By: Jan Potgieter | Updated: 2022-10-12 | Comments (5) | Related: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | > Indexing
Problem
Microsoft SQL Server is a great tool to store lots of data, but the real value is the ability to quickly find the data you need by using indexes on the tables where the data is stored. In this tutorial, we will look at two types of indexes that can be created on a table in a SQL database: clustered and nonclustered indexes.
Solution
SQL Indexes Overview
There are several types of indexes in SQL Server, but in this tutorial, we will focus on Clustered and Nonclustered indexes.
To give you a better idea of what these indexes are we can use a book as an example.
- Each page of a book has a page number which lets you quickly find that page in the book and therefore whatever information is on that page. Also, the physical ordering of the book always remains the same. These characteristics are similar to a clustered index.
- In addition, a book often has a table of contents at the front of the book. This can be used to quickly find a particular topic and the corresponding page number. This is similar to a nonclustered index. We can quickly find the page number and maybe some other information, but not all of the details. In order to get the majority of the content, we need to go to that page in the book. This is similar to what is called a lookup, where we first read the index for some data, but then lookup the actual page for the content.
- Books also have an index at the back of the book that points to specific pages in the book. This is again similar to a nonclustered index.
In SQL Server, indexes improve query performance for stored procedures and T-SQL scripts (SELECT statement, UPDATE statement, DELETE statement) when accessing tables with a large number of records. They're extremely useful if you have hundreds of thousands or millions of records in a database and want to access the data quickly with a WHERE clause. Indexwas are beneficial for smaller tables as well. In addition, you can only have one clustered index on a table, but you can have many nonclustered indexes on a table. Again, this is similar to our book analogy above.
SQL Server Clustered Index
Let's create a TestDB database with the following syntax and walk through some examples.
-- Change active database to TestDB CREATE DATABASE TestDB GO USE TestDB; GO
As mentioned, a clustered index defines how the data is stored. Since there is only one copy of the data, the clustered index defines that order. Note, all tables don't have to have a clustered index and these tables are referred to as heap tables, but that is a different topic. In most cases, it is always better to have a clustered index.
Another concept that should be mentioned is a primary key. A primary key is a unique key for each record in a table that allows SQL Server to go directly to that one row. Not all tables have a primary key, but it is always better to have one when possible.
We will walk through several examples of creating a clustered index.
Create Clustered Index as Primary Key
In these first couple of examples, we will create a clustered index as the primary key. Note, the primary key does not need to always be the clustered index, but often this is the case.
Let's create two database tables: one WITHOUT a Primary Key and one WITH a Primary key, and then compare the two tables to see the clustered index.
-- No Primary Key drop table if exists TableA; create table TableA (ID int) exec sp_help TableA; -- Primary Key drop table if exists TableB; create table TableB (ID int primary key) exec sp_help TableB;
Here is the first table without a primary key.

Here is the second table with a primary key. Note, that the primary key automatically created a clustered index on that particular column which was the ID column. Also, take note of the following: index_name and constraint_type (highlighted in yellow) in the image below.

So, what is a constraint?
A constraint is a set of rules for the data in a table. In other words, constraints regulate the type of data that can be inserted into a table.
The constraint here is a Primary Key on the ID column which is a Unique constraint, that says each value has to be unique.
See the following article about the five types of constraints in SQL: Constraints in SQL Server and check out: Difference between SQL Server Unique Indexes and Unique Constraints.
Create Clustered Index as Primary Key with a Specified Name
When creating a clustered index and you want to give it a specific name, which is always the best approach, you declare it as a constraint as shown in the code sample below.
drop table if exists TableC; create table TableC ( ID int constraint PK_TableC primary key (ID asc), EmployeeName varchar(20) ) exec sp_help TableC;
The difference now is that the index_name is named PK_TableC and also we can see the constraint listed as well in the below image.

