By: Jared Westover | Updated: 2022-10-20 | Comments (3) | Related: > Indexing
Problem
Creating an index often leads to a significant impact on improving low-performing Microsoft SQL Server queries. However, have you ever been confused about ordering key columns? Maybe you've heard it doesn't matter, or you should always follow a certain pattern. Years ago, a coworker recommended that I always order them in a specific way. He claimed that if you ordered them incorrectly, SQL Server ignores the index. However, with time and testing, I've found that optimal order depends.
Solution
In this SQL tutorial, we'll explore the importance of column order when creating nonclustered indexes. We'll look at how an execution plan points out the missing indexes, but you shouldn't blindly create them. Next, you'll see how to determine the uniqueness of your columns. Finally, I'll explore two scripts and conduct experiments to see if the column order of an index significantly impacts performance. By the end of this article, you'll start creating indexes in your environment today.
Why Create SQL Server Indexes
This article assumes you have a basic understanding of nonclustered indexes in SQL Server. You can boil it down to a smaller, ordered copy of the data. For example, imagine your table has 15 columns and 100,000 rows. If you create a nonfiltered index on one of those columns, your index will have one column along with the clustered key if one exists. You generally create indexes to make queries perform faster. They can also help with speeding up the execution of inserts and updates. Perhaps your end users started complaining about the performance of your application or reports. If you don't currently use nonclustered indexes, you're missing out.
Building our Dataset
Running the script below creates our sample dataset. I'm creating one table to make things simple and adding 100,000 rows. Please run this on a test environment and follow along. All screenshots and results are from SQL Server 2019 Developer edition.
DROP TABLE IF EXISTS dbo.ColumnOrder;
CREATE TABLE dbo.ColumnOrder
(
MostUnique INT IDENTITY(1, 1),
FourthMost INT NOT NULL,
ThirdMost INT NOT NULL,
SecondMost INT NOT NULL,
Comments NVARCHAR(250) NULL,
CONSTRAINT PK_ColumnOrder_MostUnique
PRIMARY KEY CLUSTERED (MostUnique)
);
GO
INSERT INTO dbo.ColumnOrder
(
SecondMost,
ThirdMost,
FourthMost,
Comments
)
SELECT TOP (100000)
ABS(CHECKSUM(NEWID()) % 80000) + 1 AS SecondMost,
ABS(CHECKSUM(NEWID()) % 1000) + 1 AS ThirdMost,
ABS(CHECKSUM(NEWID()) % 10) + 1 AS FourthMost,
REPLICATE('This is a great product!', 10) AS OrderComments
FROM sys.all_columns AS n1
CROSS JOIN sys.all_columns AS n2;
GO
Notice that we have a clustered index on the MostUnique column. We also have three other columns of integer data type.
A version of the script below constantly runs in the application.
SELECT SecondMost,
ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE SecondMost = 60080
AND ThirdMost = 571
AND FourthMost = 7;
We accepted the challenge of creating an index to help performance. The screenshots below display the execution plan and statistics IO output. Remember, you may need different parameter values to return a result.


Logical reads show that SQL touches every page in the clustered index. Notice SQL Server asks us nicely to add an index. The index key should have the three columns used as predicates in our WHERE clause. This solution seems too easy. You can copy and paste the suggestion, run it, and end users stop sending nasty emails.
Multi Column Key for SQL Server Index
Given our example query above, how should we order the columns? SQL Server suggests setting the FourthMost column on the left. When creating the table, I ordered the columns intentionally for effect. For this query, the answer is that it doesn't matter much when performing an equality search on all columns in the key. You may say wait a minute; someone told me to place the most unique column on the left of the key. Doesn't selectivity come into play here?
Selectivity
The term selectivity refers to how unique the values in a column are. Let's look at a simple script to see the uniqueness of our four columns.
SELECT
'MostUnique' AS [Column]
,COUNT(DISTINCT MostUnique) AS UniqueValues
,COUNT(*) AS TotalRows
,CAST(COUNT(DISTINCT MostUnique) AS FLOAT) / COUNT(*) AS Selectivity
FROM
dbo.ColumnOrder
UNION ALL
SELECT
'SecondMost' AS [Column]
,COUNT(DISTINCT SecondMost) AS UniqueValues
,COUNT(*) AS TotalRows
,CAST(COUNT(DISTINCT SecondMost) AS FLOAT) / COUNT(*) AS Selectivity
FROM
dbo.ColumnOrder
UNION ALL
SELECT
'ThirdMost' AS [Column]
,COUNT(DISTINCT ThirdMost) AS UniqueValues
,COUNT(*) AS TotalRows
,CAST(COUNT(DISTINCT ThirdMost) AS FLOAT) / COUNT(*) AS Selectivity
FROM
dbo.ColumnOrder
UNION ALL
SELECT
'FourthMost' AS [Column]
,COUNT(DISTINCT FourthMost) AS UniqueValues
,COUNT(*) AS TotalRows
,CAST(COUNT(DISTINCT FourthMost) AS FLOAT) / COUNT(*) AS Selectivity
FROM
dbo.ColumnOrder;

