By: Andrea Gnemmi | Updated: 2023-07-11 | Comments (2) | Related: > PostgreSQL
Problem
You probably know that SQL Server caches execution plans of queries to reuse them when the same query is performed again. This improves performance as the optimizer does not have to recalculate the plan each time, this only happens when the query or query parameters change (very simplified explanation).
In PostgreSQL, query plans are not cached except for functions and procedures, so the optimizer must recalculate the plan each time. There is another way to cache queries and plans, although with some limitations: prepared statements.
Solution
In PostgreSQL, a Prepared Statement is a handy way to achieve better performance on extensively used queries, in practice avoiding the parse analysis step while allowing the execution plan to depend on the specific parameter values supplied. In this tip, we will review the syntax, the various features available, and the limitations of this technique.
First, a quick introduction to the steps used by PostgreSQL to process a query statement:
- Parse Phase
- Check syntax
- Call traffic cop
- Identify query type
- Command processor (if needed)
- Break query in tokens
- Optimize Phase (when the execution plan is generated and
chosen based on database statistics)
- Planner generates plan
- Query cost calculation
- Choose the best plan
- Execute (when query is run and results returned)
- Execute query (based on query plan)
As you can see, the first part is all about parsing the query statement, and only after that will the optimizer start generating the plan based on the statistics of the tables involved in the query. Obviously, the execution is the last step!
So how will the Prepare Statement help us improve the performance of the selected query? And does it also cache the best plan for the query in some way or avoid the parse phase?
Let's do a quick test using a large table.
First, let's create it:
create table if not exists test_prepare (idtest bigint, description varchar(50) );
Then let's start to fill it:
insert into test_prepare values (generate_series(1,100000), 'Test prepare');
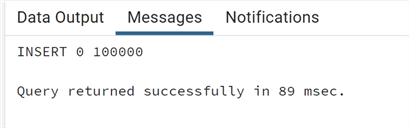
And we can manipulate some of the rows:
--MSSQLTips.com update test_prepare set descrizione='test_prepare 23' where (idtest % 2) = 0;

Note concerning two parts of the code used:
- The generate_series() function is very handy in generating a series of data (numbers, dates, etc.).
- The operator % that returns the rest of the division, used in conjunction with the number 2 and where = 0, it filters all even numbers.
Now we can do a simple query on this table to retrieve all newly updated rows, and we can check the plan generated using the explain analyze option (in this case, directly from the pgAdmin GUI):
--MSSQLTips.com select idtest, description from test_prepare where description='test_prepare 23' order by idtest;

A pretty simple plan with a sequential table scan as we do not have any index on the table and a sort due to the order by.
Let's mess around with the data a little bit more to have some statistics and more rows in the table:
--MSSQLTips.com update test_prepare set descrizione='test prepare' where (idtest % 3) = 0; insert into test_prepare values (generate_series(100000,500000), 'Test prova');

And now, we can finally create an index on this table:
--MSSQLTips.com
CREATE INDEX idx_test_prepare
ON public.test_prepare USING btree
(description ASC NULLS LAST)
INCLUDE(idtest);

Now let's take a look at the statistics, in particular on the column description, using the system table pg_stats that contains all the info on the table's statistics used by the optimizer:
--MSSQLTips.com SELECT attname, avg_width, n_distinct, most_common_vals, most_common_freqs FROM pg_stats WWHERE tablename = 'test_prepare' AND attname = 'description';

You can see that we have four distinct values with an uneven distribution. We can try to see what execution plan gets our previous query:
--MSSQLTips.com select idtest, description from test_prepare where description='test_prepare 23' order by idtest;

As expected, it is now using the index as the query filters out the major part of the rows.
After this preliminary phase, in which we have taken a look at the data distributions and the execution plans of our query, we can finally try the prepared statement:
--MSSQLTips.com
PREPARE piano_test(text) AS
select idtest, description
from test_prepare
where description=$1
order by idtest;

The syntax is quite simple. We declare the query giving it a name and a parameter type, and put the parameter in the where clause.
We can now check in system table pg_prepared_statements the statement that has been recorded:
--MSSQLTips.com select * from pg_prepared_statements;

A few words on the meaning of the various columns:
- The first three are self-explanatory
- The parameter_types indicates the data type of the parameter(s)
- from_sql tells us if it's a prepared statement created on a SQL transaction or coming from a Java application
- The last two indicate the number of generic or custom plans used by this prepared statement. More on that later.
Now we can call the Prepared Statement (just like a procedure) with the parameter declared as $1 in the PREPARED statement using the Explain Analysis like before to check the actual execution plan:
execute piano_test('Test prova');