Create Clustered Index not as a Primary Key
In the code below, we first define the table and then define the clustered index.
drop table if exists TableD
create table TableD (
ID int,
EmployeeName varchar(20)
)
exec sp_help TableD;
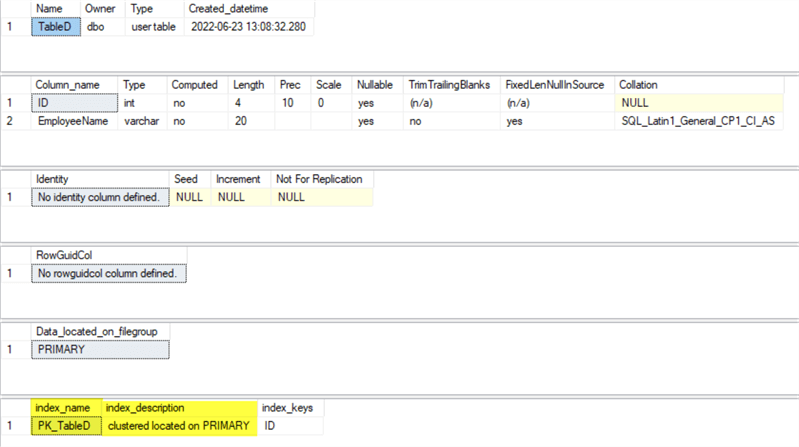
create clustered index PK_TableD on dbo.TableD (ID) -- CREATE INDEX
exec sp_help TableD;
Notice that you have created a clustered index, but it does not show a constraint. Also, notice in the index_description it does not say unique.
Create a Second Clustered Index
Let's try to create another clustered index on the EmployeeName column and see if it works.
CREATE CLUSTERED INDEX IX_PrimKeyTable_EmployeeName ON TableD(EmployeeName ASC)
The error is clear: You CANNOT create more than one clustered index on a table.
Cannot create more than one clustered index on table 'TableD'. Drop the existing clustered index 'PK_TableD' before creating another.
SQL Server Nonclustered Indexes
A nonclustered index is a smaller set of data, index columns, stored separately and ordered based on the definition of the index. These indexes are used as pointers to quickly retrieve data that exists in the index or used to lookup additional data that is stored in the clustered index. You can also have multiple nonclustered indexes on a table.
Create Nonclustered Index
Let's create an employees table to explain how to create a Nonclustered index.
CREATE DATABASE HRDatabase; GO USE HRDatabase; GO
Let's create a table without any indexes and insert some data.
DROP TABLE IF EXISTS Employees; CREATE TABLE Employees ( ID INT, EmpName VARCHAR(80) NOT NULL, ContactNo VARCHAR(20) NOT NULL, Email VARCHAR(80) NOT NULL, Gender VARCHAR(50) NOT NULL, DOB DATETIME NOT NULL ) INSERT INTO Employees VALUES ( 6, 'Joe', '012 365 4789', '[email protected]' , 'Male', '1982-03-20'), ( 3, 'Jane', '012 365 4789', '[email protected]' , 'Female' '1981-10-22'), ( 1, 'John', '012 365 4789', '[email protected]' , 'Male', '1984-11-10'), ( 2, 'Eddy', '012 365 4789', '[email protected]' , 'Male', '1986-09-15'), (10, 'Steve', '012 365 4789', '[email protected]', 'Male', '1989-01-31'), ( 7, 'Kate', '012 365 4789', '[email protected]' , 'Female', '1980-02-28'), ( 5, 'Sara', '012 365 4789', '[email protected]' , 'Female', '1982-06-18'), ( 9, 'Joseph', '012 365 4789', '[email protected]', 'Male', '1981-08-07'), ( 8, 'Alan', '012 365 4789', '[email protected]' , 'Male' '1987-05-13'), ( 4, 'Jolly', '012 365 4789', '[email protected]', 'Female', '1984-06-12') SELECT * FROM Employees exec sp_help Employees