As you can see from the screenshot above, SecondMost ranks as the most unique column except for the clustered index. The FourthMost column only has 10 distinct values out of 10,000. Out of habit, I place the most unique column to the left. However, if you tune for the query above, it doesn't significantly matter. SQL Server seeks the record because of the binary search taking place. In this article, Paul Randel writes that at each level of the index during a seek, a binary search takes place to find the right index record to navigate down to the next level lower in the index.
Creating the SQL Server Indexes
Let's go ahead and create the nonclustered index as SQL Server suggests.
CREATE NONCLUSTERED INDEX [IX_FourthMost_ThirdMost_SecondMost] ON [dbo].[ColumnOrder] ([FourthMost],[ThirdMost],[SecondMost]);
Now we'll rerun our query and check out our execution plan and statistics IO.
SELECT SecondMost,
ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE SecondMost = 60080
AND ThirdMost = 571
AND FourthMost = 7;

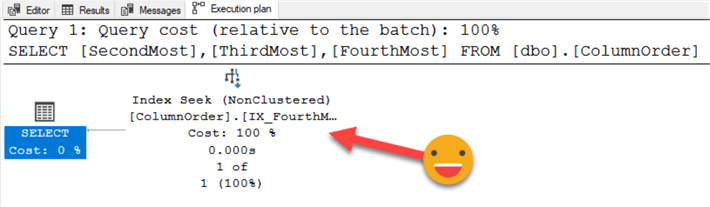
We lowered our page count drastically and performed a seek. Mission accomplished! However, does your environment only have one query? I'll assume your answer is no. Let's run a different query.
SELECT ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE SecondMost = 70010


Oh no! SQL scans the entire index, reading 274 pages. Granted, that's fewer pages than scanning the clustered index. Since we placed our SecondMost unique column on the right, SQL is unable to seek directly to it. What if we dropped this index and recreated it, reversing the column order?
DROP INDEX IF EXISTS [IX_FourthMost_ThirdMost_SecondMost] ON dbo.ColumnOrder; GO CREATE NONCLUSTERED INDEX [IX_SecondMost_ThirdMost_FourthMost] ON [dbo].[ColumnOrder] ([SecondMost],[ThirdMost],[FourthMost]); GO
Now let's run both queries and review our execution plans and statistics IO.
SELECT SecondMost,
ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE SecondMost = 44430
AND ThirdMost = 140
AND FourthMost = 7;
SELECT ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE SecondMost = 70010;


Now SQL chooses an index seek for both queries and only reads two pages. Given the example above, column order does matter. There's no one-size-fits-all when it comes to creating indexes. Your workload shapes the index you build.
Reverse Order
You may wonder when the reverse order index would help. You'll find one example below. Essentially, when you expect to return a range of rows based on the less unique column and perhaps sorted by the next one.
SELECT SecondMost,
ThirdMost,
FourthMost
FROM dbo.ColumnOrder
WHERE FourthMost = 7
ORDER BY ThirdMost DESC;
If our application executed a version of the query above hundreds or even thousands of times per day, you would likely want to think about adding an index for it.
Simple Guideline
If someone forced me to choose one approach in an OLTP environment, I'd place the most unique column on the left. Since with an OLTP workload, you often want seeks. Again, this guideline doesn't fit every situation, and you'll want to experiment with your workload. I'm not saying "seek good, scan bad" in my best caveman voice. One nice thing about creating indexes is the freedom to experiment.
Please keep in mind that we could look at several more examples, and this article doesn't cover all of them. I would like to hear about your experiences with index column order in the comments below.
Next Steps
- The next time you create an index, review the selectivity of the columns and think about what order makes the biggest impact.
- Looking for an insightful overview for finding missing indexes in SQL Server? Please check out Find SQL Server Missing Indexes with DMVs by Greg Robidoux.
- Eric Blinn has an informative article on using indexes to tune queries: SQL Server Performance Tuning with Query Plans and New Indexes.
- Here are other articles realted to index order: SQL Server Index Column Order - Does it Matter and Building SQL Server Indexes in Ascending vs Descending Order.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-10-20
