By: Jared Westover | Updated: 2022-11-16 | Comments | Related: 1 | 2 | 3 | 4 | 5 | 6 | > Functions System
Problem
Has someone told you performing a COUNT(*) in T-SQL scans the entire table? Maybe you've wondered about the performance impacts of using COUNT(*) in your queries. Do performance differences exist between COUNT(*) and COUNT(1)? These are just a few questions I'll try to answer in this SQL tutorial.
Solution
We can make claims about nearly anything. Unless someone tests those claims, we accept them as facts. Sometimes the claims are valid for a given context. Sometimes people are wrong about a given topic. I've held my share of false beliefs until someone pointed out my error. Early on, I assumed SQL obtained row counts from statistics. Looking back, I have no idea where that came from. I'll explore multiple scenarios using a COUNT(*) in this tutorial, particularly how it behaves with different table structures. For example, how does SQL Server respond when using a heap versus a clustered index? By the end of the tutorial, you'll have a deeper understanding of the internals of COUNT(*).
Looking at the SQL COUNT Function
Let's start by looking at our statement's COUNT() portion. Perhaps like me, you were introduced to the concept of counting by Count von Count on Sesame Street. All kidding aside, Microsoft defines COUNT() as a function that returns the number of items in a group. I've asked countless times during interviews: how you can determine the number of rows in a table with T-SQL. I try to hide the answer by not saying, how would you count the number of rows in a table?
COUNT() always returns an integer, while COUNT_BIG() returns a big integer. You see COUNT_BIG() used in data warehouse scenarios or if you have a massive table in your application database.
You could use the SELECT statement syntax below to count the number of rows in a table. If the table contains 1,000 rows SQL returns 1,000.
SELECT COUNT(*) FROM Schema.Table;
Often, you'll want to count the number of rows where a filter condition is true. The script below returns the number of rows where Column1 equals five.
SELECT COUNT(*) FROM Schema.Table WHERE Column1 = 5;
Another item you run across is using COUNT() in a subquery.
SELECT Column1,
Column2,
(
SELECT COUNT(*)FROM Schema.TableName WHERE Column3 = 3
)
FROM Schema.TableName;
You also see COUNT() used as part of a windowing function.
SELECT Column1,
Column2,
COUNT(*) OVER (PARTITION BY Column2) AS CountColumn
FROM dbo.CountTable;
Several other iterations of COUNT() exist, but we'll focus on the first two moving forward.
Building the Dataset
To explore a few examples, we need a dataset. Our table contains one million rows and consists of five integer columns and one allowing NULL. Please run the script below to follow along.
DROP TABLE IF EXISTS dbo.CountTable;
GO
CREATE TABLE dbo.CountTable -- SQL CREATE TABLE
(
Column1 INT IDENTITY(1, 1),
Column2 INT NOT NULL,
Column3 INT NOT NULL,
Column4 INT NOT NULL,
Column5 INT NULL,
);
GO
INSERT INTO dbo.CountTable -- SQL INSERT statement
(
Column2,
Column3,
Column4,
Column5
)
SELECT TOP (1000000)
ABS(CHECKSUM(NEWID()) % 100000) + 1 AS Column2,
ABS(CHECKSUM(NEWID()) % 100000) + 1 AS Column3,
ABS(CHECKSUM(NEWID()) % 100000) + 1 AS Column4,
CASE
WHEN ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) % 4 = 0 THEN
NULL
ELSE
ABS(CHECKSUM(NEWID()) % 100000)
END AS Column5
FROM sys.all_columns AS n1
CROSS JOIN sys.all_columns AS n2;
GO
Let's determine how many pages make up the table. This number lets us know what percentage of the pages SQL Server reads based on this SQL SELECT:
SELECT OBJECT_NAME(s.object_id) AS TableName,
s.used_page_count AS UsedPages,
s.reserved_page_count AS ReservedPages
FROM sys.dm_db_partition_stats s
INNER JOIN sys.tables t
ON s.object_id = t.object_id
WHERE t.name = 'CountTable'; -- WHERE Condition
Here is the result set:

Based on the dmv sys.dm_db_partition_stats, we have about 3,586 pages.
SQL COUNT Function Effects on a Heap
If you don't know, a heap refers to a table without a clustered index. It could have nonclustered indexes, but for right now, we have neither. To understand SQL's behavior, we'll turn on STATISTICS IO and our actual execution plan. I'm also using the MAXDOP hint, forcing SQL to skip parallelism.
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.CountTable OPTION (MAXDOP 1); SET STATISTICS IO OFF;

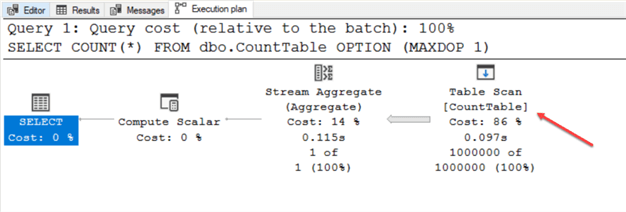
As most of you already guessed, SQL reads all the pages in our table. The claim of the engine performing a table scan holds in this case.
Add a Nonclustered Index for SQL COUNT Performance
Next up, let's create a nonclustered index on Column2 and rerun our query:
CREATE NONCLUSTERED INDEX IX_Column2 ON dbo.CountTable (Column2); GO SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.CountTable OPTION (MAXDOP 1); SET STATISTICS IO OFF;