Now, let's create a nonclustered index on the EmpName column and select some data.
CREATE NONCLUSTERED INDEX IX_Employees_EmpName ON Employees(EmpName ASC) -- CREATE INDEX SELECT EmpName FROM Employees

If you select just the EmpName from the Employees table, you will notice the data is returned in ascending order because the nonclustered index states ON Employees(EmpName ASC)which means order the EmpName in ascending order. Also, since we are only selecting the EmpName column, SQL Server is using the index to return the data and does need to access the rest of the data.
Let's create another nonclustered index on the ID column, this time in descending order.
CREATE NONCLUSTERED INDEX IX_Employees_ID ON Employees(ID DESC) exec sp_help Employees
Let's see the impact of this index when running a SELECT statement on just the ID. This time the values are in descending order.
SELECT ID FROM Employees -- SELECT Query

Also, when running sp_help, you can see there are two nonclustered indexes on the table now.
exec sp_help Employees
If you look at the index_keys column you will see a (-) next to ID. This shows that the index is in descending order.

SQL Server Clustered and Nonclustered Database Index Example
Let's look at an example SQL statement where there are both clustered and nonclustered indexes.
DROP TABLE IF EXISTS Employees; CREATE TABLE Employees ( ID INT CONSTRAINT PK_Employees PRIMARY KEY IDENTITY, EmpName VARCHAR(80) NOT NULL, ContactNo VARCHAR(20) NOT NULL, Email VARCHAR(80) NOT NULL, Gender VARCHAR(50) NOT NULL, DOB DATETIME NOT NULL ) INSERT INTO Employees VALUES ( 6, 'Joe', '012 365 4789', '[email protected]' , 'Male', '1982-03-20'), ( 3, 'Jane', '012 365 4789', '[email protected]' , 'Female' '1981-10-22'), ( 1, 'John', '012 365 4789', '[email protected]' , 'Male', '1984-11-10'), ( 2, 'Eddy', '012 365 4789', '[email protected]' , 'Male', '1986-09-15'), (10, 'Steve', '012 365 4789', '[email protected]', 'Male', '1989-01-31'), ( 7, 'Kate', '012 365 4789', '[email protected]' , 'Female', '1980-02-28'), ( 5, 'Sara', '012 365 4789', '[email protected]' , 'Female', '1982-06-18'), ( 9, 'Joseph', '012 365 4789', '[email protected]', 'Male', '1981-08-07'), ( 8, 'Alan', '012 365 4789', '[email protected]' , 'Male' '1987-05-13'), ( 4, 'Jolly', '012 365 4789', '[email protected]', 'Female', '1984-06-12') CREATE NONCLUSTERED INDEX IX_Employees_EmpName ON Employees(EmpName ASC) CREATE NONCLUSTERED INDEX IX_Employees_Email ON Employees(Email DESC) SELECT * FROM Employees -- SQL Query exec sp_help Employees

Notice there are three indexes on the Employees table:
- One clustered index that is the Primary Key on ID (PK_Employees), and
- Two nonclustered indexes on EmpName and Email (IX_Employees_Email and IX_Employees_EmpName).
Remove Test Databases
We can use the following script to drop the two test databases.
USE master; GO -- Drop Database if it exist DROP DATABASE IF EXISTS TestDB; GO -- Drop Database if it exist DROP DATABASE IF EXISTS HRDatabase; GO
Next Steps
See the following articles as well:
- SQL Server Index Tutorial Overview
- SQL Server Indexing Tips
- SQL ORDER BY Clause Examples
- Index Scans and Table Scans
- SQL Server Index Types






About the author
 Jan Potgieter has more than two decades of expertise in the database industry as a Certified Microsoft SQL Server Administrator and Database Developer.
Jan Potgieter has more than two decades of expertise in the database industry as a Certified Microsoft SQL Server Administrator and Database Developer.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-10-12
