By: Jared Westover | Updated: 2023-06-08 | Comments (6) | Related: > Database Design
Problem
I've heard SQL Server described as an application that's a foot wide and a mile deep. I think you could make the argument that it's 10 miles deep. There are a few essential items any data engineer should know. For instance, did you know there are two storage modes for records in SQL Server? If you're going in for an interview or designing the database architecture of your next application, don't be left in the dark. As Warren Buffett said, "The more you learn, the more you earn."
Solution
In this tutorial, we'll look at the two storage modes for records on data pages. We'll start by exploring each mode in detail, then look at various situations when you would want to choose one over the other. By the end of this tip, you'll be on your way to making better database design conclusions today.
Two Storage Modes in SQL Server
With SQL Server, you often hear storage modes referring to storing data in a heap or a clustered index. I'm referring to how SQL Server stores records on pages in this tutorial. From that perspective, the two storage modes are rowstore and columnstore, and the latter is sometimes called columnar.
Knowing the Differences
Why is it important to know the difference between them? At least having a base understanding allows you to pick the best one for your table and database workload. Additionally, it's good to know if you're a consultant or vying for a data engineering role. Let's start by exploring each mode in more detail.
Exploring Rowstore
The most common type of record storage is rowstore. It's your traditional method where SQL stores rows or records on an 8kb data page. Microsoft defines a rowstore as logically organized data as a table with rows and columns and physically stored in a row-wise data format. I don't know if the term rowstore existed before columnstore, at least in the SQL Server world. Below I've included a simple illustration of how SQL Server stores records in the traditional rowstore manner. Let's say we want to create a table containing the values below.
| Id | First Name | Last Name | Sales Date | Sales Amount |
|---|---|---|---|---|
| 1 | Kamala | Khan | 04-05-2023 | $100 |
| 2 | John | Stewart | 04-05-2023 | $100 |
| 3 | Luke | Cage | 04-15-2023 | $300 |
| 4 | Kate | Kane | 04-15-2023 | $300 |
The T-SQL syntax to create and populate the table in a SQL database would look like this:
CREATE TABLE dbo.Sales
(
Id INT NOT NULL,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
SalesDate DATE NOT NULL,
SalesAmount DECIMAL(10, 2) NOT NULL,
CONSTRAINT PK_Sales_Id
PRIMARY KEY CLUSTERED (Id)
);
GO
INSERT INTO dbo.Sales
(
Id,
FirstName,
LastName,
SalesDate,
SalesAmount
)
VALUES
(1, 'Kamala', 'Khan', '2023-04-05', 100.00),
(2, 'John', 'Stewart', '2023-04-05', 100.00),
(3, 'Luke', 'Cage', '2023-04-15', 300.00),
(4, 'Kate', 'Kane', '2023-04-15', 300.00);
How SQL Server stores the records on data pages might look like the illustration below. Hopefully, we can store more than one record on a page.

For SQL Server, rowstore was the only storage method until the release of 2012. For anyone well versed with columnstore, it was much later when it became stable. However, Microsoft started making fantastic improvements to columnstore, beginning with SQL Server 2016. The ability to have a nonclustered updatable columnstore index was the primary reason I wanted to upgrade, along with getting Query Store.
When to Use Rowstore Indexes
If your workload requires fast retrievals, inserts, updates, and deletes, rowstore is a sure bet. For example, you're using a traditional OLTP system dealing with customer orders. If customers place orders on a website, only a handful of transactions will likely happen at a time. In this instance, rowstore is the best choice for query performance.
Table size is also an essential factor for consideration. When working with tables under a couple of million rows, I wouldn't have even considered using columnstore. You don't see any benefit when a table doesn't contain at least three to five million rows, in my experience.
Exploring SQL Server Columnstore Indexes
Now onto the less common storage mode, columnstore. It was first introduced in SQL Server 2012 with limited functionality. Microsoft defines columnstore as logically organized data as a table with rows and columns but physically stored in a column-wise data format. The clustered and nonclustered varieties are the two available options in SQL Server 2016 onward.
