By: Jared Westover | Updated: 2023-01-23 | Comments | Related: 1 | 2 | > Indexing
Problem
I recently helped a developer figure out why the optimizer refused to use a SQL Server filtered index. If you don't know, filtered, nonclustered indexes can save massive space on large Microsoft SQL Server tables. Additionally, you can often create a smaller index key. However, they can be tricky to use, especially when joining multiple tables.
Solution
In this SQL tutorial, let's take a look at SQL Server filtered indexes and how to create them. Continuing, I'll clarify how to get a filtered index to work when pulling data back from more than one table via a multi table join.
Defining a SQL Server Filtered Index
Indexes in themselves are the bread and butter of SQL performance tuners. In a nutshell, indexes allow you to limit the number of columns and, in turn, pages returned on a table. A filtered index enables you to limit the number of rows and pages even further. They were first introduced in SQL Server 2008 and only apply to nonclustered indexes. You can even create filtered columnstore indexes.
The syntax for creating a filtered index is below.
CREATE NONCLUSTERED INDEX [PleaseDoNotUseThisName] ON dbo.FancyTable (FancyColumn) INCLUDE (SomeOtherColumn) WHERE FancyColumn = 'SomeHighlySelectiveValue';
You use the same syntax to create a standard nonclustered index but include a WHERE clause at the end. Microsoft documented several restrictions for using filtered indexes.
Building Our SQL Server Database and Dataset for Testing
Let's create a dataset you can use for testing out all the T-SQL syntax which follows. I included a few extra columns so you can play with filtered indexes further. This code can be run in SQL Server Management Studio (SSMS).
USE [master];
GO
IF DATABASEPROPERTYEX ('FilteredIndexes','Version') IS NOT NULL
BEGIN
ALTER DATABASE FilteredIndexes SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
DROP DATABASE FilteredIndexes;
END
GO
CREATE DATABASE FilteredIndexes;
GO
ALTER DATABASE FilteredIndexes SET RECOVERY SIMPLE;
GO
USE FilteredIndexes;
GO
DROP TABLE IF EXISTS dbo.Numbers;
GO
DECLARE @UpperBound INT = 5000000;
;WITH cteN(Number) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] INTO dbo.Numbers
FROM cteN WHERE [Number] <= @UpperBound;
CREATE TABLE dbo.OrderStatus
(
Id TINYINT NOT NULL,
StatusName NVARCHAR(20) NOT NULL,
CONSTRAINT PK_OrderStatus_Id
PRIMARY KEY CLUSTERED (Id),
);
CREATE TABLE dbo.Orders
(
Id INT IDENTITY(1, 1) NOT NULL,
Amount DECIMAL(36, 2) NOT NULL,
OrderStatus TINYINT NOT NULL,
[Description] NVARCHAR(250) NULL,
SalesDate DATE NULL,
IsDeleted BIT NOT NULL
DEFAULT 0,
CONSTRAINT PK_Orders_Id
PRIMARY KEY CLUSTERED (Id),
CONSTRAINT FK_OrderStatus_Id FOREIGN KEY (OrderStatus)
REFERENCES dbo.OrderStatus (Id)
);
INSERT INTO dbo.OrderStatus
(
Id,
StatusName
)
VALUES
(1, 'New'),
(2, 'Complete'),
(3, 'Open');
DECLARE @StartDate AS DATE;
DECLARE @EndDate AS DATE;
DECLARE @DaysBetween AS INT;
SELECT @StartDate = '01/01/2020',
@EndDate = '12/31/2022',
@DaysBetween = (1 + DATEDIFF(DAY, @StartDate, @EndDate));
INSERT INTO dbo.Orders
(
Amount,
OrderStatus,
[Description],
SalesDate,
IsDeleted
)
SELECT TOP (5000000)
(ABS(CHECKSUM(NEWID()) % 1000) + 1) AS Amount,
CASE
WHEN (n.Number % 1000) = 0 THEN
3
WHEN (n.Number % 1500) = 0 THEN
1
ELSE
2
END AS OrderStatus,
'Gentlemen, you cannot fight in here. This is the war room.' AS [Description],
CASE
WHEN (n.Number % 150) = 0 THEN
DATEADD(DAY, RAND(CHECKSUM(NEWID())) * 90, DATEADD(YEAR, 3, @StartDate))
ELSE
DATEADD(DAY, RAND(CHECKSUM(NEWID())) * @DaysBetween, @StartDate)
END AS SalesDate,
CASE
WHEN (n.Number % 500) = 0 THEN
0
ELSE
1
END AS ISDeleted
FROM dbo.Numbers n;
GO
With the syntax above, we're creating two tables, Orders and OrderStatus. The latter table only has three values. We'll have five million rows in our Orders table, but less than 10,000 have the value of 3 or 1, said another way in the Open or New status. A good use case for filtered indexes is using them with a smaller subset of a table frequently accessed. To borrow an Azure storage term, hot data.
