())
await Users_task
await Todos_task
await Comments_task
if __name__ == "__main__":
scheduler = AsyncIOScheduler(timezone=str(tzlocal.get_localzone()))
scheduler.add_job(chain,'interval',seconds=1)
scheduler.start()
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
asyncio.get_event_loop().run_forever()
except (KeyboardInterrupt,SystemExit):
pass
Conxn.py full code:
import pyodbc
import sqlalchemy as sa
from sqlalchemy import create_engine
import urllib
import pyodbc
conn = urllib.parse.quote_plus(
'Data Source Name=T3chServer;'
'Driver={SQL Server};'
'Server=DATA-SERVER\T3CHSERVER;'
'Database=MSSQLTIPS_DB;'
'Trusted_connection=yes;'
)
coxn = create_engine('mssql+pyodbc:///?odbc_connect={}'.format(conn))
Next Steps
- Build a Secure SQL Server REST API in Minutes
- Learn more about Power BI Dataset
- Build a Power BI report






About the author
 Levi Masonde is a developer passionate about analyzing large datasets and creating useful information from these data. He is proficient in Python, ReactJS, and Power Platform applications. He is responsible for creating applications and managing databases as well as a lifetime student of programming and enjoys learning new technologies and how to utilize and share what he learns.
Levi Masonde is a developer passionate about analyzing large datasets and creating useful information from these data. He is proficient in Python, ReactJS, and Power Platform applications. He is responsible for creating applications and managing databases as well as a lifetime student of programming and enjoys learning new technologies and how to utilize and share what he learns.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-10-06