Using the same earlier table, below illustrates how SQL Server stores rowgroups comprising about a million rows into compressed segments. Let's imagine our table consists of several million rows. For some columns, a lot of those values repeat. For example, you might have a million rows where the sales amount is $100.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCS_SalesAmount_SalesDate
ON dbo.Sales (
SalesAmount,
SalesDate
);
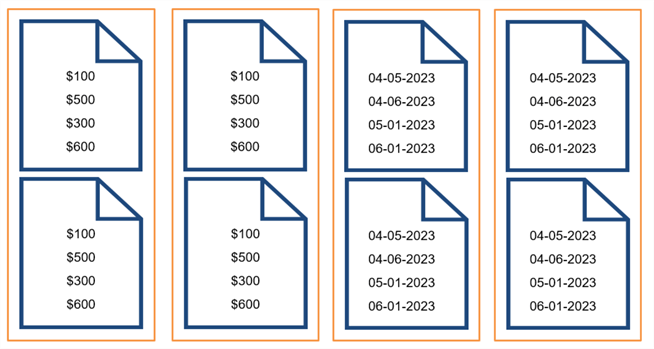
Columnstore has come a long way since its inception. Initially, you couldn't update a table with a columnstore index. A standard method people use for updating involves dropping or disabling the index, performing modifications, and then rebuilding it. Talk about a hassle. If you haven't looked at columnstore since its release, check out this Microsoft article on all the new features: What's new in columnstore indexes. By default, Azure Synapse uses clustered columnstore indexes as its table structure.
When to Use Columnstore
At its core, columnstore shines when it comes to performing analytics over many rows. Since the columns are stored individually, you can gain significant performance because of the advanced compression methods. When you think about it, an integer column that's part of a table with a billion rows might only have ten thousand or so unique values. Imagine fitting all that data in cache and performing some aggregations on it.
Choosing One
So which storage method should you choose? We can answer the question by saying, "It depends." However, only saying it depends isn't good enough. You need to understand what the answer depends on. For most databases and tables in a typical transaction environment, you'll want to stick with rowstore. Even with rowstore, you can apply row and page compression, dramatically improving performance on larger tables.
If you have a data warehousing need or a mix of the two environments, consider columnstore. If your table had under two million rows, columnstore wouldn't be in my purview. I've mistakenly applied columnstore to tables under a few million rows and saw no benefits, just added overhead. However, the performance boost can be mind-blowing when a table is a good fit for columnstore.
Key Points
- The two methods of storing records on a data page are rowstore and columnstore, sometimes called columnar.
- Microsoft first introduced columnstore in SQL Server 2012, but made massive improvements by 2016, including the ability to add a nonclustered columnstore index on top of a rowstore table.
- Rowstore is a traditional storage method and works well for most transactional databases.
- Columnstore works well when tables contain more than three million rows i.e. large tables. Think of a hybrid transaction environment where real-time analytics are critical and performance gains are needed.
- Rule of thumb: If your table has under three million rows, skip columnstore altogether. Give it time because tables only seem to keep growing.
Next Steps
- Do you have a large static table you can't delete or trim down? Please check out my tutorial: Compressing Big Static SQL Server Tables.
- For a detailed overview of clustered and nonclustered columnstore indexes, please check out this tutorial by Jayendra Viswanathan: SQL Server Clustered and Nonclustered Columnstore Index Example.
- Want a listing of all the features of columnstore by the version of SQL Server? Check out this document on the Microsoft Learn website: What's new in columnstore indexes.






About the author
 Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.
Jared Westover is a passionate technology specialist at Crowe, helping to build data solutions. For the past two decades, he has focused on SQL Server, Azure, Power BI, and Oracle. Besides writing for MSSQLTips.com, he has published 12 Pluralsight courses about SQL Server and Reporting Services. Jared enjoys reading and spending time with his wife and three sons when he's not trying to make queries go faster.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-06-08