Suppose the business runs the following query millions of times a day. Given that less than 10,000 rows out of five million are Open or New, a filtered index would be a welcomed addition.
SELECT o.Id,
o.[Description],
o.SalesDate,
os.StatusName
FROM dbo.Orders o
INNER JOIN dbo.OrderStatus os
ON os.Id = o.OrderStatus
WHERE os.StatusName IN ('Open','New');
Creating a SQL Server Filtered Index
Since we identified a situation where a filtered index might come in handy, let's create it.
CREATE NONCLUSTERED INDEX [IXF_Orders_Status] -- Index Name
ON dbo.Orders (OrderStatus)
INCLUDE (
SalesDate,
[Description]
) -- Included Columns
WHERE OrderStatus IN ( 1, 3 );
Surely it can't be that easy to create one. The truth is that it is. Now let's turn on the actual execution plan and rerun our query to see which index SQL chooses.
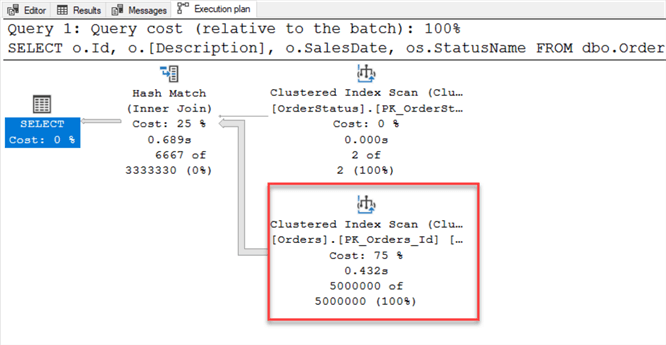
SQL Server skipped our filtered index and went with the clustered index in the SELECT statement. What if we try and force it?
SELECT o.Id,
o.[Description],
o.SalesDate,
os.StatusName
FROM dbo.Orders o WITH(INDEX(IXF_Orders_Status))
INNER JOIN dbo.OrderStatus os -- JOIN clause
ON os.Id = o.OrderStatus
WHERE os.StatusName IN ('Open','New');

From the error message above, my hint didn't work. Come on, SQL Server, why didn't you use the filtered index? Before going on, do you know why SQL chose the clustered index?
Use the Right Filter Criteria on a Multi Table SQL JOIN
If you look again at our original SQL query, you might notice something. I'm not filtering on the same criteria outlined when we created the index. Above I'm filtering the StatusName column in the OrderStatus table. SQL Server would be able to handle this in a perfect world, but we don't live in a perfect world. This difference may have been obvious to you, but it wasn't to me initially. It's like when I can't figure out why a query doesn't return the correct results until I notice I'm joining on the wrong columns.
We'll need to rewrite the query to encourage the optimizer to pick the filtered index. Either of the versions below does the trick. The bottom line is that you need to filter on the table with the filtered index.
SELECT o.Id,
o.[Description],
o.SalesDate,
os.StatusName
FROM dbo.Orders o
INNER JOIN dbo.OrderStatus os -- JOIN multiple tables
ON os.Id = o.OrderStatus
AND o.OrderStatus IN ( 1, 3 );
SELECT o.Id,
o.[Description],
o.SalesDate,
os.StatusName
FROM dbo.Orders o
INNER JOIN dbo.OrderStatus os
ON os.Id = o.OrderStatus
WHERE o.OrderStatus IN ( 1, 3 );

You can see from the screenshot above that the optimizer made a wise choice and picked the filtered index this time. To understand why SQL Server couldn't choose the filtered index in the original query, Paul White has an incredible four-part series on the query optimizer and the logical input tree.
Conclusion
Filtered indexes can speed up queries and reduce overall index size when working with large tables. What's large? It's subjective, but I don't bother with them for tables under one million rows. Plus, ensure you filter out a large percentage of the total rows in the table. They're not the first thing I think of when tuning queries, but they are an excellent tool when the situation arises. However, as mentioned above, they come with several limitations. I want to hear about your experiences with filtered indexes in the comments. Do you have any in your production environment?
Next Steps
- Would you like to learn more about filtered indexes? Eric Blinn wrote an informative article on specific use cases for implementing them.
- An issue you can experience with filtered indexes is the UnMatchedIndexes message. Ahmad Yaseen covers steps you can take to overcome it.
- Aaron Bertrand wrote an article titled, How Forced Parameterization in SQL Server Affects Filtered Indexes. If you're thinking about using forced parameterizations with filtered indexes, please give it a read.
- Learn more about the types of JOINs, INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, SELF JOIN and all related tips.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-01-23