As you can see, using the where parameter as the most present value makes the optimizer choose a sequential scan, as the number of rows filtered out is only a small portion of the table; thus, using the index is counterproductive. On the other end, if we call the prepared statement with another parameter:
execute piano_test('test_prepare 23');

We can see that the optimizer again chooses the plan using the index and makes an Index Scan Only since it can obtain all data within the index. (Remember that we also included the column idtest in the index).
This is the default behavior of PostgreSQL. We leave the choice to the optimizer to determine the best plan on PREPARED statements. However, we can modify it using the parameter plan_cache_mode, thus forcing the optimizer to always choose a generic or a custom one. Let's try it. First, we deallocate our prepared statement so that we'll have another fresh one using the DEALLOCATE statement:
deallocate piano_test;
Checking the pg_prepared_statements table, we can see that the Prepared Statement is no longer present:
select * from pg_prepared_statements;

Now we can set the parameter for the actual session:
SET plan_cache_mode = 'force_generic_plan';
And add a new prepared statement:
--MSSQLTips.com
PREPARE nuovopiano_test(text) AS
select idtest, description
from test_prepare
where description=$1
order by idtest;
Let's check the pg_prepared_statements table again:

We see the newly prepared statement with no plans used so far. Now let's call it like before:
execute nuovopiano_test('Test prova');

Instead of the expected sequential scan, we have an Index Only Scan as the generic plan for this Prepared Statement is this one and not the one with sequential scan. In this case, we are using a cached plan! We can also call with the other parameter and recheck the plan:
execute nuovopiano_test('test_prepare 23');

And as expected, we have the same plan.
Let's try the opposite now, forcing the use of a custom plan instead of a generic one:
SET plan_cache_mode = 'force_custom_plan';
execute nuovopiano_test('Test prova');

Again, we have the sequential scan plan now calling with the other parameter:
execute nuovopiano_test('test_prepare 23');

Again, we have the correct custom plan with the Index Only Scan. Remember that the default is:
SET plan_cache_mode = 'auto'; --PostgreSQL default
Thus, letting the optimizer do its job and choose the best plan at the cost of having to do some work. Can we quantify the actual time and resources that we save or use for each of these options?
Let's try to measure the times needed by each query.
First, here is the normal query without calling the PREPARED statement:
--MSSQLTips.com select idtest, description from test_prepare where description='test_prepare 23' order by idtest;

Checking that it used the index, we issue an Explain Analysis with a couple of parameters to show the times of each step:
--MSSQLTips.com explain (analyze on, timing on, format json) select idtest, description from test_prepare where description='test_prepare 23' order by idtest;

We can see that most of the 120 msec are taken by the parse and optimize phase, as the execution of the query itself takes just 7 msec! Note: I have subsequently re-run this query, also obtaining longer times. Below is one of the fastest that I got.
Now we can try the PREPARED statement with the same parameter:
execute nuovopiano_test('test_prepare 23');


We see similar times on the plan execution itself, but quite a difference in the total elapsed time that justifies an advantage in the PREPARED statements, especially when the query itself is not huge and thus the parsing time is significant.
Let's now try to force the use of the generic plan as before:
SET plan_cache_mode = 'force_generic_plan';
And call the prepared statement again:
execute nuovopiano_test('test_prepare 23');
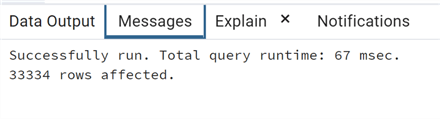

The execution takes almost the same time, but the total elapsed time is even better. This is expected since we are using a generic cached plan.
Limitations
So far, we've seen the performance advantages of using a PREPARED statement. A significant limitation is that the statement remains in memory only for the duration of the session, as explained in the documentation:
"Prepared statements only last for the duration of the current database session. When the session ends, the prepared statement is forgotten, so it must be recreated before being used again. This also means that a single prepared statement cannot be used by multiple simultaneous database clients; however, each client can create their own prepared statement to use."
This makes Prepared Statements useful if a single session executes similar statements over and over again, especially if the statements are complex. Performance differences can be significant if the statements are complex, but not as useful if the statements are relatively simple.
Conclusion
In this tip, we have reviewed the concept of PostgreSQL Prepared statements, showing advantages and limitations, syntax and options, and the system table used for monitoring it.
Next Steps
- PostgreSQL official documentation
- SQL Server 2019 Execution Plan Enhancements
- Using a SQL Server Explain Plan to View Cached Query Plan Parameters in Management Studio






About the author
 Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-07-11