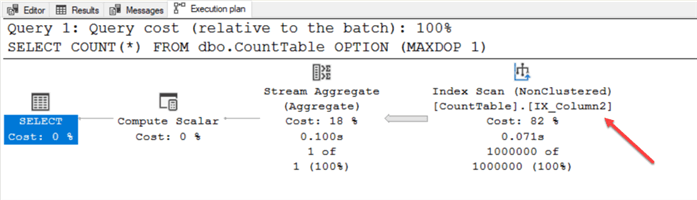
When you click on the messages tab, it appears SQL reads 2,236 pages and performs an index scan of our fresh new index. Reading fewer pages is great, but what if we add a WHERE clause that's not Column2?
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.CountTable WHERE Column3 = 2 OPTION (MAXDOP 1); SET STATISTICS IO OFF;
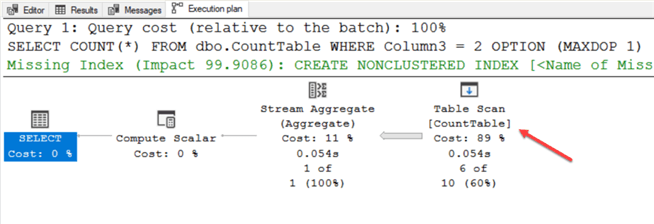
Since SQL doesn't know which pages have the value of 2 for Column3, we're back to using a table scan.
SQL chooses a table scan if a nonclustered index exists, but we include a WHERE clause for a nonindexed column. I'm sure you know that if we added an index on Column3, SQL would scan that index instead.
Add a Clustered Index
Now let's create a clustered index on Column1.
CREATE CLUSTERED INDEX PK_Column1 ON dbo.CountTable (Column1); GO SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.CountTable OPTION (MAXDOP 1); SET STATISTICS IO OFF;
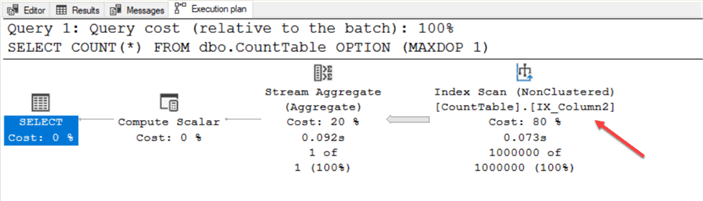
If we rerun the original query, SQL chooses the nonclustered index. Why, might you ask? Because it's smaller than the clustered. But what happens when we rerun the second query?
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.CountTable WHERE Column3 = 2 OPTION (MAXDOP 1); SET STATISTICS IO OFF;

As you can see, page reads went up because we're using the clustered index. The increase in pages comes from the index tree structure. More pages exist due to the root and intermediate levels.
When comparing a heap and clustered index, the engine uses whichever one is the smallest if you're not filtering the results. It makes sense because the optimizer looks for the lowest-cost operators to generate the results.
Effects of SQL COUNT(1)
While performing demos, I sometimes switch between COUNT(1) and COUNT(*). Occasionally someone asks if COUNT(*) and COUNT(1) behave differently. The short answer is no. Let's test it out with the following SQL statement.
SET STATISTICS IO ON; SELECT COUNT(1) FROM dbo.CountTable OPTION (MAXDOP 1); GO SELECT COUNT(*) FROM dbo.CountTable OPTION (MAXDOP 1); SET STATISTICS IO OFF;
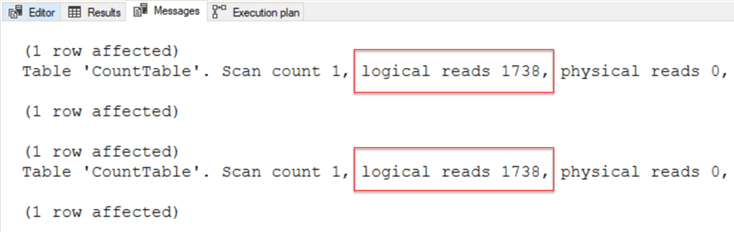
As you can see from the screenshot above, both statements return the same number of logical reads. Whatever number or character you place inside the parentheses tells SQL what value to assign the row. Maybe I should start using COUNT(42) instead.
Counting NULL Values
What about NULL value placeholders, does COUNT(*) include those? When we created our table, we defined every fourth row as NULL for Column5. All but one of the queries above returned one million rows. Column5 contains 250,000 NULLs. What If I want to exclude the NULLs in the count? Either of the queries below gets the job done.
SET STATISTICS IO ON; SELECT COUNT(Column5) FROM dbo.CountTable OPTION (MAXDOP 1); GO SELECT COUNT(*) FROM dbo.CountTable WHERE Column5 IS NOT NULL OPTION (MAXDOP 1); SET STATISTICS IO OFF;
Action Items
After reading this, what practical actions can you take? Creating a narrow nonclustered index might be a good option if you frequently perform counts over an entire table. SQL Server often picks the smallest index that satisfies the query criteria. Make sure your narrow index doesn't become too fragmented. Additionally, you might apply page compression to the index, making it even more performant. You also saw that COUNT(*) and COUNT(1) behave similarly. Do you deal with counting tables with billions of rows? You might explore the APPROX_COUNT_DISTINCT function new in SQL Server 2019 and Azure offerings. What other ways do you use COUNT()? Please leave your comments below.
Next Steps
- Aaron Bertrand wrote an informative article on using the APPROX_COUNT_DISTINCT function. If you're on SQL Server 2019 or an Azure offering, it's worth your time: SQL Server 2019 APPROX_COUNT_DISTINCT Function
- Are you looking for more information on the performance differences between the various flavors of COUNT? Simon Liew created a helpful comparison: SQL Server COUNT() Function Performance Comparison
- Are you interested in learning the differences between a heap and clustered index? Check out SQL Server Clustered Tables vs Heap Tables by Greg Robidoux on the topic.
- Check out these tips as well:






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-11-16
